 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Mitigating IP Infringement in Visual Generative AI
Jun 07, 2024The popularity of visual generative AI models like DALL-E 3, Stable Diffusion XL, Stable Video Diffusion, and Sora has been increasing. Through extensive evaluation, we discovered that the state-of-the-art visual generative models can generate content that bears a striking resemblance to characters protected by intellectual property rights held by major entertainment companies (such as Sony, Marvel, and Nintendo), which raises potential legal concerns. This happens when the input prompt contains the character's name or even just descriptive details about their characteristics. To mitigate such IP infringement problems, we also propose a defense method against it. In detail, we develop a revised generation paradigm that can identify potentially infringing generated content and prevent IP infringement by utilizing guidance techniques during the diffusion process. It has the capability to recognize generated content that may be infringing on intellectual property rights, and mitigate such infringement by employing guidance methods throughout the diffusion process without retrain or fine-tune the pretrained models. Experiments on well-known character IPs like Spider-Man, Iron Man, and Superman demonstrate the effectiveness of the proposed defense method. Our data and code can be found at https://github.com/ZhentingWang/GAI_IP_Infringement.
Towards Imperceptible Backdoor Attack in Self-supervised Learning
May 23, 2024Self-supervised learning models are vulnerable to backdoor attacks. Existing backdoor attacks that are effective in self-supervised learning often involve noticeable triggers, like colored patches, which are vulnerable to human inspection. In this paper, we propose an imperceptible and effective backdoor attack against self-supervised models. We first find that existing imperceptible triggers designed for supervised learning are not as effective in compromising self-supervised models. We then identify this ineffectiveness is attributed to the overlap in distributions between the backdoor and augmented samples used in self-supervised learning. Building on this insight, we design an attack using optimized triggers that are disentangled to the augmented transformation in the self-supervised learning, while also remaining imperceptible to human vision. Experiments on five datasets and seven SSL algorithms demonstrate our attack is highly effective and stealthy. It also has strong resistance to existing backdoor defenses. Our code can be found at https://github.com/Zhang-Henry/IMPERATIVE.
How to Trace Latent Generative Model Generated Images without Artificial Watermark?
May 22, 2024Latent generative models (e.g., Stable Diffusion) have become more and more popular, but concerns have arisen regarding potential misuse related to images generated by these models. It is, therefore, necessary to analyze the origin of images by inferring if a particular image was generated by a specific latent generative model. Most existing methods (e.g., image watermark and model fingerprinting) require extra steps during training or generation. These requirements restrict their usage on the generated images without such extra operations, and the extra required operations might compromise the quality of the generated images. In this work, we ask whether it is possible to effectively and efficiently trace the images generated by a specific latent generative model without the aforementioned requirements. To study this problem, we design a latent inversion based method called LatentTracer to trace the generated images of the inspected model by checking if the examined images can be well-reconstructed with an inverted latent input. We leverage gradient based latent inversion and identify a encoder-based initialization critical to the success of our approach. Our experiments on the state-of-the-art latent generative models, such as Stable Diffusion, show that our method can distinguish the images generated by the inspected model and other images with a high accuracy and efficiency. Our findings suggest the intriguing possibility that today's latent generative generated images are naturally watermarked by the decoder used in the source models. Code: https://github.com/ZhentingWang/LatentTracer.
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
Apr 10, 2024This paper studies the phenomenon that different concepts are learned in different layers of large language models, i.e. more difficult concepts are fully acquired with deeper layers. We define the difficulty of concepts by the level of abstraction, and here it is crudely categorized by factual, emotional, and inferential. Each category contains a spectrum of tasks, arranged from simple to complex. For example, within the factual dimension, tasks range from lie detection to categorizing mathematical problems. We employ a probing technique to extract representations from different layers of the model and apply these to classification tasks. Our findings reveal that models tend to efficiently classify simpler tasks, indicating that these concepts are learned in shallower layers. Conversely, more complex tasks may only be discernible at deeper layers, if at all. This paper explores the implications of these findings for our understanding of model learning processes and internal representations. Our implementation is available at \url{https://github.com/Luckfort/CD}.
Finding needles in a haystack: A Black-Box Approach to Invisible Watermark Detection
Mar 30, 2024In this paper, we propose WaterMark Detection (WMD), the first invisible watermark detection method under a black-box and annotation-free setting. WMD is capable of detecting arbitrary watermarks within a given reference dataset using a clean non-watermarked dataset as a reference, without relying on specific decoding methods or prior knowledge of the watermarking techniques. We develop WMD using foundations of offset learning, where a clean non-watermarked dataset enables us to isolate the influence of only watermarked samples in the reference dataset. Our comprehensive evaluations demonstrate the effectiveness of WMD, significantly outperforming naive detection methods, which only yield AUC scores around 0.5. In contrast, WMD consistently achieves impressive detection AUC scores, surpassing 0.9 in most single-watermark datasets and exceeding 0.7 in more challenging multi-watermark scenarios across diverse datasets and watermarking methods. As invisible watermarks become increasingly prevalent, while specific decoding techniques remain undisclosed, our approach provides a versatile solution and establishes a path toward increasing accountability, transparency, and trust in our digital visual content.
How to Detect Unauthorized Data Usages in Text-to-image Diffusion Models
Jul 06, 2023



Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized usage of data during the training process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission from the artist. To address this issue, it becomes crucial to detect unauthorized data usage. In this paper, we propose a method for detecting such unauthorized data usage by planting injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected image dataset by adding unique contents on the images such as stealthy image wrapping functions that are imperceptible to human vision but can be captured and memorized by diffusion models. By analyzing whether the model has memorization for the injected content (i.e., whether the generated images are processed by the chosen post-processing function), we can detect models that had illegally utilized the unauthorized data. Our experiments conducted on Stable Diffusion and LoRA model demonstrate the effectiveness of the proposed method in detecting unauthorized data usages.
Alteration-free and Model-agnostic Origin Attribution of Generated Images
May 29, 2023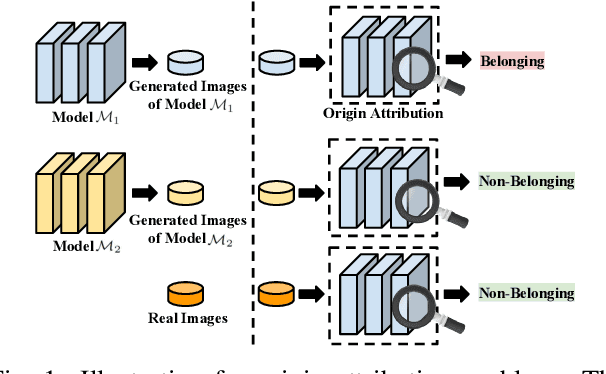


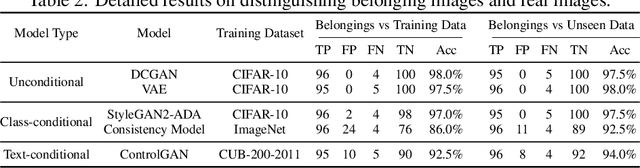
Recently, there has been a growing attention in image generation models. However, concerns have emerged regarding potential misuse and intellectual property (IP) infringement associated with these models. Therefore, it is necessary to analyze the origin of images by inferring if a specific image was generated by a particular model, i.e., origin attribution. Existing methods are limited in their applicability to specific types of generative models and require additional steps during training or generation. This restricts their use with pre-trained models that lack these specific operations and may compromise the quality of image generation. To overcome this problem, we first develop an alteration-free and model-agnostic origin attribution method via input reverse-engineering on image generation models, i.e., inverting the input of a particular model for a specific image. Given a particular model, we first analyze the differences in the hardness of reverse-engineering tasks for the generated images of the given model and other images. Based on our analysis, we propose a method that utilizes the reconstruction loss of reverse-engineering to infer the origin. Our proposed method effectively distinguishes between generated images from a specific generative model and other images, including those generated by different models and real images.
NOTABLE: Transferable Backdoor Attacks Against Prompt-based NLP Models
May 28, 2023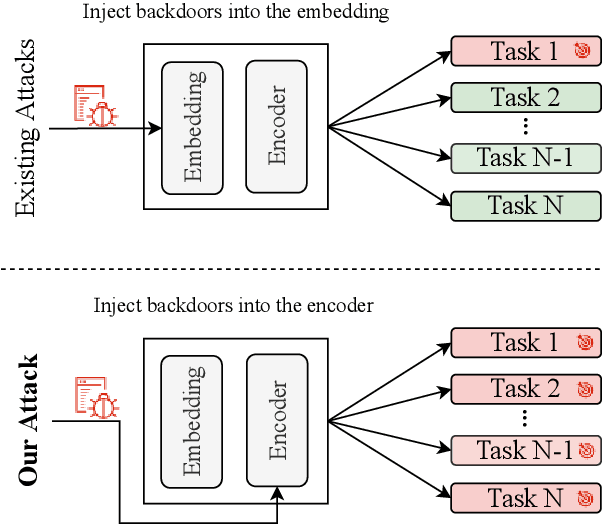
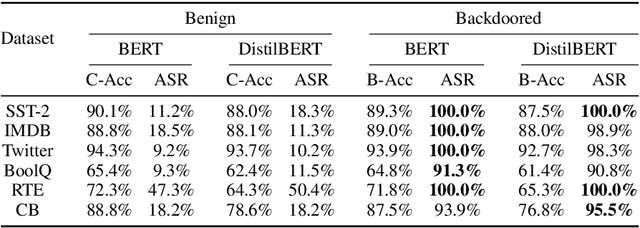


Prompt-based learning is vulnerable to backdoor attacks. Existing backdoor attacks against prompt-based models consider injecting backdoors into the entire embedding layers or word embedding vectors. Such attacks can be easily affected by retraining on downstream tasks and with different prompting strategies, limiting the transferability of backdoor attacks. In this work, we propose transferable backdoor attacks against prompt-based models, called NOTABLE, which is independent of downstream tasks and prompting strategies. Specifically, NOTABLE injects backdoors into the encoders of PLMs by utilizing an adaptive verbalizer to bind triggers to specific words (i.e., anchors). It activates the backdoor by pasting input with triggers to reach adversary-desired anchors, achieving independence from downstream tasks and prompting strategies. We conduct experiments on six NLP tasks, three popular models, and three prompting strategies. Empirical results show that NOTABLE achieves superior attack performance (i.e., attack success rate over 90% on all the datasets), and outperforms two state-of-the-art baselines. Evaluations on three defenses show the robustness of NOTABLE. Our code can be found at https://github.com/RU-System-Software-and-Security/Notable.
UNICORN: A Unified Backdoor Trigger Inversion Framework
Apr 05, 2023
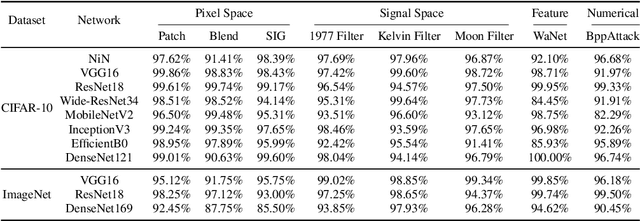

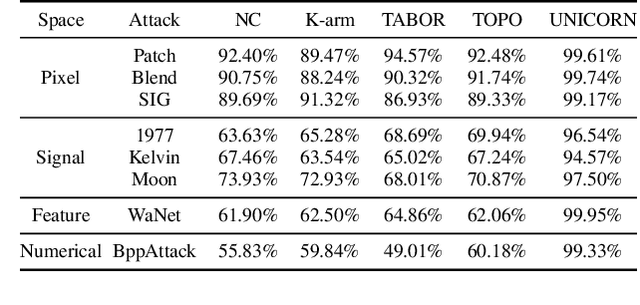
The backdoor attack, where the adversary uses inputs stamped with triggers (e.g., a patch) to activate pre-planted malicious behaviors, is a severe threat to Deep Neural Network (DNN) models. Trigger inversion is an effective way of identifying backdoor models and understanding embedded adversarial behaviors. A challenge of trigger inversion is that there are many ways of constructing the trigger. Existing methods cannot generalize to various types of triggers by making certain assumptions or attack-specific constraints. The fundamental reason is that existing work does not consider the trigger's design space in their formulation of the inversion problem. This work formally defines and analyzes the triggers injected in different spaces and the inversion problem. Then, it proposes a unified framework to invert backdoor triggers based on the formalization of triggers and the identified inner behaviors of backdoor models from our analysis. Our prototype UNICORN is general and effective in inverting backdoor triggers in DNNs. The code can be found at https://github.com/RU-System-Software-and-Security/UNICORN.
Backdoor Vulnerabilities in Normally Trained Deep Learning Models
Nov 29, 2022



We conduct a systematic study of backdoor vulnerabilities in normally trained Deep Learning models. They are as dangerous as backdoors injected by data poisoning because both can be equally exploited. We leverage 20 different types of injected backdoor attacks in the literature as the guidance and study their correspondences in normally trained models, which we call natural backdoor vulnerabilities. We find that natural backdoors are widely existing, with most injected backdoor attacks having natural correspondences. We categorize these natural backdoors and propose a general detection framework. It finds 315 natural backdoors in the 56 normally trained models downloaded from the Internet, covering all the different categories, while existing scanners designed for injected backdoors can at most detect 65 backdoors. We also study the root causes and defense of natural backdoors.