 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs In-Context Learning Sufficient for Instruction Following in LLMs?
May 30, 2024In-context learning (ICL) allows LLMs to learn from examples without changing their weights, which is a particularly promising capability for long-context LLMs that can potentially learn from many examples. Recently, Lin et al. (2024) proposed URIAL, a method using only three in-context examples to align base LLMs, achieving non-trivial instruction following performance. In this work, we show that, while effective, ICL alignment with URIAL still underperforms compared to instruction fine-tuning on established benchmarks such as MT-Bench and AlpacaEval 2.0 (LC), especially with more capable base LMs. Unlike for tasks such as classification, translation, or summarization, adding more ICL demonstrations for long-context LLMs does not systematically improve instruction following performance. To address this limitation, we derive a greedy selection approach for ICL examples that noticeably improves performance, yet without bridging the gap to instruction fine-tuning. Finally, we provide a series of ablation studies to better understand the reasons behind the remaining gap, and we show how some aspects of ICL depart from the existing knowledge and are specific to the instruction tuning setting. Overall, our work advances the understanding of ICL as an alignment technique. We provide our code at https://github.com/tml-epfl/icl-alignment.
Camera Relocalization in Shadow-free Neural Radiance Fields
May 23, 2024Camera relocalization is a crucial problem in computer vision and robotics. Recent advancements in neural radiance fields (NeRFs) have shown promise in synthesizing photo-realistic images. Several works have utilized NeRFs for refining camera poses, but they do not account for lighting changes that can affect scene appearance and shadow regions, causing a degraded pose optimization process. In this paper, we propose a two-staged pipeline that normalizes images with varying lighting and shadow conditions to improve camera relocalization. We implement our scene representation upon a hash-encoded NeRF which significantly boosts up the pose optimization process. To account for the noisy image gradient computing problem in grid-based NeRFs, we further propose a re-devised truncated dynamic low-pass filter (TDLF) and a numerical gradient averaging technique to smoothen the process. Experimental results on several datasets with varying lighting conditions demonstrate that our method achieves state-of-the-art results in camera relocalization under varying lighting conditions. Code and data will be made publicly available.
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
May 05, 2024Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids
May 03, 2024



Despite significant advancements in Neural Radiance Fields (NeRFs), the renderings may still suffer from aliasing and blurring artifacts, since it remains a fundamental challenge to effectively and efficiently characterize anisotropic areas induced by the cone-casting procedure. This paper introduces a Ripmap-Encoded Platonic Solid representation to precisely and efficiently featurize 3D anisotropic areas, achieving high-fidelity anti-aliasing renderings. Central to our approach are two key components: Platonic Solid Projection and Ripmap encoding. The Platonic Solid Projection factorizes the 3D space onto the unparalleled faces of a certain Platonic solid, such that the anisotropic 3D areas can be projected onto planes with distinguishable characterization. Meanwhile, each face of the Platonic solid is encoded by the Ripmap encoding, which is constructed by anisotropically pre-filtering a learnable feature grid, to enable featurzing the projected anisotropic areas both precisely and efficiently by the anisotropic area-sampling. Extensive experiments on both well-established synthetic datasets and a newly captured real-world dataset demonstrate that our Rip-NeRF attains state-of-the-art rendering quality, particularly excelling in the fine details of repetitive structures and textures, while maintaining relatively swift training times.
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
FlexiFilm: Long Video Generation with Flexible Conditions
Apr 29, 2024Generating long and consistent videos has emerged as a significant yet challenging problem. While most existing diffusion-based video generation models, derived from image generation models, demonstrate promising performance in generating short videos, their simple conditioning mechanism and sampling strategy-originally designed for image generation-cause severe performance degradation when adapted to long video generation. This results in prominent temporal inconsistency and overexposure. Thus, in this work, we introduce FlexiFilm, a new diffusion model tailored for long video generation. Our framework incorporates a temporal conditioner to establish a more consistent relationship between generation and multi-modal conditions, and a resampling strategy to tackle overexposure. Empirical results demonstrate FlexiFilm generates long and consistent videos, each over 30 seconds in length, outperforming competitors in qualitative and quantitative analyses. Project page: https://y-ichen.github.io/FlexiFilm-Page/
Block-Map-Based Localization in Large-Scale Environment
Apr 28, 2024Accurate localization is an essential technology for the flexible navigation of robots in large-scale environments. Both SLAM-based and map-based localization will increase the computing load due to the increase in map size, which will affect downstream tasks such as robot navigation and services. To this end, we propose a localization system based on Block Maps (BMs) to reduce the computational load caused by maintaining large-scale maps. Firstly, we introduce a method for generating block maps and the corresponding switching strategies, ensuring that the robot can estimate the state in large-scale environments by loading local map information. Secondly, global localization according to Branch-and-Bound Search (BBS) in the 3D map is introduced to provide the initial pose. Finally, a graph-based optimization method is adopted with a dynamic sliding window that determines what factors are being marginalized whether a robot is exposed to a BM or switching to another one, which maintains the accuracy and efficiency of pose tracking. Comparison experiments are performed on publicly available large-scale datasets. Results show that the proposed method can track the robot pose even though the map scale reaches more than 6 kilometers, while efficient and accurate localization is still guaranteed on NCLT and M2DGR.
Idea-2-3D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Apr 05, 2024In this paper, we pursue a novel 3D AIGC setting: generating 3D content from IDEAs. The definition of an IDEA is the composition of multimodal inputs including text, image, and 3D models. To our knowledge, this challenging and appealing 3D AIGC setting has not been studied before. We propose the novel framework called Idea-2-3D to achieve this goal, which consists of three agents based upon large multimodel models (LMMs) and several existing algorithmic tools for them to invoke. Specifically, these three LMM-based agents are prompted to do the jobs of prompt generation, model selection and feedback reflection. They work in a cycle that involves both mutual collaboration and criticism. Note that this cycle is done in a fully automatic manner, without any human intervention. The framework then outputs a text prompt to generate 3D models that well align with input IDEAs. We show impressive 3D AIGC results that are beyond any previous methods can achieve. For quantitative comparisons, we construct caption-based baselines using a whole bunch of state-of-the-art 3D AIGC models and demonstrate Idea-2-3D out-performs significantly. In 94.2% of cases, Idea-2-3D meets users' requirements, marking a degree of match between IDEA and 3D models that is 2.3 times higher than baselines. Moreover, in 93.5% of the cases, users agreed that Idea-2-3D was better than baselines. Codes, data and models will made publicly available.
PreAfford: Universal Affordance-Based Pre-Grasping for Diverse Objects and Environments
Apr 04, 2024Robotic manipulation of ungraspable objects with two-finger grippers presents significant challenges due to the paucity of graspable features, while traditional pre-grasping techniques, which rely on repositioning objects and leveraging external aids like table edges, lack the adaptability across object categories and scenes. Addressing this, we introduce PreAfford, a novel pre-grasping planning framework that utilizes a point-level affordance representation and a relay training approach to enhance adaptability across a broad range of environments and object types, including those previously unseen. Demonstrated on the ShapeNet-v2 dataset, PreAfford significantly improves grasping success rates by 69% and validates its practicality through real-world experiments. This work offers a robust and adaptable solution for manipulating ungraspable objects.
P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
Mar 29, 2024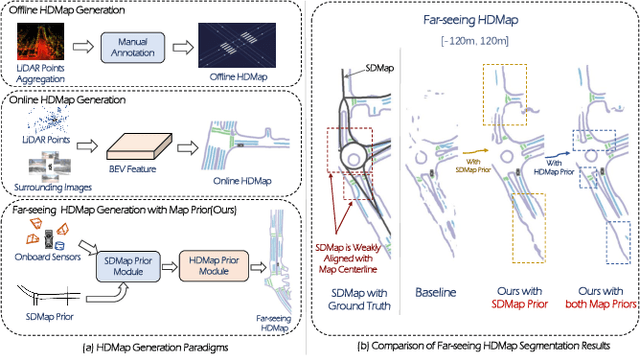
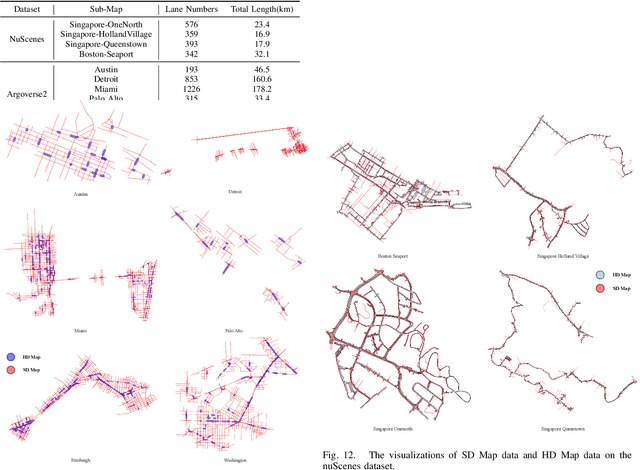
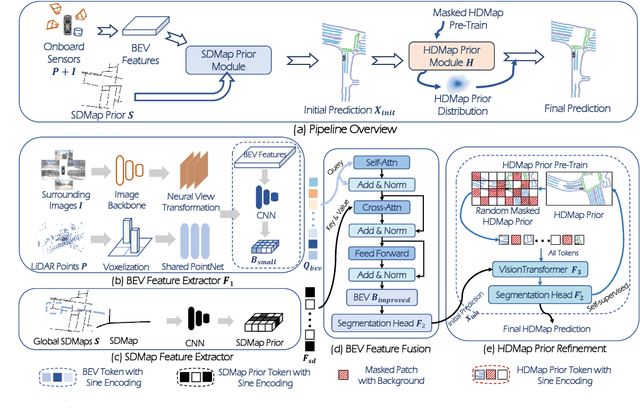
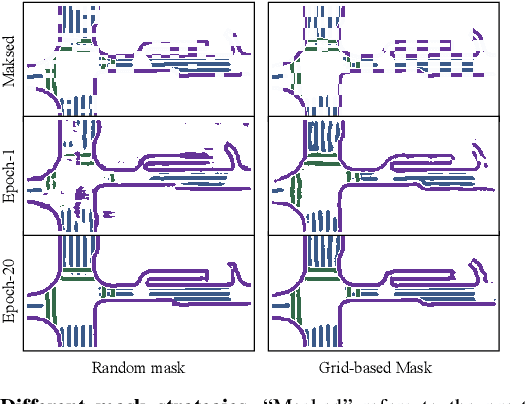
Autonomous vehicles are gradually entering city roads today, with the help of high-definition maps (HDMaps). However, the reliance on HDMaps prevents autonomous vehicles from stepping into regions without this expensive digital infrastructure. This fact drives many researchers to study online HDMap generation algorithms, but the performance of these algorithms at far regions is still unsatisfying. We present P-MapNet, in which the letter P highlights the fact that we focus on incorporating map priors to improve model performance. Specifically, we exploit priors in both SDMap and HDMap. On one hand, we extract weakly aligned SDMap from OpenStreetMap, and encode it as an additional conditioning branch. Despite the misalignment challenge, our attention-based architecture adaptively attends to relevant SDMap skeletons and significantly improves performance. On the other hand, we exploit a masked autoencoder to capture the prior distribution of HDMap, which can serve as a refinement module to mitigate occlusions and artifacts. We benchmark on the nuScenes and Argoverse2 datasets. Through comprehensive experiments, we show that: (1) our SDMap prior can improve online map generation performance, using both rasterized (by up to $+18.73$ $\rm mIoU$) and vectorized (by up to $+8.50$ $\rm mAP$) output representations. (2) our HDMap prior can improve map perceptual metrics by up to $6.34\%$. (3) P-MapNet can be switched into different inference modes that covers different regions of the accuracy-efficiency trade-off landscape. (4) P-MapNet is a far-seeing solution that brings larger improvements on longer ranges. Codes and models are publicly available at https://jike5.github.io/P-MapNet.