 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the best approximation by finite Gaussian mixtures
Apr 13, 2024We consider the problem of approximating a general Gaussian location mixture by finite mixtures. The minimum order of finite mixtures that achieve a prescribed accuracy (measured by various $f$-divergences) is determined within constant factors for the family of mixing distributions with compactly support or appropriate assumptions on the tail probability including subgaussian and subexponential. While the upper bound is achieved using the technique of local moment matching, the lower bound is established by relating the best approximation error to the low-rank approximation of certain trigonometric moment matrices, followed by a refined spectral analysis of their minimum eigenvalue. In the case of Gaussian mixing distributions, this result corrects a previous lower bound in [Allerton Conference 48 (2010) 620-628].
An Accurate and Real-time Relative Pose Estimation from Triple Point-line Images by Decoupling Rotation and Translation
Mar 18, 2024



Line features are valid complements for point features in man-made environments. 3D-2D constraints provided by line features have been widely used in Visual Odometry (VO) and Structure-from-Motion (SfM) systems. However, how to accurately solve three-view relative motion only with 2D observations of points and lines in real time has not been fully explored. In this paper, we propose a novel three-view pose solver based on rotation-translation decoupled estimation. First, a high-precision rotation estimation method based on normal vector coplanarity constraints that consider the uncertainty of observations is proposed, which can be solved by Levenberg-Marquardt (LM) algorithm efficiently. Second, a robust linear translation constraint that minimizes the degree of the rotation components and feature observation components in equations is elaborately designed for estimating translations accurately. Experiments on synthetic data and real-world data show that the proposed approach improves both rotation and translation accuracy compared to the classical trifocal-tensor-based method and the state-of-the-art two-view algorithm in outdoor and indoor environments.
NocPlace: Nocturnal Visual Place Recognition Using Generative and Inherited Knowledge Transfer
Feb 27, 2024



Visual Place Recognition (VPR) is crucial in computer vision, aiming to retrieve database images similar to a query image from an extensive collection of known images. However, like many vision-related tasks, learning-based VPR often experiences a decline in performance during nighttime due to the scarcity of nighttime images. Specifically, VPR needs to address the cross-domain problem of night-to-day rather than just the issue of a single nighttime domain. In response to these issues, we present NocPlace, which leverages a generated large-scale, multi-view, nighttime VPR dataset to embed resilience against dazzling lights and extreme darkness in the learned global descriptor. Firstly, we establish a day-night urban scene dataset called NightCities, capturing diverse nighttime scenarios and lighting variations across 60 cities globally. Following this, an unpaired image-to-image translation network is trained on this dataset. Using this trained translation network, we process an existing VPR dataset, thereby obtaining its nighttime version. The NocPlace is then fine-tuned using night-style images, the original labels, and descriptors inherited from the Daytime VPR model. Comprehensive experiments on various nighttime VPR test sets reveal that NocPlace considerably surpasses previous state-of-the-art methods.
ViSTec: Video Modeling for Sports Technique Recognition and Tactical Analysis
Feb 25, 2024The immense popularity of racket sports has fueled substantial demand in tactical analysis with broadcast videos. However, existing manual methods require laborious annotation, and recent attempts leveraging video perception models are limited to low-level annotations like ball trajectories, overlooking tactics that necessitate an understanding of stroke techniques. State-of-the-art action segmentation models also struggle with technique recognition due to frequent occlusions and motion-induced blurring in racket sports videos. To address these challenges, We propose ViSTec, a Video-based Sports Technique recognition model inspired by human cognition that synergizes sparse visual data with rich contextual insights. Our approach integrates a graph to explicitly model strategic knowledge in stroke sequences and enhance technique recognition with contextual inductive bias. A two-stage action perception model is jointly trained to align with the contextual knowledge in the graph. Experiments demonstrate that our method outperforms existing models by a significant margin. Case studies with experts from the Chinese national table tennis team validate our model's capacity to automate analysis for technical actions and tactical strategies. More details are available at: https://ViSTec2024.github.io/.
Optimal score estimation via empirical Bayes smoothing
Feb 12, 2024We study the problem of estimating the score function of an unknown probability distribution $\rho^*$ from $n$ independent and identically distributed observations in $d$ dimensions. Assuming that $\rho^*$ is subgaussian and has a Lipschitz-continuous score function $s^*$, we establish the optimal rate of $\tilde \Theta(n^{-\frac{2}{d+4}})$ for this estimation problem under the loss function $\|\hat s - s^*\|^2_{L^2(\rho^*)}$ that is commonly used in the score matching literature, highlighting the curse of dimensionality where sample complexity for accurate score estimation grows exponentially with the dimension $d$. Leveraging key insights in empirical Bayes theory as well as a new convergence rate of smoothed empirical distribution in Hellinger distance, we show that a regularized score estimator based on a Gaussian kernel attains this rate, shown optimal by a matching minimax lower bound. We also discuss the implication of our theory on the sample complexity of score-based generative models.
MuGI: Enhancing Information Retrieval through Multi-Text Generation Intergration with Large Language Models
Jan 12, 2024



Large Language Models (LLMs) have emerged as a pivotal force in language technology. Their robust reasoning capabilities and expansive knowledge repositories have enabled exceptional zero-shot generalization abilities across various facets of the natural language processing field, including information retrieval (IR). In this paper, we conduct an in-depth investigation into the utility of documents generated by LLMs for IR. We introduce a simple yet effective framework, Multi-Text Generation Integration (MuGI), to augment existing IR methodologies. Specifically, we prompt LLMs to generate multiple pseudo references and integrate with query for retrieval. The training-free MuGI model eclipses existing query expansion strategies, setting a new standard in sparse retrieval. It outstrips supervised counterparts like ANCE and DPR, achieving a notable over 18% enhancement in BM25 on the TREC DL dataset and a 7.5% increase on BEIR. Through MuGI, we have forged a rapid and high-fidelity re-ranking pipeline. This allows a relatively small 110M parameter retriever to surpass the performance of larger 3B models in in-domain evaluations, while also bridging the gap in out-of-distribution situations. We release our code and all generated references at https://github.com/lezhang7/Retrieval_MuGI.
Depth Insight -- Contribution of Different Features to Indoor Single-image Depth Estimation
Nov 16, 2023Depth estimation from a single image is a challenging problem in computer vision because binocular disparity or motion information is absent. Whereas impressive performances have been reported in this area recently using end-to-end trained deep neural architectures, as to what cues in the images that are being exploited by these black box systems is hard to know. To this end, in this work, we quantify the relative contributions of the known cues of depth in a monocular depth estimation setting using an indoor scene data set. Our work uses feature extraction techniques to relate the single features of shape, texture, colour and saturation, taken in isolation, to predict depth. We find that the shape of objects extracted by edge detection substantially contributes more than others in the indoor setting considered, while the other features also have contributions in varying degrees. These insights will help optimise depth estimation models, boosting their accuracy and robustness. They promise to broaden the practical applications of vision-based depth estimation. The project code is attached to the supplementary material and will be published on GitHub.
Collaboration and Transition: Distilling Item Transitions into Multi-Query Self-Attention for Sequential Recommendation
Nov 02, 2023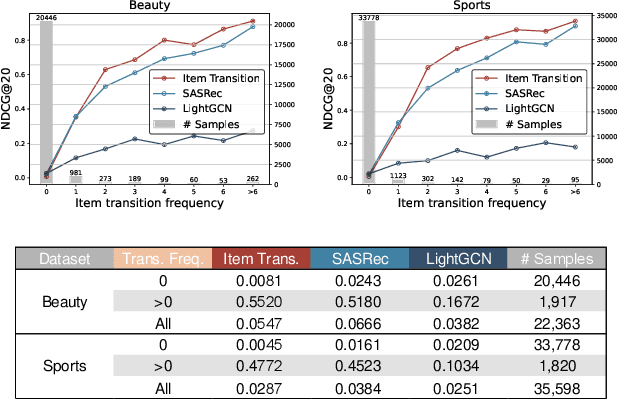

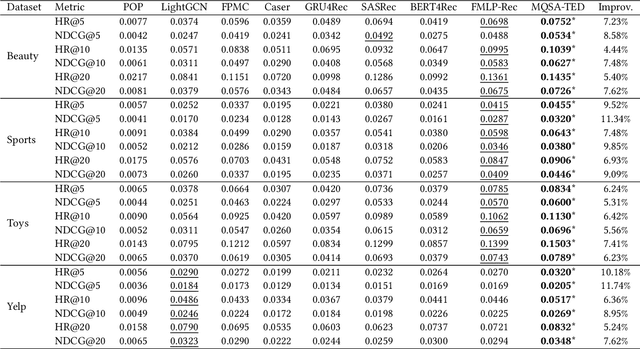
Modern recommender systems employ various sequential modules such as self-attention to learn dynamic user interests. However, these methods are less effective in capturing collaborative and transitional signals within user interaction sequences. First, the self-attention architecture uses the embedding of a single item as the attention query, which is inherently challenging to capture collaborative signals. Second, these methods typically follow an auto-regressive framework, which is unable to learn global item transition patterns. To overcome these limitations, we propose a new method called Multi-Query Self-Attention with Transition-Aware Embedding Distillation (MQSA-TED). First, we propose an $L$-query self-attention module that employs flexible window sizes for attention queries to capture collaborative signals. In addition, we introduce a multi-query self-attention method that balances the bias-variance trade-off in modeling user preferences by combining long and short-query self-attentions. Second, we develop a transition-aware embedding distillation module that distills global item-to-item transition patterns into item embeddings, which enables the model to memorize and leverage transitional signals and serves as a calibrator for collaborative signals. Experimental results on four real-world datasets show the superiority of our proposed method over state-of-the-art sequential recommendation methods.
MoqaGPT : Zero-Shot Multi-modal Open-domain Question Answering with Large Language Model
Oct 20, 2023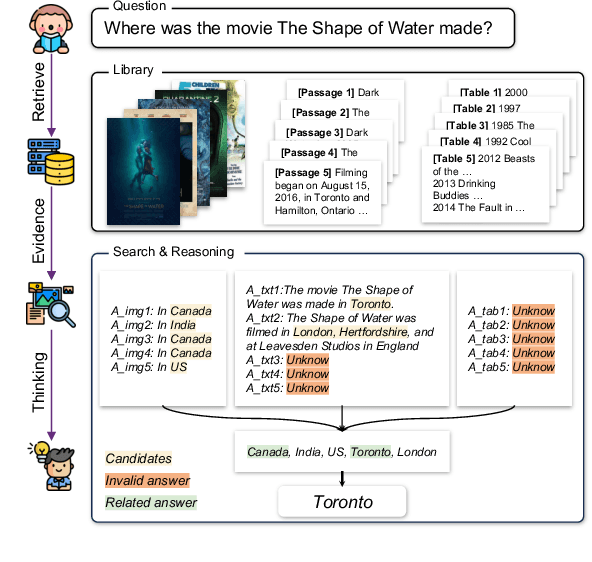

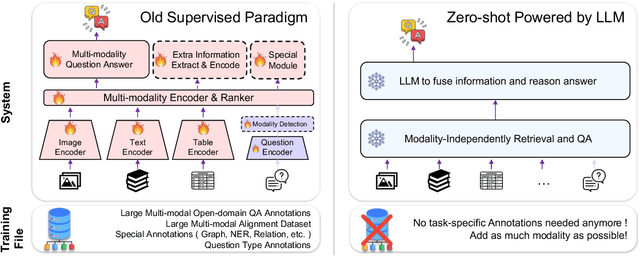
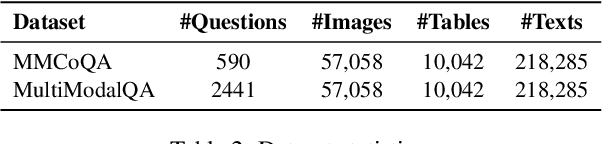
Multi-modal open-domain question answering typically requires evidence retrieval from databases across diverse modalities, such as images, tables, passages, etc. Even Large Language Models (LLMs) like GPT-4 fall short in this task. To enable LLMs to tackle the task in a zero-shot manner, we introduce MoqaGPT, a straightforward and flexible framework. Using a divide-and-conquer strategy that bypasses intricate multi-modality ranking, our framework can accommodate new modalities and seamlessly transition to new models for the task. Built upon LLMs, MoqaGPT retrieves and extracts answers from each modality separately, then fuses this multi-modal information using LLMs to produce a final answer. Our methodology boosts performance on the MMCoQA dataset, improving F1 by +37.91 points and EM by +34.07 points over the supervised baseline. On the MultiModalQA dataset, MoqaGPT surpasses the zero-shot baseline, improving F1 by 9.5 points and EM by 10.1 points, and significantly closes the gap with supervised methods. Our codebase is available at https://github.com/lezhang7/MOQAGPT.
MatSpectNet: Material Segmentation Network with Domain-Aware and Physically-Constrained Hyperspectral Reconstruction
Aug 06, 2023



Achieving accurate material segmentation for 3-channel RGB images is challenging due to the considerable variation in a material's appearance. Hyperspectral images, which are sets of spectral measurements sampled at multiple wavelengths, theoretically offer distinct information for material identification, as variations in intensity of electromagnetic radiation reflected by a surface depend on the material composition of a scene. However, existing hyperspectral datasets are impoverished regarding the number of images and material categories for the dense material segmentation task, and collecting and annotating hyperspectral images with a spectral camera is prohibitively expensive. To address this, we propose a new model, the MatSpectNet to segment materials with recovered hyperspectral images from RGB images. The network leverages the principles of colour perception in modern cameras to constrain the reconstructed hyperspectral images and employs the domain adaptation method to generalise the hyperspectral reconstruction capability from a spectral recovery dataset to material segmentation datasets. The reconstructed hyperspectral images are further filtered using learned response curves and enhanced with human perception. The performance of MatSpectNet is evaluated on the LMD dataset as well as the OpenSurfaces dataset. Our experiments demonstrate that MatSpectNet attains a 1.60% increase in average pixel accuracy and a 3.42% improvement in mean class accuracy compared with the most recent publication. The project code is attached to the supplementary material and will be published on GitHub.