 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeX++: Learning Time-Series Explanations with Information Bottleneck
May 15, 2024Explaining deep learning models operating on time series data is crucial in various applications of interest which require interpretable and transparent insights from time series signals. In this work, we investigate this problem from an information theoretic perspective and show that most existing measures of explainability may suffer from trivial solutions and distributional shift issues. To address these issues, we introduce a simple yet practical objective function for time series explainable learning. The design of the objective function builds upon the principle of information bottleneck (IB), and modifies the IB objective function to avoid trivial solutions and distributional shift issues. We further present TimeX++, a novel explanation framework that leverages a parametric network to produce explanation-embedded instances that are both in-distributed and label-preserving. We evaluate TimeX++ on both synthetic and real-world datasets comparing its performance against leading baselines, and validate its practical efficacy through case studies in a real-world environmental application. Quantitative and qualitative evaluations show that TimeX++ outperforms baselines across all datasets, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/TimeXplusplus}.
Elevating Spectral GNNs through Enhanced Band-pass Filter Approximation
Apr 15, 2024Spectral Graph Neural Networks (GNNs) have attracted great attention due to their capacity to capture patterns in the frequency domains with essential graph filters. Polynomial-based ones (namely poly-GNNs), which approximately construct graph filters with conventional or rational polynomials, are routinely adopted in practice for their substantial performances on graph learning tasks. However, previous poly-GNNs aim at achieving overall lower approximation error on different types of filters, e.g., low-pass and high-pass, but ignore a key question: \textit{which type of filter warrants greater attention for poly-GNNs?} In this paper, we first show that poly-GNN with a better approximation for band-pass graph filters performs better on graph learning tasks. This insight further sheds light on critical issues of existing poly-GNNs, i.e., those poly-GNNs achieve trivial performance in approximating band-pass graph filters, hindering the great potential of poly-GNNs. To tackle the issues, we propose a novel poly-GNN named TrigoNet. TrigoNet constructs different graph filters with novel trigonometric polynomial, and achieves leading performance in approximating band-pass graph filters against other polynomials. By applying Taylor expansion and deserting nonlinearity, TrigoNet achieves noticeable efficiency among baselines. Extensive experiments show the advantages of TrigoNet in both accuracy performances and efficiency.
Spectral GNN via Two-dimensional (2-D) Graph Convolution
Apr 06, 2024Spectral Graph Neural Networks (GNNs) have achieved tremendous success in graph learning. As an essential part of spectral GNNs, spectral graph convolution extracts crucial frequency information in graph data, leading to superior performance of spectral GNNs in downstream tasks. However, in this paper, we show that existing spectral GNNs remain critical drawbacks in performing the spectral graph convolution. Specifically, considering the spectral graph convolution as a construction operation towards target output, we prove that existing popular convolution paradigms cannot construct the target output with mild conditions on input graph signals, causing spectral GNNs to fall into suboptimal solutions. To address the issues, we rethink the spectral graph convolution from a more general two-dimensional (2-D) signal convolution perspective and propose a new convolution paradigm, named 2-D graph convolution. We prove that 2-D graph convolution unifies existing graph convolution paradigms, and is capable to construct arbitrary target output. Based on the proposed 2-D graph convolution, we further propose ChebNet2D, an efficient and effective GNN implementation of 2-D graph convolution through applying Chebyshev interpolation. Extensive experiments on benchmark datasets demonstrate both effectiveness and efficiency of the ChebNet2D.
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
Mar 09, 2024
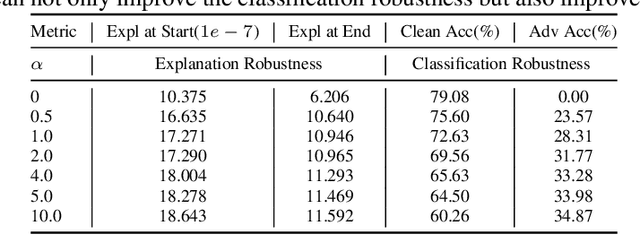
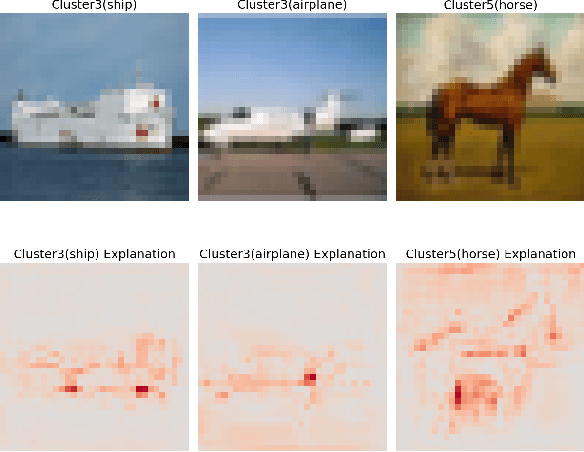
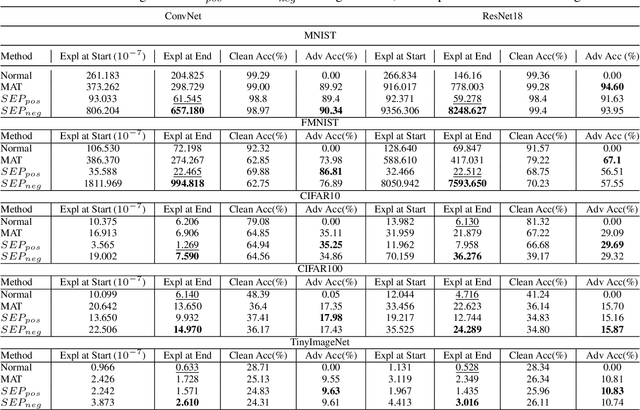
This paper delves into the critical area of deep learning robustness, challenging the conventional belief that classification robustness and explanation robustness in image classification systems are inherently correlated. Through a novel evaluation approach leveraging clustering for efficient assessment of explanation robustness, we demonstrate that enhancing explanation robustness does not necessarily flatten the input loss landscape with respect to explanation loss - contrary to flattened loss landscapes indicating better classification robustness. To deeply investigate this contradiction, a groundbreaking training method designed to adjust the loss landscape with respect to explanation loss is proposed. Through the new training method, we uncover that although such adjustments can impact the robustness of explanations, they do not have an influence on the robustness of classification. These findings not only challenge the prevailing assumption of a strong correlation between the two forms of robustness but also pave new pathways for understanding relationship between loss landscape and explanation loss.
Large Language Multimodal Models for 5-Year Chronic Disease Cohort Prediction Using EHR Data
Mar 02, 2024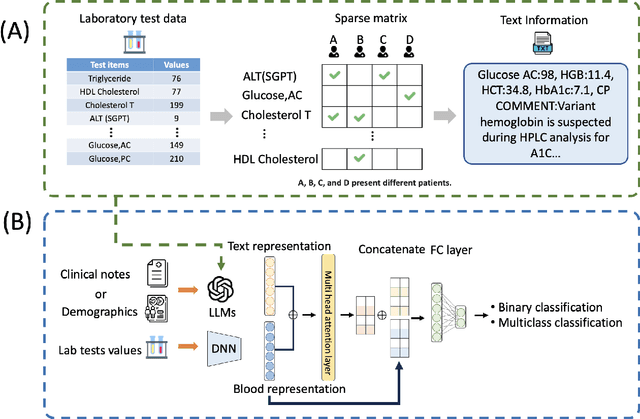

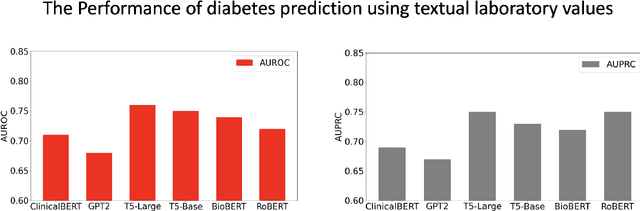
Chronic diseases such as diabetes are the leading causes of morbidity and mortality worldwide. Numerous research studies have been attempted with various deep learning models in diagnosis. However, most previous studies had certain limitations, including using publicly available datasets (e.g. MIMIC), and imbalanced data. In this study, we collected five-year electronic health records (EHRs) from the Taiwan hospital database, including 1,420,596 clinical notes, 387,392 laboratory test results, and more than 1,505 laboratory test items, focusing on research pre-training large language models. We proposed a novel Large Language Multimodal Models (LLMMs) framework incorporating multimodal data from clinical notes and laboratory test results for the prediction of chronic disease risk. Our method combined a text embedding encoder and multi-head attention layer to learn laboratory test values, utilizing a deep neural network (DNN) module to merge blood features with chronic disease semantics into a latent space. In our experiments, we observe that clinicalBERT and PubMed-BERT, when combined with attention fusion, can achieve an accuracy of 73% in multiclass chronic diseases and diabetes prediction. By transforming laboratory test values into textual descriptions and employing the Flan T-5 model, we achieved a 76% Area Under the ROC Curve (AUROC), demonstrating the effectiveness of leveraging numerical text data for training and inference in language models. This approach significantly improves the accuracy of early-stage diabetes prediction.
Parametric Augmentation for Time Series Contrastive Learning
Feb 16, 2024Modern techniques like contrastive learning have been effectively used in many areas, including computer vision, natural language processing, and graph-structured data. Creating positive examples that assist the model in learning robust and discriminative representations is a crucial stage in contrastive learning approaches. Usually, preset human intuition directs the selection of relevant data augmentations. Due to patterns that are easily recognized by humans, this rule of thumb works well in the vision and language domains. However, it is impractical to visually inspect the temporal structures in time series. The diversity of time series augmentations at both the dataset and instance levels makes it difficult to choose meaningful augmentations on the fly. In this study, we address this gap by analyzing time series data augmentation using information theory and summarizing the most commonly adopted augmentations in a unified format. We then propose a contrastive learning framework with parametric augmentation, AutoTCL, which can be adaptively employed to support time series representation learning. The proposed approach is encoder-agnostic, allowing it to be seamlessly integrated with different backbone encoders. Experiments on univariate forecasting tasks demonstrate the highly competitive results of our method, with an average 6.5\% reduction in MSE and 4.7\% in MAE over the leading baselines. In classification tasks, AutoTCL achieves a $1.2\%$ increase in average accuracy.
PAC Learnability under Explanation-Preserving Graph Perturbations
Feb 07, 2024Graphical models capture relations between entities in a wide range of applications including social networks, biology, and natural language processing, among others. Graph neural networks (GNN) are neural models that operate over graphs, enabling the model to leverage the complex relationships and dependencies in graph-structured data. A graph explanation is a subgraph which is an `almost sufficient' statistic of the input graph with respect to its classification label. Consequently, the classification label is invariant, with high probability, to perturbations of graph edges not belonging to its explanation subgraph. This work considers two methods for leveraging such perturbation invariances in the design and training of GNNs. First, explanation-assisted learning rules are considered. It is shown that the sample complexity of explanation-assisted learning can be arbitrarily smaller than explanation-agnostic learning. Next, explanation-assisted data augmentation is considered, where the training set is enlarged by artificially producing new training samples via perturbation of the non-explanation edges in the original training set. It is shown that such data augmentation methods may improve performance if the augmented data is in-distribution, however, it may also lead to worse sample complexity compared to explanation-agnostic learning rules if the augmented data is out-of-distribution. Extensive empirical evaluations are provided to verify the theoretical analysis.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.
Rank Supervised Contrastive Learning for Time Series Classification
Jan 31, 2024Recently, various contrastive learning techniques have been developed to categorize time series data and exhibit promising performance. A general paradigm is to utilize appropriate augmentations and construct feasible positive samples such that the encoder can yield robust and discriminative representations by mapping similar data points closer together in the feature space while pushing dissimilar data points farther apart. Despite its efficacy, the fine-grained relative similarity (e.g., rank) information of positive samples is largely ignored, especially when labeled samples are limited. To this end, we present Rank Supervised Contrastive Learning (RankSCL) to perform time series classification. Different from conventional contrastive learning frameworks, RankSCL augments raw data in a targeted way in the embedding space and adopts certain filtering rules to select more informative positive and negative pairs of samples. Moreover, a novel rank loss is developed to assign different weights for different levels of positive samples, enable the encoder to extract the fine-grained information of the same class, and produce a clear boundary among different classes. Thoroughly empirical studies on 128 UCR datasets and 30 UEA datasets demonstrate that the proposed RankSCL can achieve state-of-the-art performance compared to existing baseline methods.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.