 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding at the Speed of Thought: Harnessing Parallel Decoding of Lexical Units for LLMs
May 24, 2024Large language models have demonstrated exceptional capability in natural language understanding and generation. However, their generation speed is limited by the inherently sequential nature of their decoding process, posing challenges for real-time applications. This paper introduces Lexical Unit Decoding (LUD), a novel decoding methodology implemented in a data-driven manner, accelerating the decoding process without sacrificing output quality. The core of our approach is the observation that a pre-trained language model can confidently predict multiple contiguous tokens, forming the basis for a \textit{lexical unit}, in which these contiguous tokens could be decoded in parallel. Extensive experiments validate that our method substantially reduces decoding time while maintaining generation quality, i.e., 33\% speed up on natural language generation with no quality loss, and 30\% speed up on code generation with a negligible quality loss of 3\%. Distinctively, LUD requires no auxiliary models and does not require changes to existing architectures. It can also be integrated with other decoding acceleration methods, thus achieving an even more pronounced inference efficiency boost. We posit that the foundational principles of LUD could define a new decoding paradigm for future language models, enhancing their applicability for a broader spectrum of applications. All codes are be publicly available at https://github.com/tjunlp-lab/Lexical-Unit-Decoding-LUD-. Keywords: Parallel Decoding, Lexical Unit Decoding, Large Language Model
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
May 24, 2024Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.
Learning Multi-dimensional Human Preference for Text-to-Image Generation
May 23, 2024Current metrics for text-to-image models typically rely on statistical metrics which inadequately represent the real preference of humans. Although recent work attempts to learn these preferences via human annotated images, they reduce the rich tapestry of human preference to a single overall score. However, the preference results vary when humans evaluate images with different aspects. Therefore, to learn the multi-dimensional human preferences, we propose the Multi-dimensional Preference Score (MPS), the first multi-dimensional preference scoring model for the evaluation of text-to-image models. The MPS introduces the preference condition module upon CLIP model to learn these diverse preferences. It is trained based on our Multi-dimensional Human Preference (MHP) Dataset, which comprises 918,315 human preference choices across four dimensions (i.e., aesthetics, semantic alignment, detail quality and overall assessment) on 607,541 images. The images are generated by a wide range of latest text-to-image models. The MPS outperforms existing scoring methods across 3 datasets in 4 dimensions, enabling it a promising metric for evaluating and improving text-to-image generation.
Tele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
End-to-end training of Multimodal Model and ranking Model
Apr 09, 2024



Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024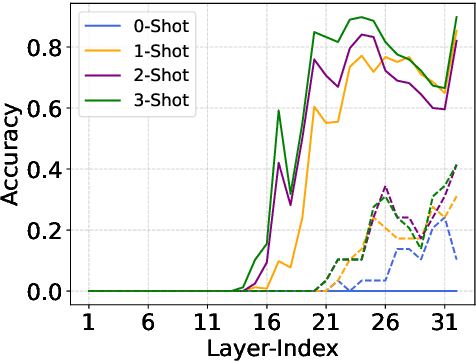
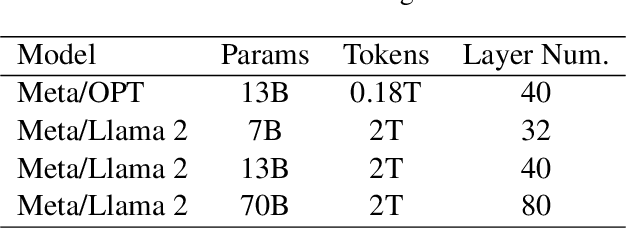
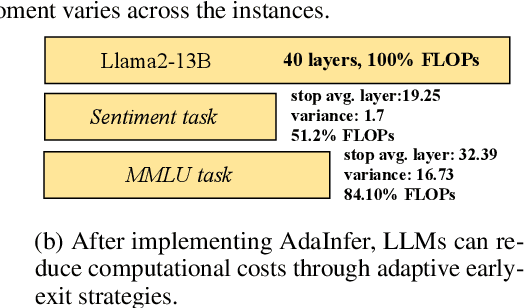

The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
DVIS++: Improved Decoupled Framework for Universal Video Segmentation
Dec 20, 2023We present the \textbf{D}ecoupled \textbf{VI}deo \textbf{S}egmentation (DVIS) framework, a novel approach for the challenging task of universal video segmentation, including video instance segmentation (VIS), video semantic segmentation (VSS), and video panoptic segmentation (VPS). Unlike previous methods that model video segmentation in an end-to-end manner, our approach decouples video segmentation into three cascaded sub-tasks: segmentation, tracking, and refinement. This decoupling design allows for simpler and more effective modeling of the spatio-temporal representations of objects, especially in complex scenes and long videos. Accordingly, we introduce two novel components: the referring tracker and the temporal refiner. These components track objects frame by frame and model spatio-temporal representations based on pre-aligned features. To improve the tracking capability of DVIS, we propose a denoising training strategy and introduce contrastive learning, resulting in a more robust framework named DVIS++. Furthermore, we evaluate DVIS++ in various settings, including open vocabulary and using a frozen pre-trained backbone. By integrating CLIP with DVIS++, we present OV-DVIS++, the first open-vocabulary universal video segmentation framework. We conduct extensive experiments on six mainstream benchmarks, including the VIS, VSS, and VPS datasets. Using a unified architecture, DVIS++ significantly outperforms state-of-the-art specialized methods on these benchmarks in both close- and open-vocabulary settings. Code:~\url{https://github.com/zhang-tao-whu/DVIS_Plus}.
KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
Dec 08, 2023Driven by curiosity, humans have continually sought to explore and understand the world around them, leading to the invention of various tools to satiate this inquisitiveness. Despite not having the capacity to process and memorize vast amounts of information in their brains, humans excel in critical thinking, planning, reflection, and harnessing available tools to interact with and interpret the world, enabling them to find answers efficiently. The recent advancements in large language models (LLMs) suggest that machines might also possess the aforementioned human-like capabilities, allowing them to exhibit powerful abilities even with a constrained parameter count. In this paper, we introduce KwaiAgents, a generalized information-seeking agent system based on LLMs. Within KwaiAgents, we propose an agent system that employs LLMs as its cognitive core, which is capable of understanding a user's query, behavior guidelines, and referencing external documents. The agent can also update and retrieve information from its internal memory, plan and execute actions using a time-aware search-browse toolkit, and ultimately provide a comprehensive response. We further investigate the system's performance when powered by LLMs less advanced than GPT-4, and introduce the Meta-Agent Tuning (MAT) framework, designed to ensure even an open-sourced 7B or 13B model performs well among many agent systems. We exploit both benchmark and human evaluations to systematically validate these capabilities. Extensive experiments show the superiority of our agent system compared to other autonomous agents and highlight the enhanced generalized agent-abilities of our fine-tuned LLMs.
Stable Segment Anything Model
Dec 05, 2023The Segment Anything Model (SAM) achieves remarkable promptable segmentation given high-quality prompts which, however, often require good skills to specify. To make SAM robust to casual prompts, this paper presents the first comprehensive analysis on SAM's segmentation stability across a diverse spectrum of prompt qualities, notably imprecise bounding boxes and insufficient points. Our key finding reveals that given such low-quality prompts, SAM's mask decoder tends to activate image features that are biased towards the background or confined to specific object parts. To mitigate this issue, our key idea consists of calibrating solely SAM's mask attention by adjusting the sampling locations and amplitudes of image features, while the original SAM model architecture and weights remain unchanged. Consequently, our deformable sampling plugin (DSP) enables SAM to adaptively shift attention to the prompted target regions in a data-driven manner, facilitated by our effective robust training strategy (RTS). During inference, dynamic routing plugin (DRP) is proposed that toggles SAM between the deformable and regular grid sampling modes, conditioned on the input prompt quality. Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0.08 M) and fast adaptation (by 1 training epoch). Extensive experiments across multiple datasets validate the effectiveness and advantages of our approach, underscoring Stable-SAM as a more robust solution for segmenting anything. Codes will be released upon acceptance. https://github.com/fanq15/Stable-SAM
Paragraph-to-Image Generation with Information-Enriched Diffusion Model
Nov 29, 2023Text-to-image (T2I) models have recently experienced rapid development, achieving astonishing performance in terms of fidelity and textual alignment capabilities. However, given a long paragraph (up to 512 words), these generation models still struggle to achieve strong alignment and are unable to generate images depicting complex scenes. In this paper, we introduce an information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation. At its core is using a large language model (e.g., Llama V2) to encode long-form text, followed by fine-tuning with LORA to alignthe text-image feature spaces in the generation task. To facilitate the training of long-text semantic alignment, we also curated a high-quality paragraph-image pair dataset, namely ParaImage. This dataset contains a small amount of high-quality, meticulously annotated data, and a large-scale synthetic dataset with long text descriptions being generated using a vision-language model. Experiments demonstrate that ParaDiffusion outperforms state-of-the-art models (SD XL, DeepFloyd IF) on ViLG-300 and ParaPrompts, achieving up to 15% and 45% human voting rate improvements for visual appeal and text faithfulness, respectively. The code and dataset will be released to foster community research on long-text alignment.