 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts
May 07, 2024



Large language models (LLMs) have manifested strong ability to generate codes for productive activities. However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are predominantly oriented towards introductory tasks on algorithm and data science, insufficiently satisfying challenging requirements prevalent in real-world coding. To fill this gap, we propose NaturalCodeBench (NCB), a challenging code benchmark designed to mirror the complexity and variety of scenarios in real coding tasks. NCB comprises 402 high-quality problems in Python and Java, meticulously selected from natural user queries from online coding services, covering 6 different domains. Noting the extraordinary difficulty in creating testing cases for real-world queries, we also introduce a semi-automated pipeline to enhance the efficiency of test case construction. Comparing with manual solutions, it achieves an efficiency increase of more than 4 times. Our systematic experiments on 39 LLMs find that performance gaps on NCB between models with close HumanEval scores could still be significant, indicating a lack of focus on practical code synthesis scenarios or over-specified optimization on HumanEval. On the other hand, even the best-performing GPT-4 is still far from satisfying on NCB. The evaluation toolkit and development set are available at https://github.com/THUDM/NaturalCodeBench.
BOND: Bootstrapping From-Scratch Name Disambiguation with Multi-task Promoting
Apr 12, 2024From-scratch name disambiguation is an essential task for establishing a reliable foundation for academic platforms. It involves partitioning documents authored by identically named individuals into groups representing distinct real-life experts. Canonically, the process is divided into two decoupled tasks: locally estimating the pairwise similarities between documents followed by globally grouping these documents into appropriate clusters. However, such a decoupled approach often inhibits optimal information exchange between these intertwined tasks. Therefore, we present BOND, which bootstraps the local and global informative signals to promote each other in an end-to-end regime. Specifically, BOND harnesses local pairwise similarities to drive global clustering, subsequently generating pseudo-clustering labels. These global signals further refine local pairwise characterizations. The experimental results establish BOND's superiority, outperforming other advanced baselines by a substantial margin. Moreover, an enhanced version, BOND+, incorporating ensemble and post-match techniques, rivals the top methods in the WhoIsWho competition.
* TheWebConf 2024 (WWW '24)
Transferable and Efficient Non-Factual Content Detection via Probe Training with Offline Consistency Checking
Apr 10, 2024Detecting non-factual content is a longstanding goal to increase the trustworthiness of large language models (LLMs) generations. Current factuality probes, trained using humanannotated labels, exhibit limited transferability to out-of-distribution content, while online selfconsistency checking imposes extensive computation burden due to the necessity of generating multiple outputs. This paper proposes PINOSE, which trains a probing model on offline self-consistency checking results, thereby circumventing the need for human-annotated data and achieving transferability across diverse data distributions. As the consistency check process is offline, PINOSE reduces the computational burden of generating multiple responses by online consistency verification. Additionally, it examines various aspects of internal states prior to response decoding, contributing to more effective detection of factual inaccuracies. Experiment results on both factuality detection and question answering benchmarks show that PINOSE achieves surpassing results than existing factuality detection methods. Our code and datasets are publicly available on this anonymized repository.
AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
Apr 04, 2024Large language models (LLMs) have fueled many intelligent agent tasks, such as web navigation -- but most existing agents perform far from satisfying in real-world webpages due to three factors: (1) the versatility of actions on webpages, (2) HTML text exceeding model processing capacity, and (3) the complexity of decision-making due to the open-domain nature of web. In light of the challenge, we develop AutoWebGLM, a GPT-4-outperforming automated web navigation agent built upon ChatGLM3-6B. Inspired by human browsing patterns, we design an HTML simplification algorithm to represent webpages, preserving vital information succinctly. We employ a hybrid human-AI method to build web browsing data for curriculum training. Then, we bootstrap the model by reinforcement learning and rejection sampling to further facilitate webpage comprehension, browser operations, and efficient task decomposition by itself. For testing, we establish a bilingual benchmark -- AutoWebBench -- for real-world web browsing tasks. We evaluate AutoWebGLM across diverse web navigation benchmarks, revealing its improvements but also underlying challenges to tackle real environments. Related code, model, and data will be released at \url{https://github.com/THUDM/AutoWebGLM}.
ChatGLM-RLHF: Practices of Aligning Large Language Models with Human Feedback
Apr 03, 2024ChatGLM is a free-to-use AI service powered by the ChatGLM family of large language models (LLMs). In this paper, we present the ChatGLM-RLHF pipeline -- a reinforcement learning from human feedback (RLHF) system -- designed to enhance ChatGLM's alignment with human preferences. ChatGLM-RLHF encompasses three major components: the collection of human preference data, the training of the reward model, and the optimization of policies. Throughout the process of integrating ChatGLM-RLHF into production, we encountered and addressed several unprecedented challenges. We introduce the strategies to mitigate reward variance for stabilized large-scale training, implement model parallelism with fused gradient-descent, and design regularization constraints to avoid catastrophic forgetting in LLMs. Experiments show that ChatGLM-RLHF brings significant improvements in alignment tasks compared to the supervised fine-tuned (SFT) version of ChatGLM. For instance, it achieves on average 15\% more wins against ChatGLM-SFT in Chinese alignment tasks. The work presents our practices of aligning LLMs with human preferences, offering insights into the challenges and solutions in RLHF implementations.
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Apr 03, 2024Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLM\footnote{\url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at \url{https://github.com/THUDM/ChatGLM-Math}.
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
Apr 01, 2024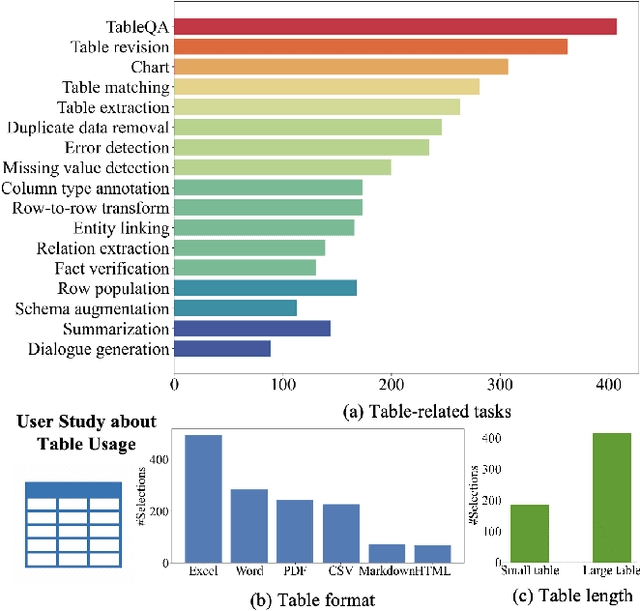

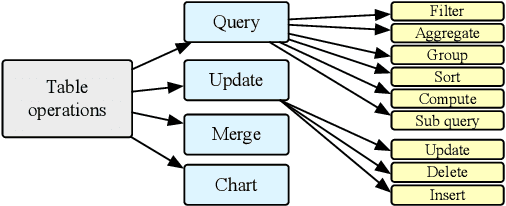
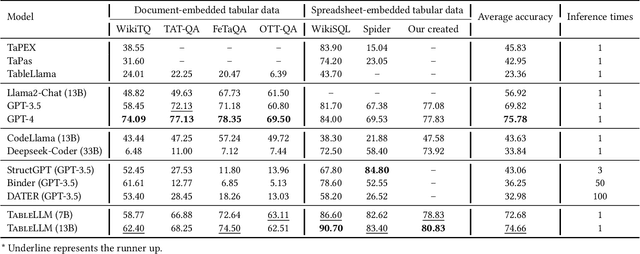
We introduce TableLLM, a robust large language model (LLM) with 13 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted a benchmark tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs. We have publicly released the model checkpoint, source code, benchmarks, and a web application for user interaction.Our codes and data are publicly available at https://github.com/TableLLM/TableLLM.
Bilateral Propagation Network for Depth Completion
Apr 01, 2024



Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.