 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Pretraining and Generation for Recommendation: A Tutorial
May 11, 2024Personalized recommendation stands as a ubiquitous channel for users to explore information or items aligned with their interests. Nevertheless, prevailing recommendation models predominantly rely on unique IDs and categorical features for user-item matching. While this ID-centric approach has witnessed considerable success, it falls short in comprehensively grasping the essence of raw item contents across diverse modalities, such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, particularly in the realm of multimedia services like news, music, and short-video platforms. The recent surge in pretraining and generation techniques presents both opportunities and challenges in the development of multimodal recommender systems. This tutorial seeks to provide a thorough exploration of the latest advancements and future trajectories in multimodal pretraining and generation techniques within the realm of recommender systems. The tutorial comprises three parts: multimodal pretraining, multimodal generation, and industrial applications and open challenges in the field of recommendation. Our target audience encompasses scholars, practitioners, and other parties interested in this domain. By providing a succinct overview of the field, we aspire to facilitate a swift understanding of multimodal recommendation and foster meaningful discussions on the future development of this evolving landscape.
Revisiting the Efficacy of Signal Decomposition in AI-based Time Series Prediction
May 11, 2024



Time series prediction is a fundamental problem in scientific exploration and artificial intelligence (AI) technologies have substantially bolstered its efficiency and accuracy. A well-established paradigm in AI-driven time series prediction is injecting physical knowledge into neural networks through signal decomposition methods, and sustaining progress in numerous scenarios has been reported. However, we uncover non-negligible evidence that challenges the effectiveness of signal decomposition in AI-based time series prediction. We confirm that improper dataset processing with subtle future label leakage is unfortunately widely adopted, possibly yielding abnormally superior but misleading results. By processing data in a strictly causal way without any future information, the effectiveness of additional decomposed signals diminishes. Our work probably identifies an ingrained and universal error in time series modeling, and the de facto progress in relevant areas is expected to be revisited and calibrated to prevent future scientific detours and minimize practical losses.
Collaborative-Enhanced Prediction of Spending on Newly Downloaded Mobile Games under Consumption Uncertainty
Apr 12, 2024



With the surge in mobile gaming, accurately predicting user spending on newly downloaded games has become paramount for maximizing revenue. However, the inherently unpredictable nature of user behavior poses significant challenges in this endeavor. To address this, we propose a robust model training and evaluation framework aimed at standardizing spending data to mitigate label variance and extremes, ensuring stability in the modeling process. Within this framework, we introduce a collaborative-enhanced model designed to predict user game spending without relying on user IDs, thus ensuring user privacy and enabling seamless online training. Our model adopts a unique approach by separately representing user preferences and game features before merging them as input to the spending prediction module. Through rigorous experimentation, our approach demonstrates notable improvements over production models, achieving a remarkable \textbf{17.11}\% enhancement on offline data and an impressive \textbf{50.65}\% boost in an online A/B test. In summary, our contributions underscore the importance of stable model training frameworks and the efficacy of collaborative-enhanced models in predicting user spending behavior in mobile gaming.
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024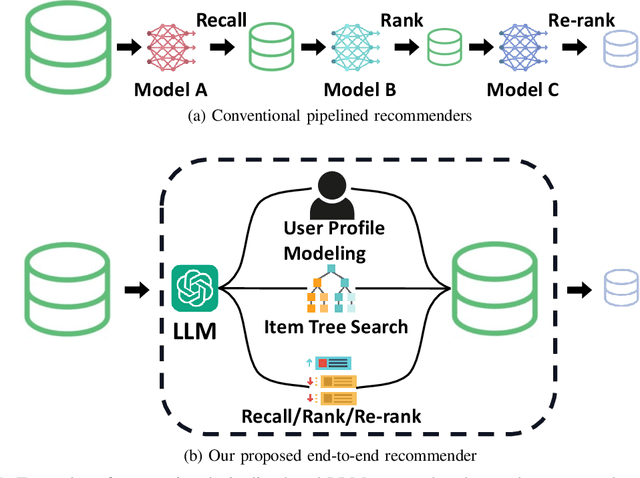
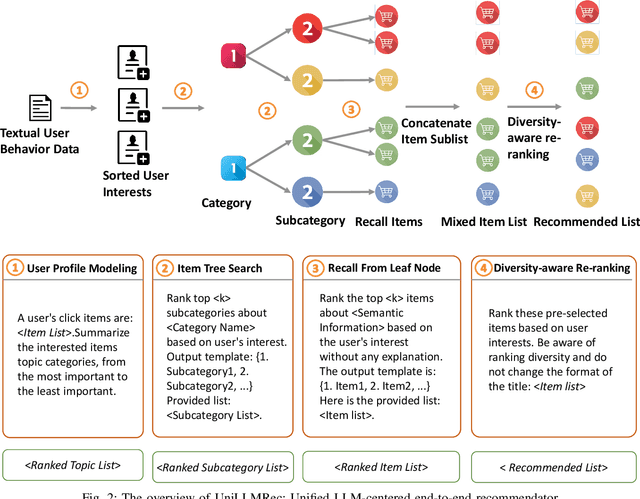
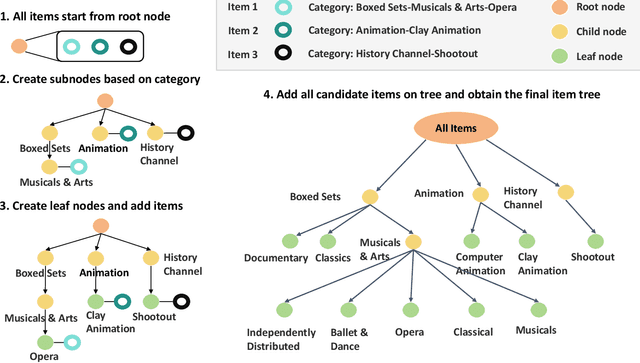
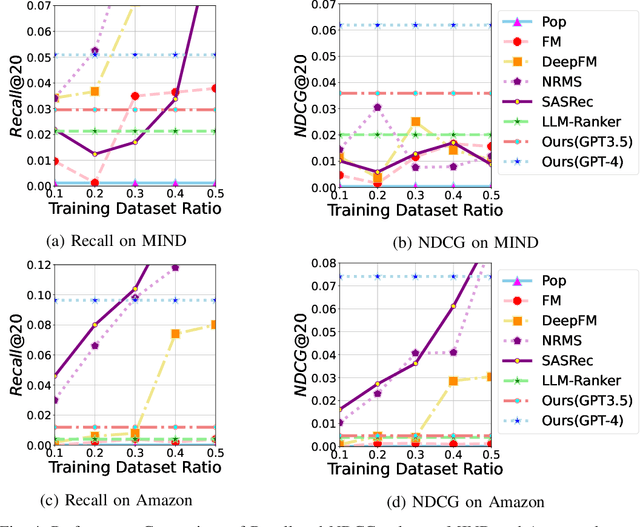
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024



The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
Confidence-Aware Multi-Field Model Calibration
Feb 27, 2024



Accurately predicting the probabilities of user feedback, such as clicks and conversions, is critical for ad ranking and bidding. However, there often exist unwanted mismatches between predicted probabilities and true likelihoods due to the shift of data distributions and intrinsic model biases. Calibration aims to address this issue by post-processing model predictions, and field-aware calibration can adjust model output on different feature field values to satisfy fine-grained advertising demands. Unfortunately, the observed samples corresponding to certain field values can be too limited to make confident calibrations, which may yield bias amplification and online disturbance. In this paper, we propose a confidence-aware multi-field calibration method, which adaptively adjusts the calibration intensity based on the confidence levels derived from sample statistics. It also utilizes multiple feature fields for joint model calibration with awareness of their importance to mitigate the data sparsity effect of a single field. Extensive offline and online experiments show the superiority of our method in boosting advertising performance and reducing prediction deviations.
Learning to Edit: Aligning LLMs with Knowledge Editing
Feb 19, 2024Knowledge editing techniques, aiming to efficiently modify a minor proportion of knowledge in large language models (LLMs) without negatively impacting performance across other inputs, have garnered widespread attention. However, existing methods predominantly rely on memorizing the updated knowledge, impeding LLMs from effectively combining the new knowledge with their inherent knowledge when answering questions. To this end, we propose a Learning to Edit (LTE) framework, focusing on teaching LLMs to apply updated knowledge into input questions, inspired by the philosophy of "Teach a man to fish." LTE features a two-phase process: (i) the Alignment Phase, which fine-tunes LLMs on a meticulously curated parallel dataset to make reliable, in-scope edits while preserving out-of-scope information and linguistic proficiency; and (ii) the Inference Phase, which employs a retrieval-based mechanism for real-time and mass knowledge editing. By comparing our approach with seven advanced baselines across four popular knowledge editing benchmarks and two LLM architectures, we demonstrate LTE's superiority in knowledge editing performance, robustness in both batch and sequential editing, minimal interference on general tasks, and rapid editing speeds. The data and code are available at https://github.com/YJiangcm/LTE.
A Unified Framework for Multi-Domain CTR Prediction via Large Language Models
Dec 20, 2023Click-Through Rate (CTR) prediction is a crucial task in online recommendation platforms as it involves estimating the probability of user engagement with advertisements or items by clicking on them. Given the availability of various services like online shopping, ride-sharing, food delivery, and professional services on commercial platforms, recommendation systems in these platforms are required to make CTR predictions across multiple domains rather than just a single domain. However, multi-domain click-through rate (MDCTR) prediction remains a challenging task in online recommendation due to the complex mutual influence between domains. Traditional MDCTR models typically encode domains as discrete identifiers, ignoring rich semantic information underlying. Consequently, they can hardly generalize to new domains. Besides, existing models can be easily dominated by some specific domains, which results in significant performance drops in the other domains (\ie the ``seesaw phenomenon``). In this paper, we propose a novel solution Uni-CTR to address the above challenges. Uni-CTR leverages a backbone Large Language Model (LLM) to learn layer-wise semantic representations that capture commonalities between domains. Uni-CTR also uses several domain-specific networks to capture the characteristics of each domain. Note that we design a masked loss strategy so that these domain-specific networks are decoupled from backbone LLM. This allows domain-specific networks to remain unchanged when incorporating new or removing domains, thereby enhancing the flexibility and scalability of the system significantly. Experimental results on three public datasets show that Uni-CTR outperforms the state-of-the-art (SOTA) MDCTR models significantly. Furthermore, Uni-CTR demonstrates remarkable effectiveness in zero-shot prediction. We have applied Uni-CTR in industrial scenarios, confirming its efficiency.
Contrastive Multi-view Framework for Customer Lifetime Value Prediction
Jun 26, 2023



Accurate customer lifetime value (LTV) prediction can help service providers optimize their marketing policies in customer-centric applications. However, the heavy sparsity of consumption events and the interference of data variance and noise obstruct LTV estimation. Many existing LTV prediction methods directly train a single-view LTV predictor on consumption samples, which may yield inaccurate and even biased knowledge extraction. In this paper, we propose a contrastive multi-view framework for LTV prediction, which is a plug-and-play solution compatible with various backbone models. It synthesizes multiple heterogeneous LTV regressors with complementary knowledge to improve model robustness and captures sample relatedness via contrastive learning to mitigate the dependency on data abundance. Concretely, we use a decomposed scheme that converts the LTV prediction problem into a combination of estimating consumption probability and payment amount. To alleviate the impact of noisy data on model learning, we propose a multi-view framework that jointly optimizes multiple types of regressors with diverse characteristics and advantages to encode and fuse comprehensive knowledge. To fully exploit the potential of limited training samples, we propose a hybrid contrastive learning method to help capture the relatedness between samples in both classification and regression tasks. We conduct extensive experiments on a real-world game LTV prediction dataset and the results validate the effectiveness of our method. We have deployed our solution online in Huawei's mobile game center and achieved 32.26% of total payment amount gains.
DualFair: Fair Representation Learning at Both Group and Individual Levels via Contrastive Self-supervision
Mar 15, 2023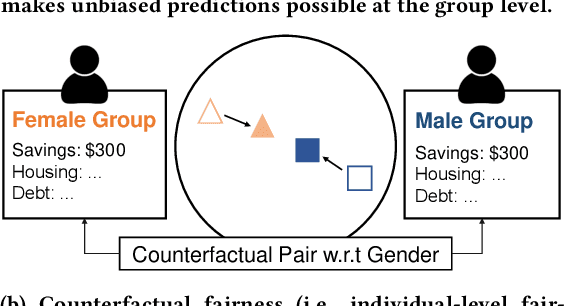
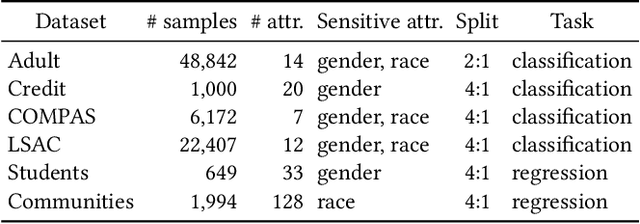
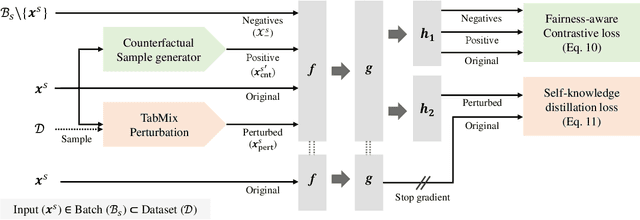
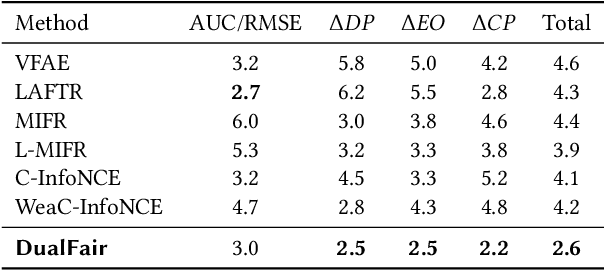
Algorithmic fairness has become an important machine learning problem, especially for mission-critical Web applications. This work presents a self-supervised model, called DualFair, that can debias sensitive attributes like gender and race from learned representations. Unlike existing models that target a single type of fairness, our model jointly optimizes for two fairness criteria - group fairness and counterfactual fairness - and hence makes fairer predictions at both the group and individual levels. Our model uses contrastive loss to generate embeddings that are indistinguishable for each protected group, while forcing the embeddings of counterfactual pairs to be similar. It then uses a self-knowledge distillation method to maintain the quality of representation for the downstream tasks. Extensive analysis over multiple datasets confirms the model's validity and further shows the synergy of jointly addressing two fairness criteria, suggesting the model's potential value in fair intelligent Web applications.