 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Implicit Multimodal Knowledge into LLMs for Zero-Resource Dialogue Generation
May 16, 2024Integrating multimodal knowledge into large language models (LLMs) represents a significant advancement in dialogue generation capabilities. However, the effective incorporation of such knowledge in zero-resource scenarios remains a substantial challenge due to the scarcity of diverse, high-quality dialogue datasets. To address this, we propose the Visual Implicit Knowledge Distillation Framework (VIKDF), an innovative approach aimed at enhancing LLMs for enriched dialogue generation in zero-resource contexts by leveraging implicit multimodal knowledge. VIKDF comprises two main stages: knowledge distillation, using an Implicit Query Transformer to extract and encode visual implicit knowledge from image-text pairs into knowledge vectors; and knowledge integration, employing a novel Bidirectional Variational Information Fusion technique to seamlessly integrate these distilled vectors into LLMs. This enables the LLMs to generate dialogues that are not only coherent and engaging but also exhibit a deep understanding of the context through implicit multimodal cues, effectively overcoming the limitations of zero-resource scenarios. Our extensive experimentation across two dialogue datasets shows that VIKDF outperforms existing state-of-the-art models in generating high-quality dialogues. The code will be publicly available following acceptance.
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
May 03, 2024Facial Expression Recognition (FER) plays a pivotal role in understanding human emotional cues. However, traditional FER methods based on visual information have some limitations, such as preprocessing, feature extraction, and multi-stage classification procedures. These not only increase computational complexity but also require a significant amount of computing resources. Considering Convolutional Neural Network (CNN)-based FER schemes frequently prove inadequate in identifying the deep, long-distance dependencies embedded within facial expression images, and the Transformer's inherent quadratic computational complexity, this paper presents the FER-YOLO-Mamba model, which integrates the principles of Mamba and YOLO technologies to facilitate efficient coordination in facial expression image recognition and localization. Within the FER-YOLO-Mamba model, we further devise a FER-YOLO-VSS dual-branch module, which combines the inherent strengths of convolutional layers in local feature extraction with the exceptional capability of State Space Models (SSMs) in revealing long-distance dependencies. To the best of our knowledge, this is the first Vision Mamba model designed for facial expression detection and classification. To evaluate the performance of the proposed FER-YOLO-Mamba model, we conducted experiments on two benchmark datasets, RAF-DB and SFEW. The experimental results indicate that the FER-YOLO-Mamba model achieved better results compared to other models. The code is available from https://github.com/SwjtuMa/FER-YOLO-Mamba.
Joint Physical-Digital Facial Attack Detection Via Simulating Spoofing Clues
Apr 12, 2024Face recognition systems are frequently subjected to a variety of physical and digital attacks of different types. Previous methods have achieved satisfactory performance in scenarios that address physical attacks and digital attacks, respectively. However, few methods are considered to integrate a model that simultaneously addresses both physical and digital attacks, implying the necessity to develop and maintain multiple models. To jointly detect physical and digital attacks within a single model, we propose an innovative approach that can adapt to any network architecture. Our approach mainly contains two types of data augmentation, which we call Simulated Physical Spoofing Clues augmentation (SPSC) and Simulated Digital Spoofing Clues augmentation (SDSC). SPSC and SDSC augment live samples into simulated attack samples by simulating spoofing clues of physical and digital attacks, respectively, which significantly improve the capability of the model to detect "unseen" attack types. Extensive experiments show that SPSC and SDSC can achieve state-of-the-art generalization in Protocols 2.1 and 2.2 of the UniAttackData dataset, respectively. Our method won first place in "Unified Physical-Digital Face Attack Detection" of the 5th Face Anti-spoofing Challenge@CVPR2024. Our final submission obtains 3.75% APCER, 0.93% BPCER, and 2.34% ACER, respectively. Our code is available at https://github.com/Xianhua-He/cvpr2024-face-anti-spoofing-challenge.
From Pixel to Slide image: Polarization Modality-based Pathological Diagnosis Using Representation Learning
Jan 03, 2024Thyroid cancer is the most common endocrine malignancy, and accurately distinguishing between benign and malignant thyroid tumors is crucial for developing effective treatment plans in clinical practice. Pathologically, thyroid tumors pose diagnostic challenges due to improper specimen sampling. In this study, we have designed a three-stage model using representation learning to integrate pixel-level and slice-level annotations for distinguishing thyroid tumors. This structure includes a pathology structure recognition method to predict structures related to thyroid tumors, an encoder-decoder network to extract pixel-level annotation information by learning the feature representations of image blocks, and an attention-based learning mechanism for the final classification task. This mechanism learns the importance of different image blocks in a pathological region, globally considering the information from each block. In the third stage, all information from the image blocks in a region is aggregated using attention mechanisms, followed by classification to determine the category of the region. Experimental results demonstrate that our proposed method can predict microscopic structures more accurately. After color-coding, the method achieves results on unstained pathology slides that approximate the quality of Hematoxylin and eosin staining, reducing the need for stained pathology slides. Furthermore, by leveraging the concept of indirect measurement and extracting polarized features from structures correlated with lesions, the proposed method can also classify samples where membrane structures cannot be obtained through sampling, providing a potential objective and highly accurate indirect diagnostic technique for thyroid tumors.
A Polarization and Radiomics Feature Fusion Network for the Classification of Hepatocellular Carcinoma and Intrahepatic Cholangiocarcinoma
Dec 27, 2023Classifying hepatocellular carcinoma (HCC) and intrahepatic cholangiocarcinoma (ICC) is a critical step in treatment selection and prognosis evaluation for patients with liver diseases. Traditional histopathological diagnosis poses challenges in this context. In this study, we introduce a novel polarization and radiomics feature fusion network, which combines polarization features obtained from Mueller matrix images of liver pathological samples with radiomics features derived from corresponding pathological images to classify HCC and ICC. Our fusion network integrates a two-tier fusion approach, comprising early feature-level fusion and late classification-level fusion. By harnessing the strengths of polarization imaging techniques and image feature-based machine learning, our proposed fusion network significantly enhances classification accuracy. Notably, even at reduced imaging resolutions, the fusion network maintains robust performance due to the additional information provided by polarization features, which may not align with human visual perception. Our experimental results underscore the potential of this fusion network as a powerful tool for computer-aided diagnosis of HCC and ICC, showcasing the benefits and prospects of integrating polarization imaging techniques into the current image-intensive digital pathological diagnosis. We aim to contribute this innovative approach to top-tier journals, offering fresh insights and valuable tools in the fields of medical imaging and cancer diagnosis. By introducing polarization imaging into liver cancer classification, we demonstrate its interdisciplinary potential in addressing challenges in medical image analysis, promising advancements in medical imaging and cancer diagnosis.
A Transformer-Based Model With Self-Distillation for Multimodal Emotion Recognition in Conversations
Oct 31, 2023Emotion recognition in conversations (ERC), the task of recognizing the emotion of each utterance in a conversation, is crucial for building empathetic machines. Existing studies focus mainly on capturing context- and speaker-sensitive dependencies on the textual modality but ignore the significance of multimodal information. Different from emotion recognition in textual conversations, capturing intra- and inter-modal interactions between utterances, learning weights between different modalities, and enhancing modal representations play important roles in multimodal ERC. In this paper, we propose a transformer-based model with self-distillation (SDT) for the task. The transformer-based model captures intra- and inter-modal interactions by utilizing intra- and inter-modal transformers, and learns weights between modalities dynamically by designing a hierarchical gated fusion strategy. Furthermore, to learn more expressive modal representations, we treat soft labels of the proposed model as extra training supervision. Specifically, we introduce self-distillation to transfer knowledge of hard and soft labels from the proposed model to each modality. Experiments on IEMOCAP and MELD datasets demonstrate that SDT outperforms previous state-of-the-art baselines.
* 13 pages, 10 figures. Accepted by IEEE Transactions on Multimedia (TMM)
Learning to Solve Climate Sensor Placement Problems with a Transformer
Oct 18, 2023



The optimal placement of sensors for environmental monitoring and disaster management is a challenging problem due to its NP-hard nature. Traditional methods for sensor placement involve exact, approximation, or heuristic approaches, with the latter being the most widely used. However, heuristic methods are limited by expert intuition and experience. Deep learning (DL) has emerged as a promising approach for generating heuristic algorithms automatically. In this paper, we introduce a novel sensor placement approach focused on learning improvement heuristics using deep reinforcement learning (RL) methods. Our approach leverages an RL formulation for learning improvement heuristics, driven by an actor-critic algorithm for training the policy network. We compare our method with several state-of-the-art approaches by conducting comprehensive experiments, demonstrating the effectiveness and superiority of our proposed approach in producing high-quality solutions. Our work presents a promising direction for applying advanced DL and RL techniques to challenging climate sensor placement problems.
ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation
Aug 02, 2023
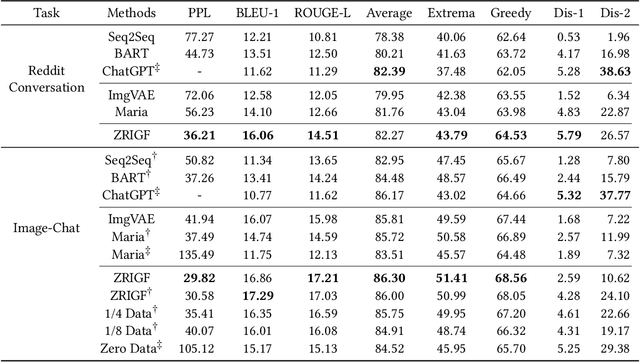


Image-grounded dialogue systems benefit greatly from integrating visual information, resulting in high-quality response generation. However, current models struggle to effectively utilize such information in zero-resource scenarios, mainly due to the disparity between image and text modalities. To overcome this challenge, we propose an innovative multimodal framework, called ZRIGF, which assimilates image-grounded information for dialogue generation in zero-resource situations. ZRIGF implements a two-stage learning strategy, comprising contrastive pre-training and generative pre-training. Contrastive pre-training includes a text-image matching module that maps images and texts into a unified encoded vector space, along with a text-assisted masked image modeling module that preserves pre-training visual features and fosters further multimodal feature alignment. Generative pre-training employs a multimodal fusion module and an information transfer module to produce insightful responses based on harmonized multimodal representations. Comprehensive experiments conducted on both text-based and image-grounded dialogue datasets demonstrate ZRIGF's efficacy in generating contextually pertinent and informative responses. Furthermore, we adopt a fully zero-resource scenario in the image-grounded dialogue dataset to demonstrate our framework's robust generalization capabilities in novel domains. The code is available at https://github.com/zhangbo-nlp/ZRIGF.
DeepMA: End-to-end Deep Multiple Access for Wireless Image Transmission in Semantic Communication
Mar 21, 2023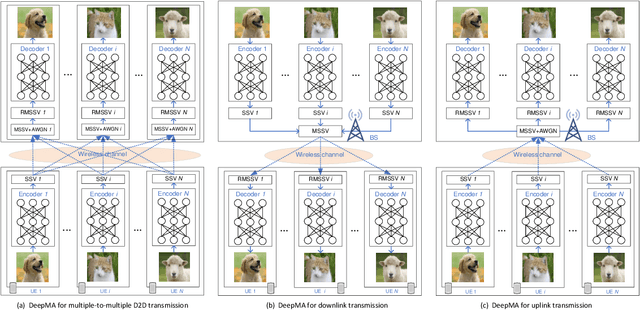
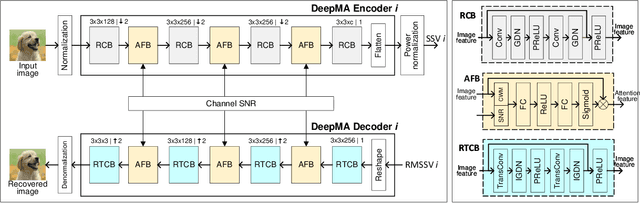

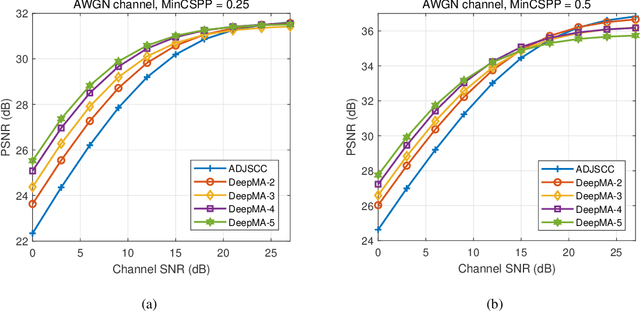
Semantic communication is a new paradigm that exploits deep learning models to enable end-to-end communications processes, and recent studies have shown that it can achieve better noise resiliency compared with traditional communication schemes in a low signal-to-noise (SNR) regime. To achieve multiple access in semantic communication, we propose a deep learning-based multiple access (DeepMA) method by training semantic communication models with the abilities of joint source-channel coding (JSCC) and orthogonal signal modulation. DeepMA is achieved by a DeepMA network (DMANet), which is comprised of several independent encoder-decoder pairs (EDPs), and the DeepMA encoders can encode the input data as mutually orthogonal semantic symbol vectors (SSVs) such that the DeepMA decoders can recover their own target data from a received mixed SSV (MSSV) superposed by multiple SSV components transmitted from different encoders. We describe frameworks of DeepMA in wireless device-to-device (D2D), downlink, and uplink channel multiplexing scenarios, along with the training algorithm. We evaluate the performance of the proposed DeepMA in wireless image transmission tasks and compare its performance with the attention module-based deep JSCC (ADJSCC) method and conventional communication schemes using better portable graphics (BPG) and Low-density parity-check code (LDPC). The results obtained show that the proposed DeepMA can achieve effective, flexible, and privacy-preserving channel multiplexing process, and demonstrate that our proposed DeepMA approach can yield comparable bandwidth efficiency compared with conventional multiple access schemes.
Memetic EDA-Based Approaches to Comprehensive Quality-Aware Automated Semantic Web Service Composition
Jun 19, 2019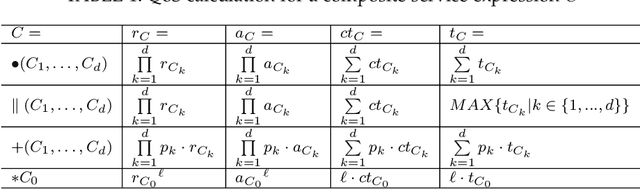
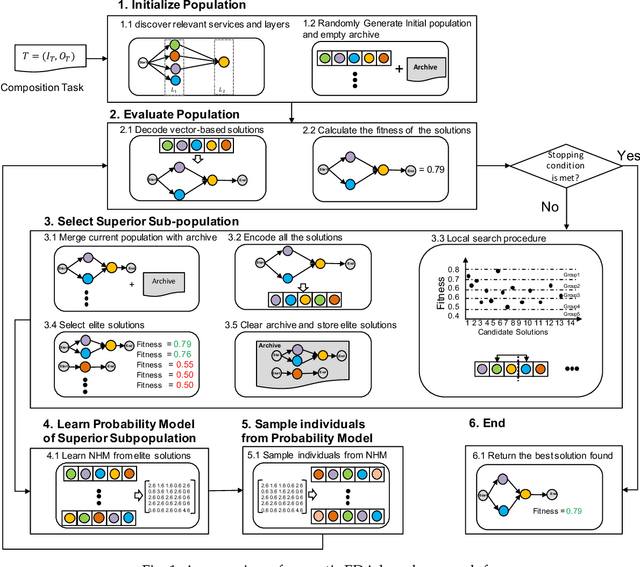
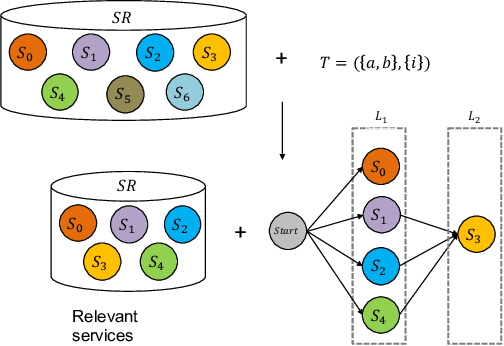
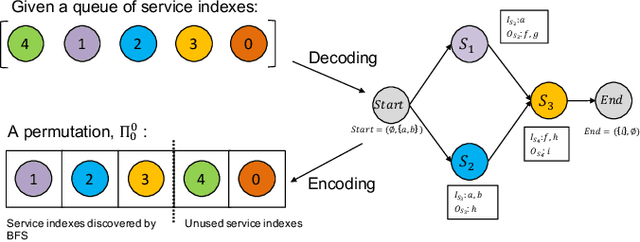
Comprehensive quality-aware automated semantic web service composition is an NP-hard problem, where service composition workflows are unknown, and comprehensive quality, i.e., Quality of services (QoS) and Quality of semantic matchmaking (QoSM) are simultaneously optimized. The objective of this problem is to find a solution with optimized or near-optimized overall QoS and QoSM within polynomial time over a service request. In this paper, we proposed novel memetic EDA-based approaches to tackle this problem. The proposed method investigates the effectiveness of several neighborhood structures of composite services by proposing domain-dependent local search operators. Apart from that, a joint strategy of the local search procedure is proposed to integrate with a modified EDA to reduce the overall computation time of our memetic approach. To better demonstrate the effectiveness and scalability of our approach, we create a more challenging, augmented version of the service composition benchmark based on WSC-08 \cite{bansal2008wsc} and WSC-09 \cite{kona2009wsc}. Experimental results on this benchmark show that one of our proposed memetic EDA-based approach (i.e., MEEDA-LOP) significantly outperforms existing state-of-the-art algorithms.