 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB Guided ToF Imaging System: A Survey of Deep Learning-based Methods
May 16, 2024



Integrating an RGB camera into a ToF imaging system has become a significant technique for perceiving the real world. The RGB guided ToF imaging system is crucial to several applications, including face anti-spoofing, saliency detection, and trajectory prediction. Depending on the distance of the working range, the implementation schemes of the RGB guided ToF imaging systems are different. Specifically, ToF sensors with a uniform field of illumination, which can output dense depth but have low resolution, are typically used for close-range measurements. In contrast, LiDARs, which emit laser pulses and can only capture sparse depth, are usually employed for long-range detection. In the two cases, depth quality improvement for RGB guided ToF imaging corresponds to two sub-tasks: guided depth super-resolution and guided depth completion. In light of the recent significant boost to the field provided by deep learning, this paper comprehensively reviews the works related to RGB guided ToF imaging, including network structures, learning strategies, evaluation metrics, benchmark datasets, and objective functions. Besides, we present quantitative comparisons of state-of-the-art methods on widely used benchmark datasets. Finally, we discuss future trends and the challenges in real applications for further research.
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Apr 29, 2024Compressing images at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. Existing extreme image compression methods generally suffer from heavy compression artifacts or low-fidelity reconstructions. To address this problem, we propose a novel extreme image compression framework that combines compressive VAEs and pre-trained text-to-image diffusion models in an end-to-end manner. Specifically, we introduce a latent feature-guided compression module based on compressive VAEs. This module compresses images and initially decodes the compressed information into content variables. To enhance the alignment between content variables and the diffusion space, we introduce external guidance to modulate intermediate feature maps. Subsequently, we develop a conditional diffusion decoding module that leverages pre-trained diffusion models to further decode these content variables. To preserve the generative capability of pre-trained diffusion models, we keep their parameters fixed and use a control module to inject content information. We also design a space alignment loss to provide sufficient constraints for the latent feature-guided compression module. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in terms of both visual performance and image fidelity at extremely low bitrates.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
An Accurate and Real-time Relative Pose Estimation from Triple Point-line Images by Decoupling Rotation and Translation
Mar 18, 2024



Line features are valid complements for point features in man-made environments. 3D-2D constraints provided by line features have been widely used in Visual Odometry (VO) and Structure-from-Motion (SfM) systems. However, how to accurately solve three-view relative motion only with 2D observations of points and lines in real time has not been fully explored. In this paper, we propose a novel three-view pose solver based on rotation-translation decoupled estimation. First, a high-precision rotation estimation method based on normal vector coplanarity constraints that consider the uncertainty of observations is proposed, which can be solved by Levenberg-Marquardt (LM) algorithm efficiently. Second, a robust linear translation constraint that minimizes the degree of the rotation components and feature observation components in equations is elaborately designed for estimating translations accurately. Experiments on synthetic data and real-world data show that the proposed approach improves both rotation and translation accuracy compared to the classical trifocal-tensor-based method and the state-of-the-art two-view algorithm in outdoor and indoor environments.
VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
Mar 16, 2024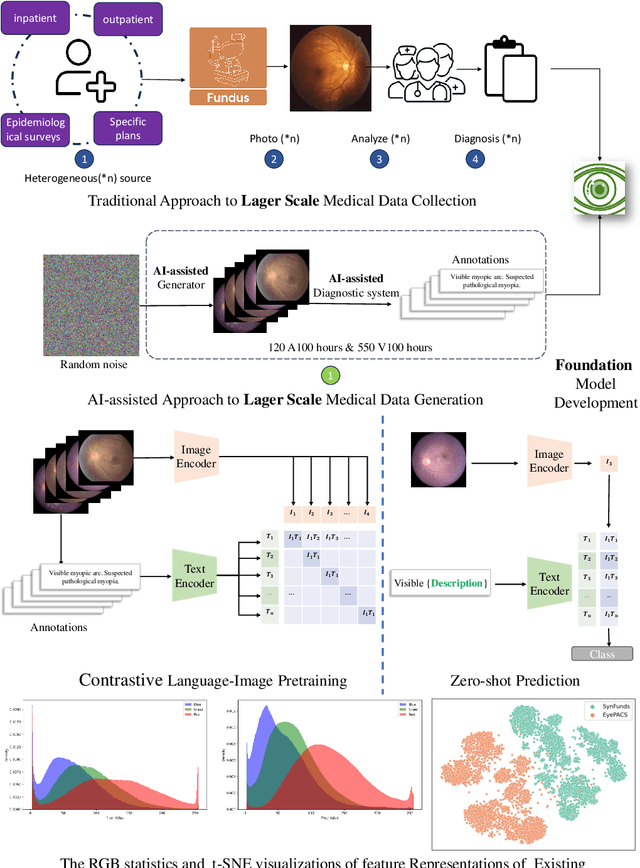
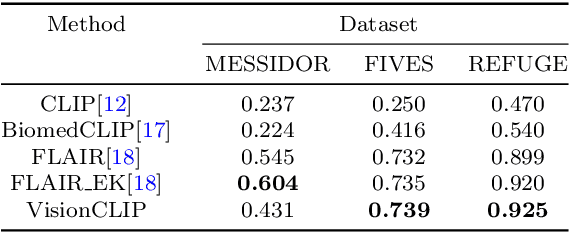
Generalist foundation model has ushered in newfound capabilities in medical domain. However, the contradiction between the growing demand for high-quality annotated data with patient privacy continues to intensify. The utilization of medical artificial intelligence generated content (Med-AIGC) as an inexhaustible resource repository arises as a potential solution to address the aforementioned challenge. Here we harness 1 million open-source synthetic fundus images paired with natural language descriptions, to curate an ethical language-image foundation model for retina image analysis named VisionCLIP. VisionCLIP achieves competitive performance on three external datasets compared with the existing method pre-trained on real-world data in a zero-shot fashion. The employment of artificially synthetic images alongside corresponding textual data for training enables the medical foundation model to successfully assimilate knowledge of disease symptomatology, thereby circumventing potential breaches of patient confidentiality.
Leveraging Multimodal Fusion for Enhanced Diagnosis of Multiple Retinal Diseases in Ultra-wide OCTA
Nov 17, 2023



Ultra-wide optical coherence tomography angiography (UW-OCTA) is an emerging imaging technique that offers significant advantages over traditional OCTA by providing an exceptionally wide scanning range of up to 24 x 20 $mm^{2}$, covering both the anterior and posterior regions of the retina. However, the currently accessible UW-OCTA datasets suffer from limited comprehensive hierarchical information and corresponding disease annotations. To address this limitation, we have curated the pioneering M3OCTA dataset, which is the first multimodal (i.e., multilayer), multi-disease, and widest field-of-view UW-OCTA dataset. Furthermore, the effective utilization of multi-layer ultra-wide ocular vasculature information from UW-OCTA remains underdeveloped. To tackle this challenge, we propose the first cross-modal fusion framework that leverages multi-modal information for diagnosing multiple diseases. Through extensive experiments conducted on our openly available M3OCTA dataset, we demonstrate the effectiveness and superior performance of our method, both in fixed and varying modalities settings. The construction of the M3OCTA dataset, the first multimodal OCTA dataset encompassing multiple diseases, aims to advance research in the ophthalmic image analysis community.
Higher or Lower: Challenges in Object based SLAM
Oct 20, 2023



Simultaneous localization and mapping, as a fundamental task in computer vision, has gained higher demands for performance in recent years due to the rapid development of autonomous driving and unmanned aerial vehicles. Traditional SLAM algorithms highly rely on basic geometry features such as points and lines, which are susceptible to environment. Conversely, higher-level object features offer richer information that is crucial for enhancing the overall performance of the framework. However, the effective utilization of object features necessitates careful consideration of various challenges, including complexity and process velocity. Given the advantages and disadvantages of both high-level object feature and low-level geometry features, it becomes essential to make informed choices within the SLAM framework. Taking these factors into account, this paper provides a thorough comparison between geometry features and object features, analyzes the current mainstream application methods of object features in SLAM frameworks, and presents a comprehensive overview of the main challenges involved in object-based SLAM.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023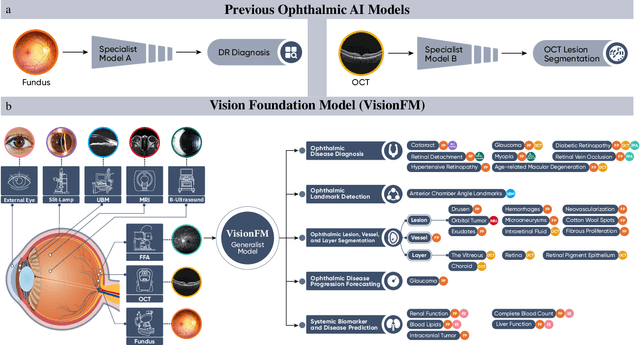
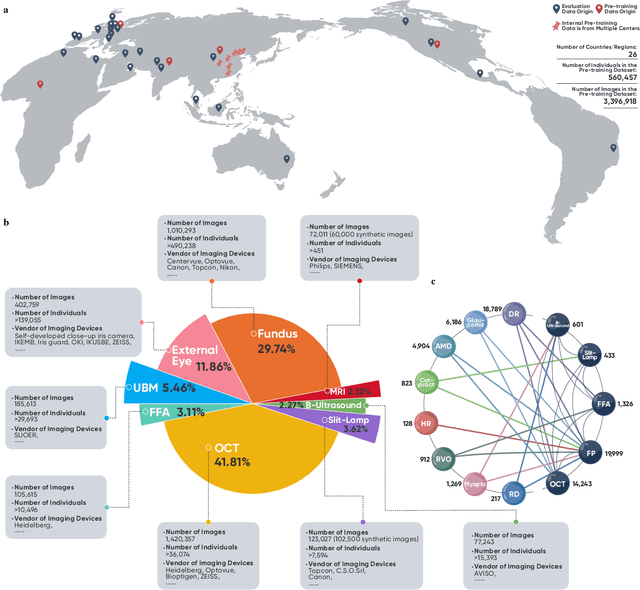
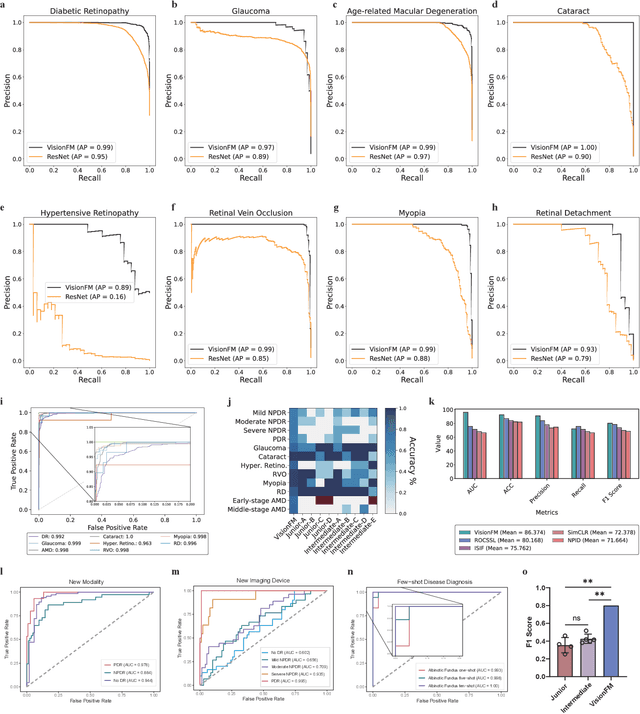
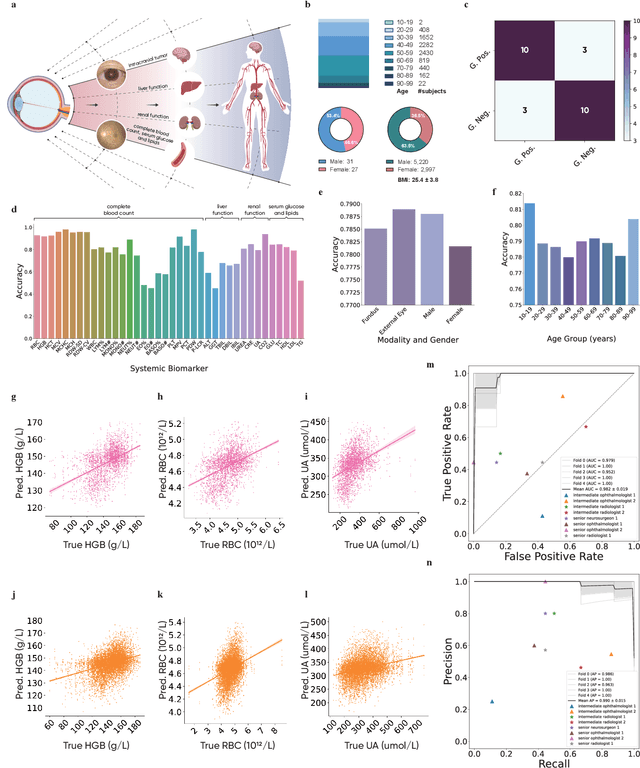
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
CauDR: A Causality-inspired Domain Generalization Framework for Fundus-based Diabetic Retinopathy Grading
Sep 27, 2023



Diabetic retinopathy (DR) is the most common diabetic complication, which usually leads to retinal damage, vision loss, and even blindness. A computer-aided DR grading system has a significant impact on helping ophthalmologists with rapid screening and diagnosis. Recent advances in fundus photography have precipitated the development of novel retinal imaging cameras and their subsequent implementation in clinical practice. However, most deep learning-based algorithms for DR grading demonstrate limited generalization across domains. This inferior performance stems from variance in imaging protocols and devices inducing domain shifts. We posit that declining model performance between domains arises from learning spurious correlations in the data. Incorporating do-operations from causality analysis into model architectures may mitigate this issue and improve generalizability. Specifically, a novel universal structural causal model (SCM) was proposed to analyze spurious correlations in fundus imaging. Building on this, a causality-inspired diabetic retinopathy grading framework named CauDR was developed to eliminate spurious correlations and achieve more generalizable DR diagnostics. Furthermore, existing datasets were reorganized into 4DR benchmark for DG scenario. Results demonstrate the effectiveness and the state-of-the-art (SOTA) performance of CauDR.
Generalist Vision Foundation Models for Medical Imaging: A Case Study of Segment Anything Model on Zero-Shot Medical Segmentation
Apr 25, 2023



We examine the recent Segment Anything Model (SAM) on medical images, and report both quantitative and qualitative zero-shot segmentation results on nine medical image segmentation benchmarks, covering various imaging modalities, such as optical coherence tomography (OCT), magnetic resonance imaging (MRI), and computed tomography (CT), as well as different applications including dermatology, ophthalmology, and radiology. Our experiments reveal that while SAM demonstrates stunning segmentation performance on images from the general domain, for those out-of-distribution images, e.g., medical images, its zero-shot segmentation performance is still limited. Furthermore, SAM demonstrated varying zero-shot segmentation performance across different unseen medical domains. For example, it had a 0.8704 mean Dice score on segmenting under-bruch's membrane layer of retinal OCT, whereas the segmentation accuracy drops to 0.0688 when segmenting retinal pigment epithelium. For certain structured targets, e.g., blood vessels, the zero-shot segmentation of SAM completely failed, whereas a simple fine-tuning of it with small amount of data could lead to remarkable improvements of the segmentation quality. Our study indicates the versatility of generalist vision foundation models on solving specific tasks in medical imaging, and their great potential to achieve desired performance through fine-turning and eventually tackle the challenges of accessing large diverse medical datasets and the complexity of medical domains.