 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Imperceptible Backdoor Attack in Self-supervised Learning
May 23, 2024Self-supervised learning models are vulnerable to backdoor attacks. Existing backdoor attacks that are effective in self-supervised learning often involve noticeable triggers, like colored patches, which are vulnerable to human inspection. In this paper, we propose an imperceptible and effective backdoor attack against self-supervised models. We first find that existing imperceptible triggers designed for supervised learning are not as effective in compromising self-supervised models. We then identify this ineffectiveness is attributed to the overlap in distributions between the backdoor and augmented samples used in self-supervised learning. Building on this insight, we design an attack using optimized triggers that are disentangled to the augmented transformation in the self-supervised learning, while also remaining imperceptible to human vision. Experiments on five datasets and seven SSL algorithms demonstrate our attack is highly effective and stealthy. It also has strong resistance to existing backdoor defenses. Our code can be found at https://github.com/Zhang-Henry/IMPERATIVE.
Neural Operator for Accelerating Coronal Magnetic Field Model
May 21, 2024Studying the sun's outer atmosphere is challenging due to its complex magnetic fields impacting solar activities. Magnetohydrodynamics (MHD) simulations help model these interactions but are extremely time-consuming (usually on a scale of days). Our research applies the Fourier Neural Operator (FNO) to accelerate the coronal magnetic field modeling, specifically, the Bifrost MHD model. We apply Tensorized FNO (TFNO) to generate solutions from partial differential equations (PDEs) over a 3D domain efficiently. TFNO's performance is compared with other deep learning methods, highlighting its accuracy and scalability. Physics analysis confirms that TFNO is reliable and capable of accelerating MHD simulations with high precision. This advancement improves efficiency in data handling, enhances predictive capabilities, and provides a better understanding of magnetic topologies.
Quantifying Multilingual Performance of Large Language Models Across Languages
Apr 17, 2024The training process of Large Language Models (LLMs) requires extensive text corpus. However, these data are often unevenly distributed in different languages. As a result, LLMs perform well on common languages, such as English, German, and French, but perform poorly on low-resource languages. However, currently there is no work to quantitatively measure the performance of LLMs in low-resource languages. To fill this gap, we proposed the Language Ranker that aims to benchmark and rank different languages according to the performance of LLMs on those languages. We employ the LLM's performance on the English corpus as a baseline to compare the performances of different languages and English. We have the following three findings: 1. The performance rankings of different LLMs in all languages are roughly the same. 2. LLMs with different sizes have the same partial order of performance. 3. There is a strong correlation between LlaMa2's performance in different languages and the proportion of the pre-training corpus. These findings illustrate that the Language Ranker can be used as an indicator to measure the language performance of LLMs.
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
Apr 10, 2024This paper studies the phenomenon that different concepts are learned in different layers of large language models, i.e. more difficult concepts are fully acquired with deeper layers. We define the difficulty of concepts by the level of abstraction, and here it is crudely categorized by factual, emotional, and inferential. Each category contains a spectrum of tasks, arranged from simple to complex. For example, within the factual dimension, tasks range from lie detection to categorizing mathematical problems. We employ a probing technique to extract representations from different layers of the model and apply these to classification tasks. Our findings reveal that models tend to efficiently classify simpler tasks, indicating that these concepts are learned in shallower layers. Conversely, more complex tasks may only be discernible at deeper layers, if at all. This paper explores the implications of these findings for our understanding of model learning processes and internal representations. Our implementation is available at \url{https://github.com/Luckfort/CD}.
Knowledge Graph Large Language Model (KG-LLM) for Link Prediction
Mar 19, 2024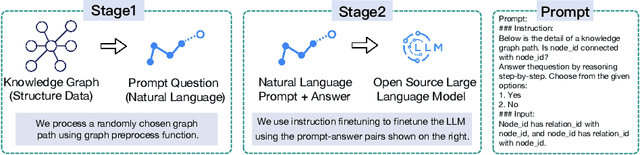
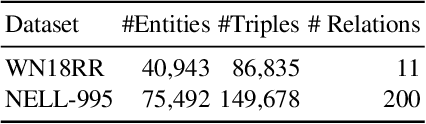
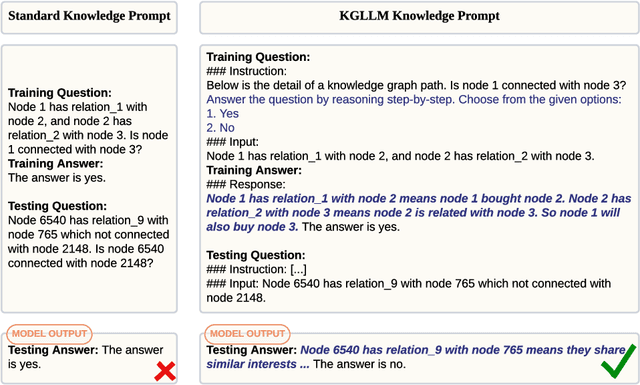
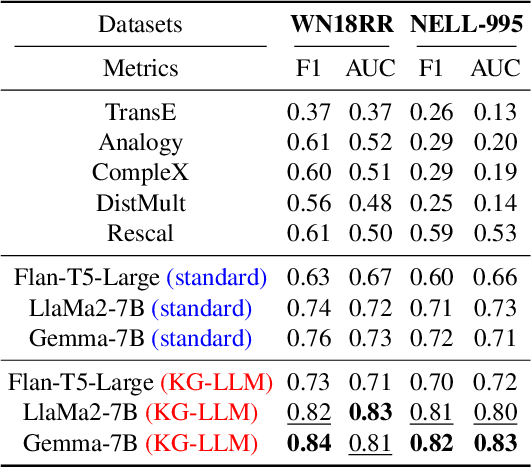
The task of predicting multiple links within knowledge graphs (KGs) stands as a challenge in the field of knowledge graph analysis, a challenge increasingly resolvable due to advancements in natural language processing (NLP) and KG embedding techniques. This paper introduces a novel methodology, the Knowledge Graph Large Language Model Framework (KG-LLM), which leverages pivotal NLP paradigms, including chain-of-thought (CoT) prompting and in-context learning (ICL), to enhance multi-hop link prediction in KGs. By converting the KG to a CoT prompt, our framework is designed to discern and learn the latent representations of entities and their interrelations. To show the efficacy of the KG-LLM Framework, we fine-tune three leading Large Language Models (LLMs) within this framework, employing both non-ICL and ICL tasks for a comprehensive evaluation. Further, we explore the framework's potential to provide LLMs with zero-shot capabilities for handling previously unseen prompts. Our experimental findings discover that integrating ICL and CoT not only augments the performance of our approach but also significantly boosts the models' generalization capacity, thereby ensuring more precise predictions in unfamiliar scenarios.
Usable XAI: 10 Strategies Towards Exploiting Explainability in the LLM Era
Mar 13, 2024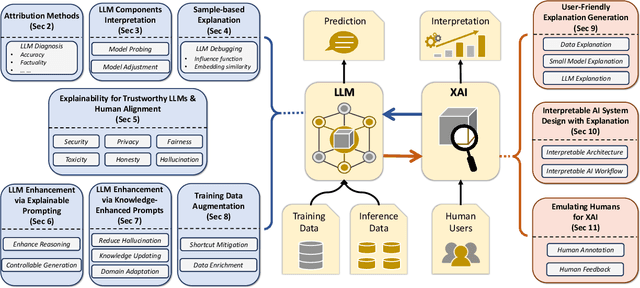

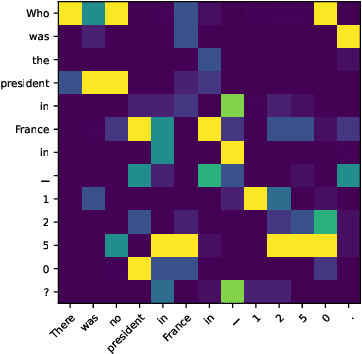
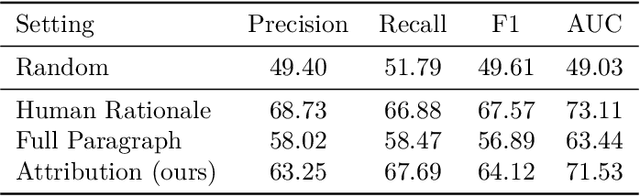
Explainable AI (XAI) refers to techniques that provide human-understandable insights into the workings of AI models. Recently, the focus of XAI is being extended towards Large Language Models (LLMs) which are often criticized for their lack of transparency. This extension calls for a significant transformation in XAI methodologies because of two reasons. First, many existing XAI methods cannot be directly applied to LLMs due to their complexity advanced capabilities. Second, as LLMs are increasingly deployed across diverse industry applications, the role of XAI shifts from merely opening the "black box" to actively enhancing the productivity and applicability of LLMs in real-world settings. Meanwhile, unlike traditional machine learning models that are passive recipients of XAI insights, the distinct abilities of LLMs can reciprocally enhance XAI. Therefore, in this paper, we introduce Usable XAI in the context of LLMs by analyzing (1) how XAI can benefit LLMs and AI systems, and (2) how LLMs can contribute to the advancement of XAI. We introduce 10 strategies, introducing the key techniques for each and discussing their associated challenges. We also provide case studies to demonstrate how to obtain and leverage explanations. The code used in this paper can be found at: https://github.com/JacksonWuxs/UsableXAI_LLM.
What if LLMs Have Different World Views: Simulating Alien Civilizations with LLM-based Agents
Feb 21, 2024In this study, we introduce "CosmoAgent," an innovative artificial intelligence framework utilizing Large Language Models (LLMs) to simulate complex interactions between human and extraterrestrial civilizations, with a special emphasis on Stephen Hawking's cautionary advice about not sending radio signals haphazardly into the universe. The goal is to assess the feasibility of peaceful coexistence while considering potential risks that could threaten well-intentioned civilizations. Employing mathematical models and state transition matrices, our approach quantitatively evaluates the development trajectories of civilizations, offering insights into future decision-making at critical points of growth and saturation. Furthermore, the paper acknowledges the vast diversity in potential living conditions across the universe, which could foster unique cosmologies, ethical codes, and worldviews among various civilizations. Recognizing the Earth-centric bias inherent in current LLM designs, we propose the novel concept of using LLMs with diverse ethical paradigms and simulating interactions between entities with distinct moral principles. This innovative research provides a new way to understand complex inter-civilizational dynamics, expanding our perspective while pioneering novel strategies for conflict resolution, crucial for preventing interstellar conflicts. We have also released the code and datasets to enable further academic investigation into this interesting area of research. The code is available at https://github.com/agiresearch/AlienAgent.
Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities
Feb 19, 2024



Large language models (LLMs) have been applied in many fields with rapid development in recent years. As a classic machine learning task, time series forecasting has recently received a boost from LLMs. However, there is a research gap in the LLMs' preferences in this field. In this paper, by comparing LLMs with traditional models, many properties of LLMs in time series prediction are found. For example, our study shows that LLMs excel in predicting time series with clear patterns and trends but face challenges with datasets lacking periodicity. We explain our findings through designing prompts to require LLMs to tell the period of the datasets. In addition, the input strategy is investigated, and it is found that incorporating external knowledge and adopting natural language paraphrases positively affects the predictive performance of LLMs for time series. Overall, this study contributes to insight into the advantages and limitations of LLMs in time series forecasting under different conditions.
Opening the Black Box of Large Language Models: Two Views on Holistic Interpretability
Feb 16, 2024As large language models (LLMs) grow more powerful, concerns around potential harms like toxicity, unfairness, and hallucination threaten user trust. Ensuring beneficial alignment of LLMs with human values through model alignment is thus critical yet challenging, requiring a deeper understanding of LLM behaviors and mechanisms. We propose opening the black box of LLMs through a framework of holistic interpretability encompassing complementary bottom-up and top-down perspectives. The bottom-up view, enabled by mechanistic interpretability, focuses on component functionalities and training dynamics. The top-down view utilizes representation engineering to analyze behaviors through hidden representations. In this paper, we review the landscape around mechanistic interpretability and representation engineering, summarizing approaches, discussing limitations and applications, and outlining future challenges in using these techniques to achieve ethical, honest, and reliable reasoning aligned with human values.
Health-LLM: Personalized Retrieval-Augmented Disease Prediction Model
Feb 08, 2024Artificial intelligence (AI) in healthcare has significantly advanced intelligent medical treatment. However, traditional intelligent healthcare is limited by static data and unified standards, preventing full integration with individual situations and other challenges. Hence, a more professional and detailed intelligent healthcare method is needed for development. To this end, we propose an innovative framework named Heath-LLM, which combines large-scale feature extraction and medical knowledge trade-off scoring. Compared to traditional health management methods, our approach has three main advantages. First, our method integrates health reports into a large model to provide detailed task information. Second, professional medical expertise is used to adjust the weighted scores of health characteristics. Third, we use a semi-automated feature extraction framework to enhance the analytical power of language models and incorporate expert insights to improve the accuracy of disease prediction. We have conducted disease prediction experiments on a large number of health reports to assess the effectiveness of Health-LLM. The results of the experiments indicate that the proposed method surpasses traditional methods and has the potential to revolutionize disease prediction and personalized health management. The code is available at https://github.com/jmyissb/HealthLLM.