 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Make Sample-Efficient Recommender Systems
Jun 04, 2024Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Apr 29, 2024



We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$\sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Apr 28, 2024



Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based models (e.g., RIM) have achieved remarkable performance by retrieving and aggregating relevant samples. However, their inefficiency at the inference stage makes them impractical for industrial applications. To overcome this issue, this paper proposes a universal plug-and-play Retrieval-Oriented Knowledge (ROK) framework. Specifically, a knowledge base, consisting of a retrieval-oriented embedding layer and a knowledge encoder, is designed to preserve and imitate the retrieved & aggregated representations in a decomposition-reconstruction paradigm. Knowledge distillation and contrastive learning methods are utilized to optimize the knowledge base, and the learned retrieval-enhanced representations can be integrated with arbitrary CTR models in both instance-wise and feature-wise manners. Extensive experiments on three large-scale datasets show that ROK achieves competitive performance with the retrieval-based CTR models while reserving superior inference efficiency and model compatibility.
BOND: Bootstrapping From-Scratch Name Disambiguation with Multi-task Promoting
Apr 12, 2024From-scratch name disambiguation is an essential task for establishing a reliable foundation for academic platforms. It involves partitioning documents authored by identically named individuals into groups representing distinct real-life experts. Canonically, the process is divided into two decoupled tasks: locally estimating the pairwise similarities between documents followed by globally grouping these documents into appropriate clusters. However, such a decoupled approach often inhibits optimal information exchange between these intertwined tasks. Therefore, we present BOND, which bootstraps the local and global informative signals to promote each other in an end-to-end regime. Specifically, BOND harnesses local pairwise similarities to drive global clustering, subsequently generating pseudo-clustering labels. These global signals further refine local pairwise characterizations. The experimental results establish BOND's superiority, outperforming other advanced baselines by a substantial margin. Moreover, an enhanced version, BOND+, incorporating ensemble and post-match techniques, rivals the top methods in the WhoIsWho competition.
* TheWebConf 2024 (WWW '24)
Neural Image Compression with Quantization Rectifier
Mar 25, 2024



Neural image compression has been shown to outperform traditional image codecs in terms of rate-distortion performance. However, quantization introduces errors in the compression process, which can degrade the quality of the compressed image. Existing approaches address the train-test mismatch problem incurred during quantization, the random impact of quantization on the expressiveness of image features is still unsolved. This paper presents a novel quantization rectifier (QR) method for image compression that leverages image feature correlation to mitigate the impact of quantization. Our method designs a neural network architecture that predicts unquantized features from the quantized ones, preserving feature expressiveness for better image reconstruction quality. We develop a soft-to-predictive training technique to integrate QR into existing neural image codecs. In evaluation, we integrate QR into state-of-the-art neural image codecs and compare enhanced models and baselines on the widely-used Kodak benchmark. The results show consistent coding efficiency improvement by QR with a negligible increase in the running time.
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024



The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment
Mar 24, 2024The advent of deep reinforcement learning (DRL) has significantly advanced the field of robotics, particularly in the control and coordination of quadruped robots. However, the complexity of real-world tasks often necessitates the deployment of multi-robot systems capable of sophisticated interaction and collaboration. To address this need, we introduce the Multi-agent Quadruped Environment (MQE), a novel platform designed to facilitate the development and evaluation of multi-agent reinforcement learning (MARL) algorithms in realistic and dynamic scenarios. MQE emphasizes complex interactions between robots and objects, hierarchical policy structures, and challenging evaluation scenarios that reflect real-world applications. We present a series of collaborative and competitive tasks within MQE, ranging from simple coordination to complex adversarial interactions, and benchmark state-of-the-art MARL algorithms. Our findings indicate that hierarchical reinforcement learning can simplify task learning, but also highlight the need for advanced algorithms capable of handling the intricate dynamics of multi-agent interactions. MQE serves as a stepping stone towards bridging the gap between simulation and practical deployment, offering a rich environment for future research in multi-agent systems and robot learning. For open-sourced code and more details of MQE, please refer to https://ziyanx02.github.io/multiagent-quadruped-environment/ .
ERASE: Benchmarking Feature Selection Methods for Deep Recommender Systems
Mar 20, 2024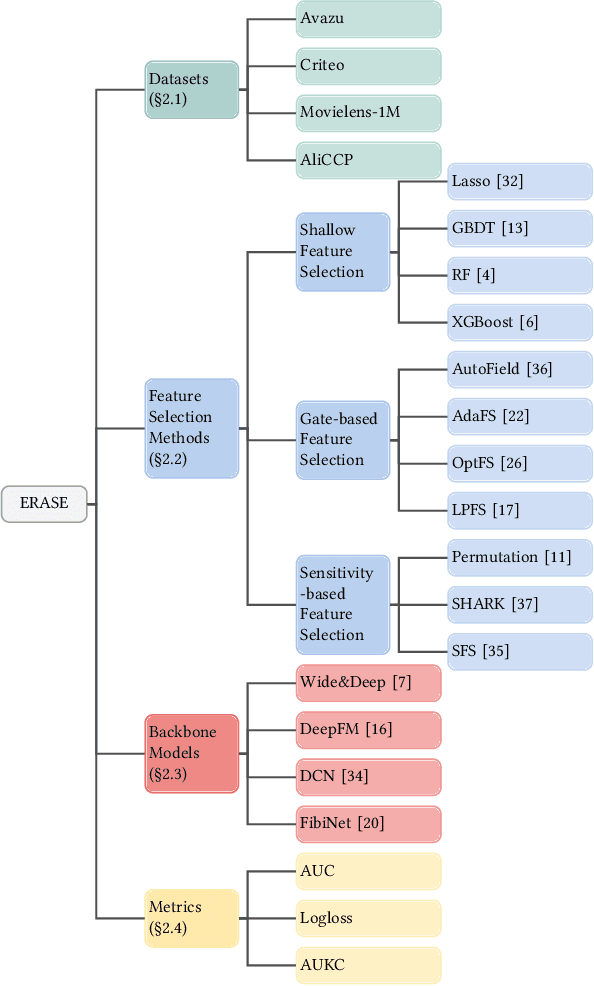
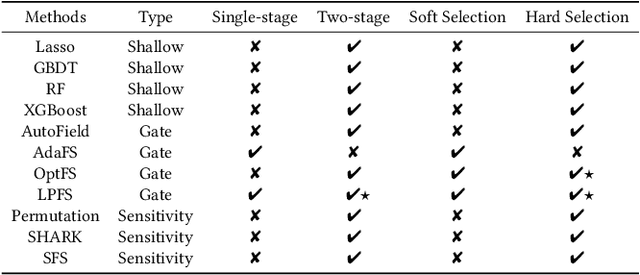
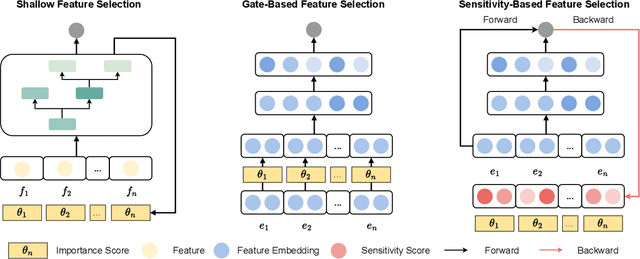
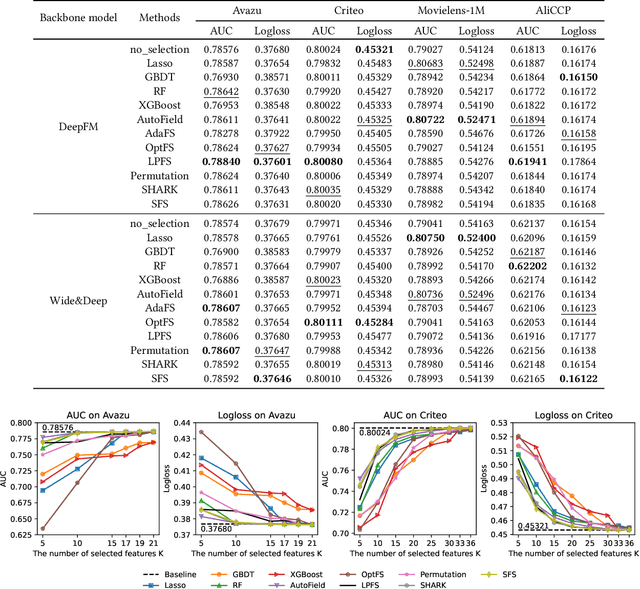
Deep Recommender Systems (DRS) are increasingly dependent on a large number of feature fields for more precise recommendations. Effective feature selection methods are consequently becoming critical for further enhancing the accuracy and optimizing storage efficiencies to align with the deployment demands. This research area, particularly in the context of DRS, is nascent and faces three core challenges. Firstly, variant experimental setups across research papers often yield unfair comparisons, obscuring practical insights. Secondly, the existing literature's lack of detailed analysis on selection attributes, based on large-scale datasets and a thorough comparison among selection techniques and DRS backbones, restricts the generalizability of findings and impedes deployment on DRS. Lastly, research often focuses on comparing the peak performance achievable by feature selection methods, an approach that is typically computationally infeasible for identifying the optimal hyperparameters and overlooks evaluating the robustness and stability of these methods. To bridge these gaps, this paper presents ERASE, a comprehensive bEnchmaRk for feAture SElection for DRS. ERASE comprises a thorough evaluation of eleven feature selection methods, covering both traditional and deep learning approaches, across four public datasets, private industrial datasets, and a real-world commercial platform, achieving significant enhancement. Our code is available online for ease of reproduction.
Considering Nonstationary within Multivariate Time Series with Variational Hierarchical Transformer for Forecasting
Mar 08, 2024



The forecasting of Multivariate Time Series (MTS) has long been an important but challenging task. Due to the non-stationary problem across long-distance time steps, previous studies primarily adopt stationarization method to attenuate the non-stationary problem of the original series for better predictability. However, existing methods always adopt the stationarized series, which ignores the inherent non-stationarity, and has difficulty in modeling MTS with complex distributions due to the lack of stochasticity. To tackle these problems, we first develop a powerful hierarchical probabilistic generative module to consider the non-stationarity and stochastic characteristics within MTS, and then combine it with transformer for a well-defined variational generative dynamic model named Hierarchical Time series Variational Transformer (HTV-Trans), which recovers the intrinsic non-stationary information into temporal dependencies. Being a powerful probabilistic model, HTV-Trans is utilized to learn expressive representations of MTS and applied to forecasting tasks. Extensive experiments on diverse datasets show the efficiency of HTV-Trans on MTS forecasting tasks
MeaCap: Memory-Augmented Zero-shot Image Captioning
Mar 06, 2024



Zero-shot image captioning (IC) without well-paired image-text data can be divided into two categories, training-free and text-only-training. Generally, these two types of methods realize zero-shot IC by integrating pretrained vision-language models like CLIP for image-text similarity evaluation and a pre-trained language model (LM) for caption generation. The main difference between them is whether using a textual corpus to train the LM. Though achieving attractive performance w.r.t. some metrics, existing methods often exhibit some common drawbacks. Training-free methods tend to produce hallucinations, while text-only-training often lose generalization capability. To move forward, in this paper, we propose a novel Memory-Augmented zero-shot image Captioning framework (MeaCap). Specifically, equipped with a textual memory, we introduce a retrieve-then-filter module to get key concepts that are highly related to the image. By deploying our proposed memory-augmented visual-related fusion score in a keywords-to-sentence LM, MeaCap can generate concept-centered captions that keep high consistency with the image with fewer hallucinations and more world-knowledge. The framework of MeaCap achieves the state-of-the-art performance on a series of zero-shot IC settings. Our code is available at https://github.com/joeyz0z/MeaCap.