 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
Beyond Collaborative Filtering: A Relook at Task Formulation in Recommender Systems
Apr 20, 2024Recommender Systems (RecSys) have become indispensable in numerous applications, profoundly influencing our everyday experiences. Despite their practical significance, academic research in RecSys often abstracts the formulation of research tasks from real-world contexts, aiming for a clean problem formulation and more generalizable findings. However, it is observed that there is a lack of collective understanding in RecSys academic research. The root of this issue may lie in the simplification of research task definitions, and an overemphasis on modeling the decision outcomes rather than the decision-making process. That is, we often conceptualize RecSys as the task of predicting missing values in a static user-item interaction matrix, rather than predicting a user's decision on the next interaction within a dynamic, changing, and application-specific context. There exists a mismatch between the inputs accessible to a model and the information available to users during their decision-making process, yet the model is tasked to predict users' decisions. While collaborative filtering is effective in learning general preferences from historical records, it is crucial to also consider the dynamic contextual factors in practical settings. Defining research tasks based on application scenarios using domain-specific datasets may lead to more insightful findings. Accordingly, viable solutions and effective evaluations can emerge for different application scenarios.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024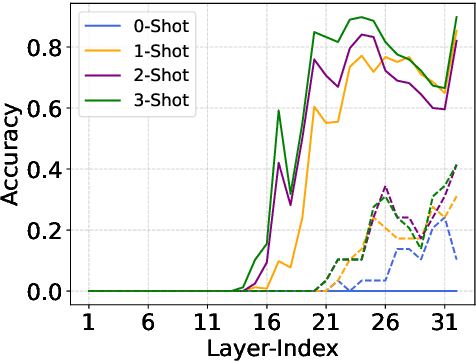
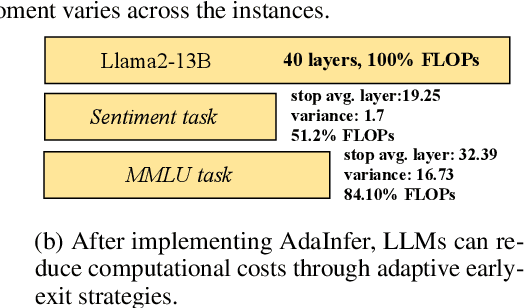

The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
Recommender for Its Purpose: Repeat and Exploration in Food Delivery Recommendations
Feb 22, 2024Recommender systems have been widely used for various scenarios, such as e-commerce, news, and music, providing online contents to help and enrich users' daily life. Different scenarios hold distinct and unique characteristics, calling for domain-specific investigations and corresponding designed recommender systems. Therefore, in this paper, we focus on food delivery recommendations to unveil unique features in this domain, where users order food online and enjoy their meals shortly after delivery. We first conduct an in-depth analysis on food delivery datasets. The analysis shows that repeat orders are prevalent for both users and stores, and situations' differently influence repeat and exploration consumption in the food delivery recommender systems. Moreover, we revisit the ability of existing situation-aware methods for repeat and exploration recommendations respectively, and find them unable to effectively solve both tasks simultaneously. Based on the analysis and experiments, we have designed two separate recommendation models -- ReRec for repeat orders and ExpRec for exploration orders; both are simple in their design and computation. We conduct experiments on three real-world food delivery datasets, and our proposed models outperform various types of baselines on repeat, exploration, and combined recommendation tasks. This paper emphasizes the importance of dedicated analyses and methods for domain-specific characteristics for the recommender system studies.
SciAgent: Tool-augmented Language Models for Scientific Reasoning
Feb 21, 2024Scientific reasoning poses an excessive challenge for even the most advanced Large Language Models (LLMs). To make this task more practical and solvable for LLMs, we introduce a new task setting named tool-augmented scientific reasoning. This setting supplements LLMs with scalable toolsets, and shifts the focus from pursuing an omniscient problem solver to a proficient tool-user. To facilitate the research of such setting, we construct a tool-augmented training corpus named MathFunc which encompasses over 30,000 samples and roughly 6,000 tools. Building on MathFunc, we develop SciAgent to retrieve, understand and, if necessary, use tools for scientific problem solving. Additionally, we craft a benchmark, SciToolBench, spanning five scientific domains to evaluate LLMs' abilities with tool assistance. Extensive experiments on SciToolBench confirm the effectiveness of SciAgent. Notably, SciAgent-Mistral-7B surpasses other LLMs with the same size by more than 13% in absolute accuracy. Furthermore, SciAgent-DeepMath-7B shows much superior performance than ChatGPT.
Parameter-Efficient Conversational Recommender System as a Language Processing Task
Feb 03, 2024



Conversational recommender systems (CRS) aim to recommend relevant items to users by eliciting user preference through natural language conversation. Prior work often utilizes external knowledge graphs for items' semantic information, a language model for dialogue generation, and a recommendation module for ranking relevant items. This combination of multiple components suffers from a cumbersome training process, and leads to semantic misalignment issues between dialogue generation and item recommendation. In this paper, we represent items in natural language and formulate CRS as a natural language processing task. Accordingly, we leverage the power of pre-trained language models to encode items, understand user intent via conversation, perform item recommendation through semantic matching, and generate dialogues. As a unified model, our PECRS (Parameter-Efficient CRS), can be optimized in a single stage, without relying on non-textual metadata such as a knowledge graph. Experiments on two benchmark CRS datasets, ReDial and INSPIRED, demonstrate the effectiveness of PECRS on recommendation and conversation. Our code is available at: https://github.com/Ravoxsg/efficient_unified_crs.
Multi-scale 2D Temporal Map Diffusion Models for Natural Language Video Localization
Jan 16, 2024Natural Language Video Localization (NLVL), grounding phrases from natural language descriptions to corresponding video segments, is a complex yet critical task in video understanding. Despite ongoing advancements, many existing solutions lack the capability to globally capture temporal dynamics of the video data. In this study, we present a novel approach to NLVL that aims to address this issue. Our method involves the direct generation of a global 2D temporal map via a conditional denoising diffusion process, based on the input video and language query. The main challenges are the inherent sparsity and discontinuity of a 2D temporal map in devising the diffusion decoder. To address these challenges, we introduce a multi-scale technique and develop an innovative diffusion decoder. Our approach effectively encapsulates the interaction between the query and video data across various time scales. Experiments on the Charades and DiDeMo datasets underscore the potency of our design.
On Position Bias in Summarization with Large Language Models
Oct 16, 2023



Large language models (LLMs) excel in zero-shot abstractive summarization tasks, delivering fluent and pertinent summaries. Recent advancements have extended their capabilities to handle long-input contexts, surpassing token limits of 32k or more. However, in the realm of multi-document question answering, language models exhibit uneven utilization of their input context. They tend to favor the initial and final segments, resulting in a U-shaped performance pattern concerning where the answer is located within the input. This bias raises concerns, particularly in summarization tasks where crucial content may be dispersed throughout the source document(s). This paper presents a comprehensive investigation encompassing 10 datasets, 4 LLMs, and 5 evaluation metrics to analyze how these models leverage their input for abstractive summarization. Our findings reveal a pronounced bias towards the introductory content (and to a lesser extent, the final content), posing challenges for LLM performance across a range of diverse summarization benchmarks.
Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution
Oct 09, 2023



Although achieving great success, Large Language Models (LLMs) usually suffer from unreliable hallucinations. In this paper, we define a new task of Knowledge-aware Language Model Attribution (KaLMA) that improves upon three core concerns on conventional attributed LMs. First, we extend attribution source from unstructured texts to Knowledge Graph (KG), whose rich structures benefit both the attribution performance and working scenarios. Second, we propose a new ``Conscious Incompetence" setting considering the incomplete knowledge repository, where the model identifies the need for supporting knowledge beyond the provided KG. Third, we propose a comprehensive automatic evaluation metric encompassing text quality, citation quality, and text citation alignment. To implement the above innovations, we build a dataset in biography domain BioKaLMA via a well-designed evolutionary question generation strategy, to control the question complexity and necessary knowledge to the answer. For evaluation, we develop a baseline solution and demonstrate the room for improvement in LLMs' citation generation, emphasizing the importance of incorporating the "Conscious Incompetence" setting, and the critical role of retrieval accuracy.
An Image Dataset for Benchmarking Recommender Systems with Raw Pixels
Sep 17, 2023

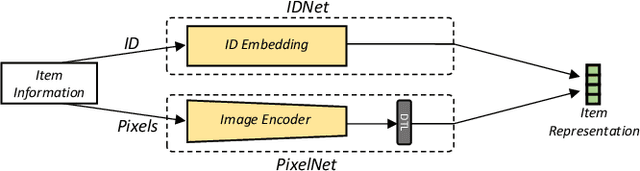

Recommender systems (RS) have achieved significant success by leveraging explicit identification (ID) features. However, the full potential of content features, especially the pure image pixel features, remains relatively unexplored. The limited availability of large, diverse, and content-driven image recommendation datasets has hindered the use of raw images as item representations. In this regard, we present PixelRec, a massive image-centric recommendation dataset that includes approximately 200 million user-image interactions, 30 million users, and 400,000 high-quality cover images. By providing direct access to raw image pixels, PixelRec enables recommendation models to learn item representation directly from them. To demonstrate its utility, we begin by presenting the results of several classical pure ID-based baseline models, termed IDNet, trained on PixelRec. Then, to show the effectiveness of the dataset's image features, we substitute the itemID embeddings (from IDNet) with a powerful vision encoder that represents items using their raw image pixels. This new model is dubbed PixelNet.Our findings indicate that even in standard, non-cold start recommendation settings where IDNet is recognized as highly effective, PixelNet can already perform equally well or even better than IDNet. Moreover, PixelNet has several other notable advantages over IDNet, such as being more effective in cold-start and cross-domain recommendation scenarios. These results underscore the importance of visual features in PixelRec. We believe that PixelRec can serve as a critical resource and testing ground for research on recommendation models that emphasize image pixel content. The dataset, code, and leaderboard will be available at https://github.com/westlake-repl/PixelRec.