 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Lane Detection and Topology Reasoning with 2D Lane Priors
Jun 05, 20243D lane detection and topology reasoning are essential tasks in autonomous driving scenarios, requiring not only detecting the accurate 3D coordinates on lane lines, but also reasoning the relationship between lanes and traffic elements. Current vision-based methods, whether explicitly constructing BEV features or not, all establish the lane anchors/queries in 3D space while ignoring the 2D lane priors. In this study, we propose Topo2D, a novel framework based on Transformer, leveraging 2D lane instances to initialize 3D queries and 3D positional embeddings. Furthermore, we explicitly incorporate 2D lane features into the recognition of topology relationships among lane centerlines and between lane centerlines and traffic elements. Topo2D achieves 44.5% OLS on multi-view topology reasoning benchmark OpenLane-V2 and 62.6% F-Socre on single-view 3D lane detection benchmark OpenLane, exceeding the performance of existing state-of-the-art methods.
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
May 11, 2024Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
May 07, 2024Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
A Model-based Multi-Agent Personalized Short-Video Recommender System
May 03, 2024Recommender selects and presents top-K items to the user at each online request, and a recommendation session consists of several sequential requests. Formulating a recommendation session as a Markov decision process and solving it by reinforcement learning (RL) framework has attracted increasing attention from both academic and industry communities. In this paper, we propose a RL-based industrial short-video recommender ranking framework, which models and maximizes user watch-time in an environment of user multi-aspect preferences by a collaborative multi-agent formulization. Moreover, our proposed framework adopts a model-based learning approach to alleviate the sample selection bias which is a crucial but intractable problem in industrial recommender system. Extensive offline evaluations and live experiments confirm the effectiveness of our proposed method over alternatives. Our proposed approach has been deployed in our real large-scale short-video sharing platform, successfully serving over hundreds of millions users.
CityLearn v2: Energy-flexible, resilient, occupant-centric, and carbon-aware management of grid-interactive communities
May 02, 2024As more distributed energy resources become part of the demand-side infrastructure, it is important to quantify the energy flexibility they provide on a community scale, particularly to understand the impact of geographic, climatic, and occupant behavioral differences on their effectiveness, as well as identify the best control strategies to accelerate their real-world adoption. CityLearn provides an environment for benchmarking simple and advanced distributed energy resource control algorithms including rule-based, model-predictive, and reinforcement learning control. CityLearn v2 presented here extends CityLearn v1 by providing a simulation environment that leverages the End-Use Load Profiles for the U.S. Building Stock dataset to create virtual grid-interactive communities for resilient, multi-agent distributed energy resources and objective control with dynamic occupant feedback. This work details the v2 environment design and provides application examples that utilize reinforcement learning to manage battery energy storage system charging/discharging cycles, vehicle-to-grid control, and thermal comfort during heat pump power modulation.
End-to-end training of Multimodal Model and ranking Model
Apr 09, 2024



Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.
BEM: Balanced and Entropy-based Mix for Long-Tailed Semi-Supervised Learning
Apr 01, 2024Data mixing methods play a crucial role in semi-supervised learning (SSL), but their application is unexplored in long-tailed semi-supervised learning (LTSSL). The primary reason is that the in-batch mixing manner fails to address class imbalance. Furthermore, existing LTSSL methods mainly focus on re-balancing data quantity but ignore class-wise uncertainty, which is also vital for class balance. For instance, some classes with sufficient samples might still exhibit high uncertainty due to indistinguishable features. To this end, this paper introduces the Balanced and Entropy-based Mix (BEM), a pioneering mixing approach to re-balance the class distribution of both data quantity and uncertainty. Specifically, we first propose a class balanced mix bank to store data of each class for mixing. This bank samples data based on the estimated quantity distribution, thus re-balancing data quantity. Then, we present an entropy-based learning approach to re-balance class-wise uncertainty, including entropy-based sampling strategy, entropy-based selection module, and entropy-based class balanced loss. Our BEM first leverages data mixing for improving LTSSL, and it can also serve as a complement to the existing re-balancing methods. Experimental results show that BEM significantly enhances various LTSSL frameworks and achieves state-of-the-art performances across multiple benchmarks.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024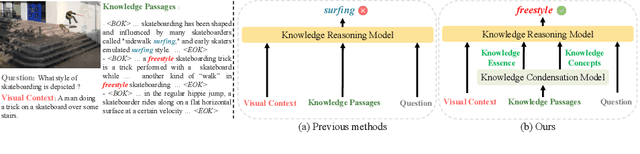
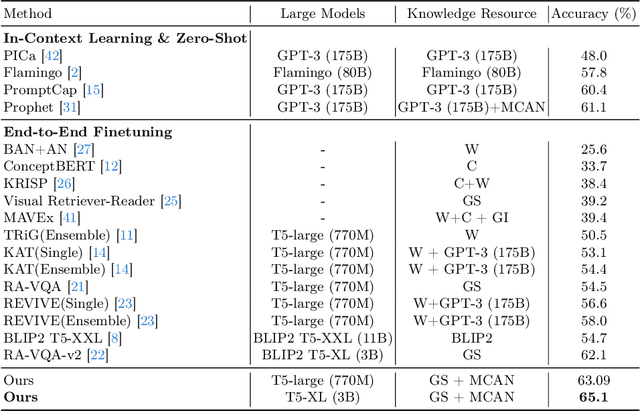
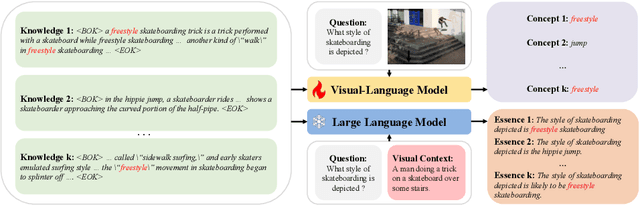
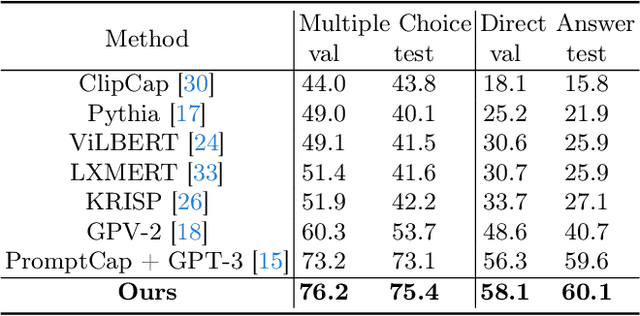
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).
Skeleton Supervised Airway Segmentation
Mar 11, 2024



Fully-supervised airway segmentation has accomplished significant triumphs over the years in aiding pre-operative diagnosis and intra-operative navigation. However, full voxel-level annotation constitutes a labor-intensive and time-consuming task, often plagued by issues such as missing branches, branch annotation discontinuity, or erroneous edge delineation. label-efficient solutions for airway extraction are rarely explored yet primarily demanding in medical practice. To this end, we introduce a novel skeleton-level annotation (SkA) tailored to the airway, which simplifies the annotation workflow while enhancing annotation consistency and accuracy, preserving the complete topology. Furthermore, we propose a skeleton-supervised learning framework to achieve accurate airway segmentation. Firstly, a dual-stream buffer inference is introduced to realize initial label propagation from SkA, avoiding the collapse of direct learning from SkA. Then, we construct a geometry-aware dual-path propagation framework (GDP) to further promote complementary propagation learning, composed of hard geometry-aware propagation learning and soft geometry-aware propagation guidance. Experiments reveal that our proposed framework outperforms the competing methods with SKA, which amounts to only 1.96% airways, and achieves comparable performance with the baseline model that is fully supervised with 100% airways, demonstrating its significant potential in achieving label-efficient segmentation for other tubular structures, such as vessels.
Understanding Public Perceptions of AI Conversational Agents: A Cross-Cultural Analysis
Feb 25, 2024Conversational Agents (CAs) have increasingly been integrated into everyday life, sparking significant discussions on social media. While previous research has examined public perceptions of AI in general, there is a notable lack in research focused on CAs, with fewer investigations into cultural variations in CA perceptions. To address this gap, this study used computational methods to analyze about one million social media discussions surrounding CAs and compared people's discourses and perceptions of CAs in the US and China. We find Chinese participants tended to view CAs hedonically, perceived voice-based and physically embodied CAs as warmer and more competent, and generally expressed positive emotions. In contrast, US participants saw CAs more functionally, with an ambivalent attitude. Warm perception was a key driver of positive emotions toward CAs in both countries. We discussed practical implications for designing contextually sensitive and user-centric CAs to resonate with various users' preferences and needs.
* 17 pages, 4 figures, 7 tables