 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Jun 06, 2024Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^\text{EM}$ and Self-Rewarding LM.
GraphAlign: Pretraining One Graph Neural Network on Multiple Graphs via Feature Alignment
Jun 05, 2024Graph self-supervised learning (SSL) holds considerable promise for mining and learning with graph-structured data. Yet, a significant challenge in graph SSL lies in the feature discrepancy among graphs across different domains. In this work, we aim to pretrain one graph neural network (GNN) on a varied collection of graphs endowed with rich node features and subsequently apply the pretrained GNN to unseen graphs. We present a general GraphAlign method that can be seamlessly integrated into the existing graph SSL framework. To align feature distributions across disparate graphs, GraphAlign designs alignment strategies of feature encoding, normalization, alongside a mixture-of-feature-expert module. Extensive experiments show that GraphAlign empowers existing graph SSL frameworks to pretrain a unified and powerful GNN across multiple graphs, showcasing performance superiority on both in-domain and out-of-domain graphs.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts
May 07, 2024



Large language models (LLMs) have manifested strong ability to generate codes for productive activities. However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are predominantly oriented towards introductory tasks on algorithm and data science, insufficiently satisfying challenging requirements prevalent in real-world coding. To fill this gap, we propose NaturalCodeBench (NCB), a challenging code benchmark designed to mirror the complexity and variety of scenarios in real coding tasks. NCB comprises 402 high-quality problems in Python and Java, meticulously selected from natural user queries from online coding services, covering 6 different domains. Noting the extraordinary difficulty in creating testing cases for real-world queries, we also introduce a semi-automated pipeline to enhance the efficiency of test case construction. Comparing with manual solutions, it achieves an efficiency increase of more than 4 times. Our systematic experiments on 39 LLMs find that performance gaps on NCB between models with close HumanEval scores could still be significant, indicating a lack of focus on practical code synthesis scenarios or over-specified optimization on HumanEval. On the other hand, even the best-performing GPT-4 is still far from satisfying on NCB. The evaluation toolkit and development set are available at https://github.com/THUDM/NaturalCodeBench.
AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
Apr 04, 2024Large language models (LLMs) have fueled many intelligent agent tasks, such as web navigation -- but most existing agents perform far from satisfying in real-world webpages due to three factors: (1) the versatility of actions on webpages, (2) HTML text exceeding model processing capacity, and (3) the complexity of decision-making due to the open-domain nature of web. In light of the challenge, we develop AutoWebGLM, a GPT-4-outperforming automated web navigation agent built upon ChatGLM3-6B. Inspired by human browsing patterns, we design an HTML simplification algorithm to represent webpages, preserving vital information succinctly. We employ a hybrid human-AI method to build web browsing data for curriculum training. Then, we bootstrap the model by reinforcement learning and rejection sampling to further facilitate webpage comprehension, browser operations, and efficient task decomposition by itself. For testing, we establish a bilingual benchmark -- AutoWebBench -- for real-world web browsing tasks. We evaluate AutoWebGLM across diverse web navigation benchmarks, revealing its improvements but also underlying challenges to tackle real environments. Related code, model, and data will be released at \url{https://github.com/THUDM/AutoWebGLM}.
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
Apr 03, 2024Large language models (LLMs) have shown excellent mastering of human language, but still struggle in real-world applications that require mathematical problem-solving. While many strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems.In this work, we tailor the Self-Critique pipeline, which addresses the challenge in the feedback learning stage of LLM alignment. We first train a general Math-Critique model from the LLM itself to provide feedback signals. Then, we sequentially employ rejective fine-tuning and direct preference optimization over the LLM's own generations for data collection. Based on ChatGLM3-32B, we conduct a series of experiments on both academic and our newly created challenging dataset, MathUserEval. Results show that our pipeline significantly enhances the LLM's mathematical problem-solving while still improving its language ability, outperforming LLMs that could be two times larger. Related techniques have been deployed to ChatGLM\footnote{\url{https://chatglm.cn}}, an online serving LLM. Related evaluation dataset and scripts are released at \url{https://github.com/THUDM/ChatGLM-Math}.
ChatGLM-RLHF: Practices of Aligning Large Language Models with Human Feedback
Apr 03, 2024ChatGLM is a free-to-use AI service powered by the ChatGLM family of large language models (LLMs). In this paper, we present the ChatGLM-RLHF pipeline -- a reinforcement learning from human feedback (RLHF) system -- designed to enhance ChatGLM's alignment with human preferences. ChatGLM-RLHF encompasses three major components: the collection of human preference data, the training of the reward model, and the optimization of policies. Throughout the process of integrating ChatGLM-RLHF into production, we encountered and addressed several unprecedented challenges. We introduce the strategies to mitigate reward variance for stabilized large-scale training, implement model parallelism with fused gradient-descent, and design regularization constraints to avoid catastrophic forgetting in LLMs. Experiments show that ChatGLM-RLHF brings significant improvements in alignment tasks compared to the supervised fine-tuned (SFT) version of ChatGLM. For instance, it achieves on average 15\% more wins against ChatGLM-SFT in Chinese alignment tasks. The work presents our practices of aligning LLMs with human preferences, offering insights into the challenges and solutions in RLHF implementations.
Extensive Self-Contrast Enables Feedback-Free Language Model Alignment
Mar 31, 2024Reinforcement learning from human feedback (RLHF) has been a central technique for recent large language model (LLM) alignment. However, its heavy dependence on costly human or LLM-as-Judge preference feedback could stymie its wider applications. In this work, we introduce Self-Contrast, a feedback-free large language model alignment method via exploiting extensive self-generated negatives. With only supervised fine-tuning (SFT) targets, Self-Contrast leverages the LLM itself to generate massive diverse candidates, and harnesses a pre-trained embedding model to filter multiple negatives according to text similarity. Theoretically, we illustrate that in this setting, merely scaling negative responses can still effectively approximate situations with more balanced positive and negative preference annotations. Our experiments with direct preference optimization (DPO) on three datasets show that, Self-Contrast could consistently outperform SFT and standard DPO training by large margins. And as the number of self-generated negatives increases, the performance of Self-Contrast continues to grow. Code and data are available at https://github.com/THUDM/Self-Contrast.
Understanding Emergent Abilities of Language Models from the Loss Perspective
Mar 30, 2024Recent studies have put into question the belief that emergent abilities in language models are exclusive to large models. This skepticism arises from two observations: 1) smaller models can also exhibit high performance on emergent abilities and 2) there is doubt on the discontinuous metrics used to measure these abilities. In this paper, we propose to study emergent abilities in the lens of pre-training loss, instead of model size or training compute. We demonstrate that the models with the same pre-training loss, but different model and data sizes, generate the same performance on various downstream tasks. We also discover that a model exhibits emergent abilities on certain tasks -- regardless of the continuity of metrics -- when its pre-training loss falls below a specific threshold. Before reaching this threshold, its performance remains at the level of random guessing. This inspires us to redefine emergent abilities as those that manifest in models with lower pre-training losses, highlighting that these abilities cannot be predicted by merely extrapolating the performance trends of models with higher pre-training losses.
Open-World Semi-Supervised Learning for Node Classification
Mar 18, 2024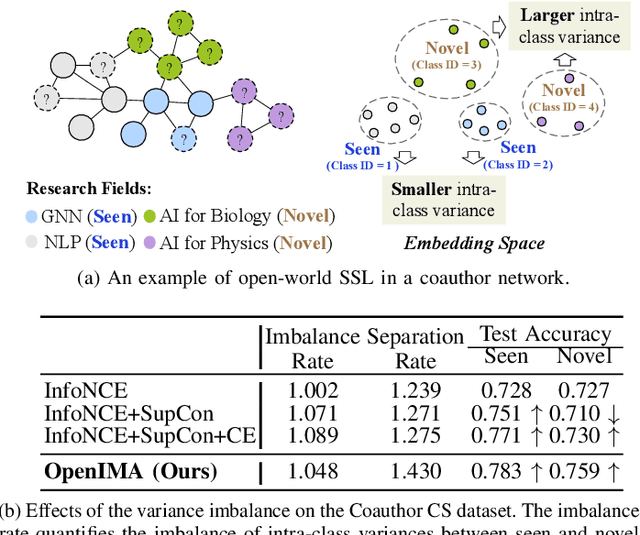
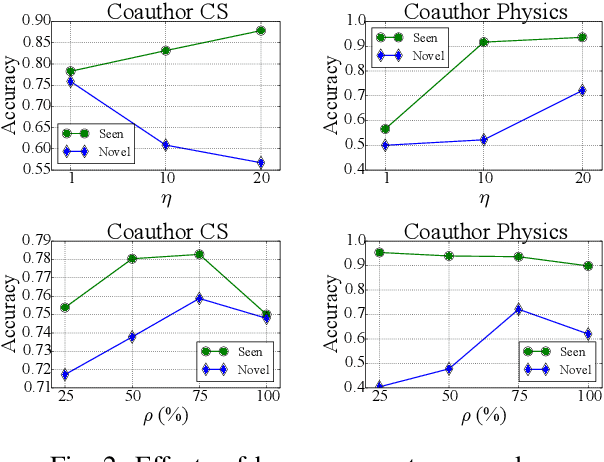
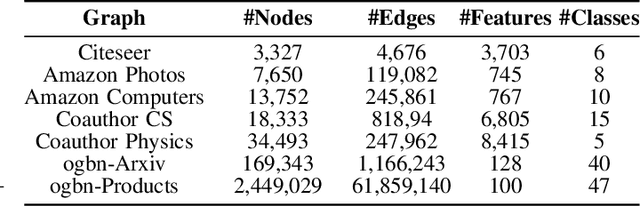
Open-world semi-supervised learning (Open-world SSL) for node classification, that classifies unlabeled nodes into seen classes or multiple novel classes, is a practical but under-explored problem in the graph community. As only seen classes have human labels, they are usually better learned than novel classes, and thus exhibit smaller intra-class variances within the embedding space (named as imbalance of intra-class variances between seen and novel classes). Based on empirical and theoretical analysis, we find the variance imbalance can negatively impact the model performance. Pre-trained feature encoders can alleviate this issue via producing compact representations for novel classes. However, creating general pre-trained encoders for various types of graph data has been proven to be challenging. As such, there is a demand for an effective method that does not rely on pre-trained graph encoders. In this paper, we propose an IMbalance-Aware method named OpenIMA for Open-world semi-supervised node classification, which trains the node classification model from scratch via contrastive learning with bias-reduced pseudo labels. Extensive experiments on seven popular graph benchmarks demonstrate the effectiveness of OpenIMA, and the source code has been available on GitHub.