 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
Jun 07, 2024Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Jun 04, 2024Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Rethinking Robustness Assessment: Adversarial Attacks on Learning-based Quadrupedal Locomotion Controllers
May 21, 2024Legged locomotion has recently achieved remarkable success with the progress of machine learning techniques, especially deep reinforcement learning (RL). Controllers employing neural networks have demonstrated empirical and qualitative robustness against real-world uncertainties, including sensor noise and external perturbations. However, formally investigating the vulnerabilities of these locomotion controllers remains a challenge. This difficulty arises from the requirement to pinpoint vulnerabilities across a long-tailed distribution within a high-dimensional, temporally sequential space. As a first step towards quantitative verification, we propose a computational method that leverages sequential adversarial attacks to identify weaknesses in learned locomotion controllers. Our research demonstrates that, even state-of-the-art robust controllers can fail significantly under well-designed, low-magnitude adversarial sequence. Through experiments in simulation and on the real robot, we validate our approach's effectiveness, and we illustrate how the results it generates can be used to robustify the original policy and offer valuable insights into the safety of these black-box policies.
Goal-guided Generative Prompt Injection Attack on Large Language Models
Apr 06, 2024



Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Knowledge Graph Large Language Model (KG-LLM) for Link Prediction
Mar 19, 2024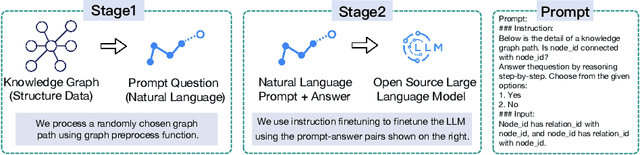
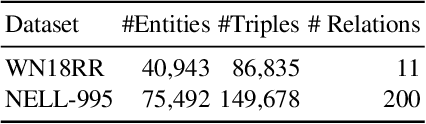
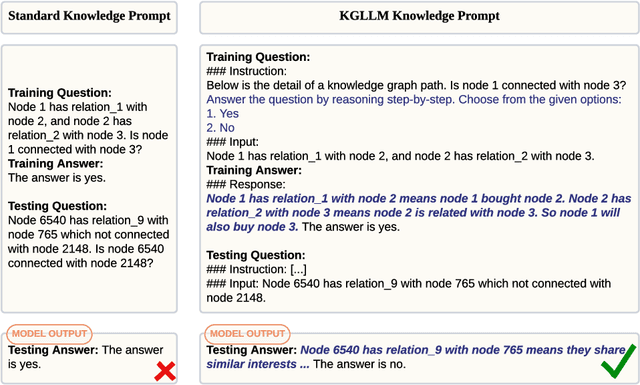
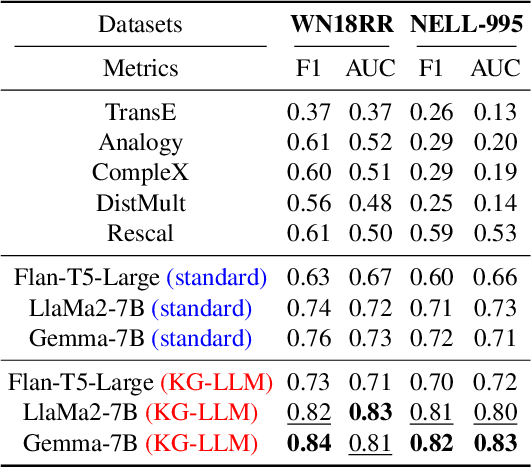
The task of predicting multiple links within knowledge graphs (KGs) stands as a challenge in the field of knowledge graph analysis, a challenge increasingly resolvable due to advancements in natural language processing (NLP) and KG embedding techniques. This paper introduces a novel methodology, the Knowledge Graph Large Language Model Framework (KG-LLM), which leverages pivotal NLP paradigms, including chain-of-thought (CoT) prompting and in-context learning (ICL), to enhance multi-hop link prediction in KGs. By converting the KG to a CoT prompt, our framework is designed to discern and learn the latent representations of entities and their interrelations. To show the efficacy of the KG-LLM Framework, we fine-tune three leading Large Language Models (LLMs) within this framework, employing both non-ICL and ICL tasks for a comprehensive evaluation. Further, we explore the framework's potential to provide LLMs with zero-shot capabilities for handling previously unseen prompts. Our experimental findings discover that integrating ICL and CoT not only augments the performance of our approach but also significantly boosts the models' generalization capacity, thereby ensuring more precise predictions in unfamiliar scenarios.
Joint Group Scheduling and Multicast Beamforming for Downlink Large-Scale Multi-Group Multicast
Mar 15, 2024



Next-generation wireless networks need to handle massive user access effectively. This paper addresses the problem of joint group scheduling and multicast beamforming for downlink multicast with many active groups. Aiming to maximize the minimum user throughput, we propose a three-phase approach to tackle this difficult joint optimization problem efficiently. In Phase 1, we utilize the optimal multicast beamforming structure obtained recently to find the group-channel directions for all groups. We propose two low-complexity scheduling algorithms in Phase 2, which determine the subset of groups in each time slot sequentially and the total number of time slots required for all groups. The first algorithm measures the level of spatial separation among groups and selects the dissimilar groups that maximize the minimum user rate into the same time slot. In contrast, the second algorithm first identifies the spatially correlated groups via a learning-based clustering method based on the group-channel directions, and then separates spatially similar groups into different time slots. Finally, the multicast beamformers for the scheduled groups are obtained in each time slot by a computationally efficient method. Simulation results show that our proposed approaches can effectively capture the level of spatial separation among groups for scheduling to improve the minimum user throughput over the conventional approach that serves all groups in a single time slot or one group per time slot, and can be executed with low computational complexity.
Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation
Mar 07, 2024



We present Human to Humanoid (H2O), a reinforcement learning (RL) based framework that enables real-time whole-body teleoperation of a full-sized humanoid robot with only an RGB camera. To create a large-scale retargeted motion dataset of human movements for humanoid robots, we propose a scalable "sim-to-data" process to filter and pick feasible motions using a privileged motion imitator. Afterwards, we train a robust real-time humanoid motion imitator in simulation using these refined motions and transfer it to the real humanoid robot in a zero-shot manner. We successfully achieve teleoperation of dynamic whole-body motions in real-world scenarios, including walking, back jumping, kicking, turning, waving, pushing, boxing, etc. To the best of our knowledge, this is the first demonstration to achieve learning-based real-time whole-body humanoid teleoperation.
Towards Training A Chinese Large Language Model for Anesthesiology
Mar 05, 2024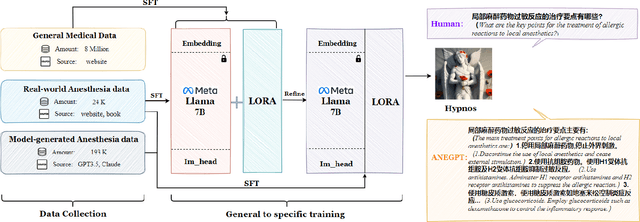
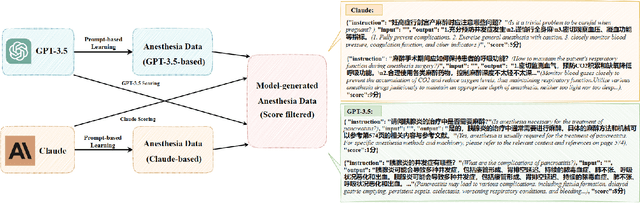
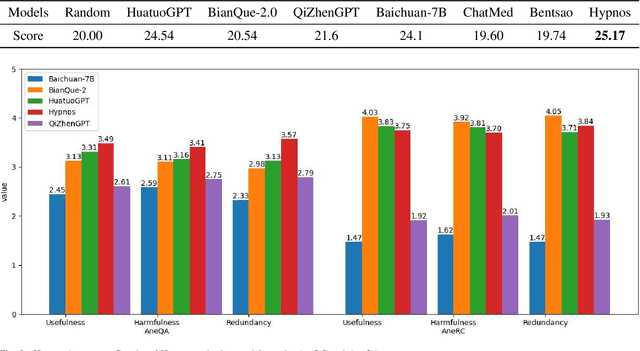
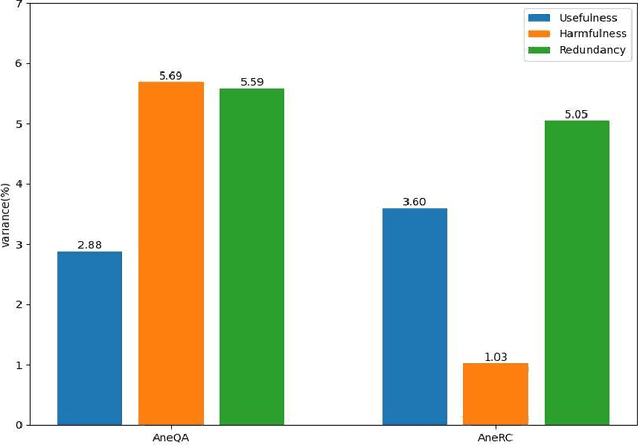
Medical large language models (LLMs) have gained popularity recently due to their significant practical utility. However, most existing research focuses on general medicine, and there is a need for in-depth study of LLMs in specific fields like anesthesiology. To fill the gap, we introduce Hypnos, a Chinese Anesthesia model built upon existing LLMs, e.g., Llama. Hypnos' contributions have three aspects: 1) The data, such as utilizing Self-Instruct, acquired from current LLMs likely includes inaccuracies. Hypnos implements a cross-filtering strategy to improve the data quality. This strategy involves using one LLM to assess the quality of the generated data from another LLM and filtering out the data with low quality. 2) Hypnos employs a general-to-specific training strategy that starts by fine-tuning LLMs using the general medicine data and subsequently improving the fine-tuned LLMs using data specifically from Anesthesiology. The general medical data supplement the medical expertise in Anesthesiology and enhance the effectiveness of Hypnos' generation. 3) We introduce a standardized benchmark for evaluating medical LLM in Anesthesiology. Our benchmark includes both publicly available instances from the Internet and privately obtained cases from the Hospital. Hypnos outperforms other medical LLMs in anesthesiology in metrics, GPT-4, and human evaluation on the benchmark dataset.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities
Feb 19, 2024



Large language models (LLMs) have been applied in many fields with rapid development in recent years. As a classic machine learning task, time series forecasting has recently received a boost from LLMs. However, there is a research gap in the LLMs' preferences in this field. In this paper, by comparing LLMs with traditional models, many properties of LLMs in time series prediction are found. For example, our study shows that LLMs excel in predicting time series with clear patterns and trends but face challenges with datasets lacking periodicity. We explain our findings through designing prompts to require LLMs to tell the period of the datasets. In addition, the input strategy is investigated, and it is found that incorporating external knowledge and adopting natural language paraphrases positively affects the predictive performance of LLMs for time series. Overall, this study contributes to insight into the advantages and limitations of LLMs in time series forecasting under different conditions.