 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Quilt Spreading for Caregiving Robots
May 24, 2024In this work, we propose a novel strategy to ensure infants, who inadvertently displace their quilts during sleep, are promptly and accurately re-covered. Our approach is formulated into two subsequent steps: interference resolution and quilt spreading. By leveraging the DWPose human skeletal detection and the Segment Anything instance segmentation models, the proposed method can accurately recognize the states of the infant and the quilt over her, which involves addressing the interferences resulted from an infant's limbs laid on part of the quilt. Building upon prior research, the EM*D deep learning model is employed to forecast quilt state transitions before and after quilt spreading actions. To improve the sensitivity of the network in distinguishing state variation of the handled quilt, we introduce an enhanced loss function that translates the voxelized quilt state into a more representative one. Both simulation and real-world experiments validate the efficacy of our method, in spreading and recover a quilt over an infant.
CAPE: Context-Adaptive Positional Encoding for Length Extrapolation
May 23, 2024Positional encoding plays a crucial role in transformers, significantly impacting model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be context-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Context-Adaptive Positional Encoding (CAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that CAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
Mixture of insighTful Experts (MoTE): The Synergy of Thought Chains and Expert Mixtures in Self-Alignment
May 01, 2024As the capabilities of large language models (LLMs) have expanded dramatically, aligning these models with human values presents a significant challenge, posing potential risks during deployment. Traditional alignment strategies rely heavily on human intervention, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), or on the self-alignment capacities of LLMs, which usually require a strong LLM's emergent ability to improve its original bad answer. To address these challenges, we propose a novel self-alignment method that utilizes a Chain of Thought (CoT) approach, termed AlignCoT. This method encompasses stages of Question Analysis, Answer Guidance, and Safe Answer production. It is designed to enable LLMs to generate high-quality, safe responses throughout various stages of their development. Furthermore, we introduce the Mixture of insighTful Experts (MoTE) architecture, which applies the mixture of experts to enhance each component of the AlignCoT process, markedly increasing alignment efficiency. The MoTE approach not only outperforms existing methods in aligning LLMs with human values but also highlights the benefits of using self-generated data, revealing the dual benefits of improved alignment and training efficiency.
Tele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
DVF: Advancing Robust and Accurate Fine-Grained Image Retrieval with Retrieval Guidelines
Apr 24, 2024Fine-grained image retrieval (FGIR) is to learn visual representations that distinguish visually similar objects while maintaining generalization. Existing methods propose to generate discriminative features, but rarely consider the particularity of the FGIR task itself. This paper presents a meticulous analysis leading to the proposal of practical guidelines to identify subcategory-specific discrepancies and generate discriminative features to design effective FGIR models. These guidelines include emphasizing the object (G1), highlighting subcategory-specific discrepancies (G2), and employing effective training strategy (G3). Following G1 and G2, we design a novel Dual Visual Filtering mechanism for the plain visual transformer, denoted as DVF, to capture subcategory-specific discrepancies. Specifically, the dual visual filtering mechanism comprises an object-oriented module and a semantic-oriented module. These components serve to magnify objects and identify discriminative regions, respectively. Following G3, we implement a discriminative model training strategy to improve the discriminability and generalization ability of DVF. Extensive analysis and ablation studies confirm the efficacy of our proposed guidelines. Without bells and whistles, the proposed DVF achieves state-of-the-art performance on three widely-used fine-grained datasets in closed-set and open-set settings.
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
Random-coupled Neural Network
Mar 26, 2024



Improving the efficiency of current neural networks and modeling them in biological neural systems have become popular research directions in recent years. Pulse-coupled neural network (PCNN) is a well applicated model for imitating the computation characteristics of the human brain in computer vision and neural network fields. However, differences between the PCNN and biological neural systems remain: limited neural connection, high computational cost, and lack of stochastic property. In this study, random-coupled neural network (RCNN) is proposed. It overcomes these difficulties in PCNN's neuromorphic computing via a random inactivation process. This process randomly closes some neural connections in the RCNN model, realized by the random inactivation weight matrix of link input. This releases the computational burden of PCNN, making it affordable to achieve vast neural connections. Furthermore, the image and video processing mechanisms of RCNN are researched. It encodes constant stimuli as periodic spike trains and periodic stimuli as chaotic spike trains, the same as biological neural information encoding characteristics. Finally, the RCNN is applicated to image segmentation, fusion, and pulse shape discrimination subtasks. It is demonstrated to be robust, efficient, and highly anti-noised, with outstanding performance in all applications mentioned above.
Not all Layers of LLMs are Necessary during Inference
Mar 04, 2024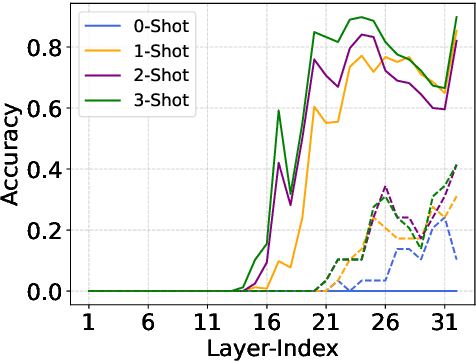
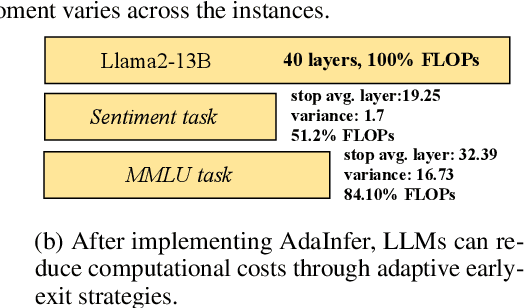

The inference phase of Large Language Models (LLMs) is very expensive. An ideal inference stage of LLMs could utilize fewer computational resources while still maintaining its capabilities (e.g., generalization and in-context learning ability). In this paper, we try to answer the question, "During LLM inference, can we use shallow layers for easy instances; and deep layers for hard ones?" To answer this question, we first indicate that Not all Layers are Necessary during Inference by statistically analyzing the activated layers across tasks. Then, we propose a simple algorithm named AdaInfer to determine the inference termination moment based on the input instance adaptively. More importantly, AdaInfer does not alter LLM parameters and maintains generalizability across tasks. Experiments on well-known LLMs (i.e., Llama2 series and OPT) show that AdaInfer saves an average of 14.8% of computational resources, even up to 50% on sentiment tasks, while maintaining comparable performance. Additionally, this method is orthogonal to other model acceleration techniques, potentially boosting inference efficiency further.
Learning to Edit: Aligning LLMs with Knowledge Editing
Feb 19, 2024Knowledge editing techniques, aiming to efficiently modify a minor proportion of knowledge in large language models (LLMs) without negatively impacting performance across other inputs, have garnered widespread attention. However, existing methods predominantly rely on memorizing the updated knowledge, impeding LLMs from effectively combining the new knowledge with their inherent knowledge when answering questions. To this end, we propose a Learning to Edit (LTE) framework, focusing on teaching LLMs to apply updated knowledge into input questions, inspired by the philosophy of "Teach a man to fish." LTE features a two-phase process: (i) the Alignment Phase, which fine-tunes LLMs on a meticulously curated parallel dataset to make reliable, in-scope edits while preserving out-of-scope information and linguistic proficiency; and (ii) the Inference Phase, which employs a retrieval-based mechanism for real-time and mass knowledge editing. By comparing our approach with seven advanced baselines across four popular knowledge editing benchmarks and two LLM architectures, we demonstrate LTE's superiority in knowledge editing performance, robustness in both batch and sequential editing, minimal interference on general tasks, and rapid editing speeds. The data and code are available at https://github.com/YJiangcm/LTE.
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models
Jan 30, 2024Large language models (LLMs) are increasingly relied upon for complex multi-turn conversations across diverse real-world applications. However, existing benchmarks predominantly focus on single-turn evaluations, overlooking the models' capabilities in multi-turn interactions. To address this gap, we introduce MT-Eval, a comprehensive benchmark designed to evaluate multi-turn conversational abilities. By analyzing human-LLM conversations, we categorize interaction patterns into four types: recollection, expansion, refinement, and follow-up. We construct multi-turn queries for each category either by augmenting existing datasets or by creating new examples with GPT-4 to avoid data leakage. To study the factors impacting multi-turn abilities, we create single-turn versions of the 1170 multi-turn queries and compare performance. Our evaluation of 11 well-known LLMs shows that while closed-source models generally surpass open-source ones, certain open-source models exceed GPT-3.5-Turbo in specific tasks. We observe significant performance degradation in multi-turn settings compared to single-turn settings in most models, which is not correlated with the models' fundamental capabilities. Moreover, we identify the distance to relevant content and susceptibility to error propagation as the key factors influencing multi-turn performance. MT-Eval is released publicly to encourage future research towards more robust conversational models.