 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Idea-2-3D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Apr 05, 2024In this paper, we pursue a novel 3D AIGC setting: generating 3D content from IDEAs. The definition of an IDEA is the composition of multimodal inputs including text, image, and 3D models. To our knowledge, this challenging and appealing 3D AIGC setting has not been studied before. We propose the novel framework called Idea-2-3D to achieve this goal, which consists of three agents based upon large multimodel models (LMMs) and several existing algorithmic tools for them to invoke. Specifically, these three LMM-based agents are prompted to do the jobs of prompt generation, model selection and feedback reflection. They work in a cycle that involves both mutual collaboration and criticism. Note that this cycle is done in a fully automatic manner, without any human intervention. The framework then outputs a text prompt to generate 3D models that well align with input IDEAs. We show impressive 3D AIGC results that are beyond any previous methods can achieve. For quantitative comparisons, we construct caption-based baselines using a whole bunch of state-of-the-art 3D AIGC models and demonstrate Idea-2-3D out-performs significantly. In 94.2% of cases, Idea-2-3D meets users' requirements, marking a degree of match between IDEA and 3D models that is 2.3 times higher than baselines. Moreover, in 93.5% of the cases, users agreed that Idea-2-3D was better than baselines. Codes, data and models will made publicly available.
SDSTrack: Self-Distillation Symmetric Adapter Learning for Multi-Modal Visual Object Tracking
Mar 28, 2024


Multimodal Visual Object Tracking (VOT) has recently gained significant attention due to its robustness. Early research focused on fully fine-tuning RGB-based trackers, which was inefficient and lacked generalized representation due to the scarcity of multimodal data. Therefore, recent studies have utilized prompt tuning to transfer pre-trained RGB-based trackers to multimodal data. However, the modality gap limits pre-trained knowledge recall, and the dominance of the RGB modality persists, preventing the full utilization of information from other modalities. To address these issues, we propose a novel symmetric multimodal tracking framework called SDSTrack. We introduce lightweight adaptation for efficient fine-tuning, which directly transfers the feature extraction ability from RGB to other domains with a small number of trainable parameters and integrates multimodal features in a balanced, symmetric manner. Furthermore, we design a complementary masked patch distillation strategy to enhance the robustness of trackers in complex environments, such as extreme weather, poor imaging, and sensor failure. Extensive experiments demonstrate that SDSTrack outperforms state-of-the-art methods in various multimodal tracking scenarios, including RGB+Depth, RGB+Thermal, and RGB+Event tracking, and exhibits impressive results in extreme conditions. Our source code is available at https://github.com/hoqolo/SDSTrack.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 2024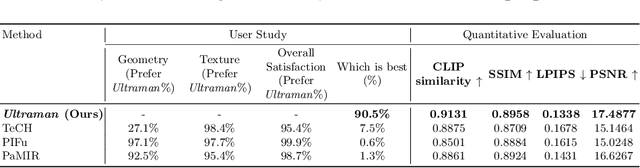
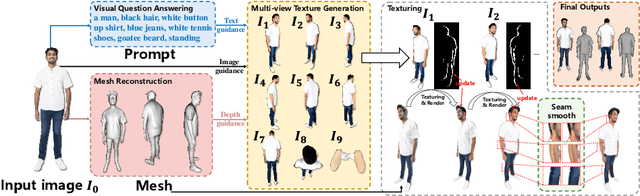
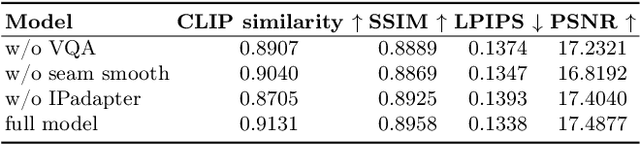

3D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
$\infty$Bench: Extending Long Context Evaluation Beyond 100K Tokens
Feb 24, 2024



Processing and reasoning over long contexts is crucial for many practical applications of Large Language Models (LLMs), such as document comprehension and agent construction. Despite recent strides in making LLMs process contexts with more than 100K tokens, there is currently a lack of a standardized benchmark to evaluate this long-context capability. Existing public benchmarks typically focus on contexts around 10K tokens, limiting the assessment and comparison of LLMs in processing longer contexts. In this paper, we propose $\infty$Bench, the first LLM benchmark featuring an average data length surpassing 100K tokens. $\infty$Bench comprises synthetic and realistic tasks spanning diverse domains, presented in both English and Chinese. The tasks in $\infty$Bench are designed to require well understanding of long dependencies in contexts, and make simply retrieving a limited number of passages from contexts not sufficient for these tasks. In our experiments, based on $\infty$Bench, we evaluate the state-of-the-art proprietary and open-source LLMs tailored for processing long contexts. The results indicate that existing long context LLMs still require significant advancements to effectively process 100K+ context. We further present three intriguing analyses regarding the behavior of LLMs processing long context.
MaxQ: Multi-Axis Query for N:M Sparsity Network
Dec 12, 2023N:M sparsity has received increasing attention due to its remarkable performance and latency trade-off compared with structured and unstructured sparsity. However, existing N:M sparsity methods do not differentiate the relative importance of weights among blocks and leave important weights underappreciated. Besides, they directly apply N:M sparsity to the whole network, which will cause severe information loss. Thus, they are still sub-optimal. In this paper, we propose an efficient and effective Multi-Axis Query methodology, dubbed as MaxQ, to rectify these problems. During the training, MaxQ employs a dynamic approach to generate soft N:M masks, considering the weight importance across multiple axes. This method enhances the weights with more importance and ensures more effective updates. Meanwhile, a sparsity strategy that gradually increases the percentage of N:M weight blocks is applied, which allows the network to heal from the pruning-induced damage progressively. During the runtime, the N:M soft masks can be precomputed as constants and folded into weights without causing any distortion to the sparse pattern and incurring additional computational overhead. Comprehensive experiments demonstrate that MaxQ achieves consistent improvements across diverse CNN architectures in various computer vision tasks, including image classification, object detection and instance segmentation. For ResNet50 with 1:16 sparse pattern, MaxQ can achieve 74.6\% top-1 accuracy on ImageNet and improve by over 2.8\% over the state-of-the-art.
Soulstyler: Using Large Language Model to Guide Image Style Transfer for Target Object
Nov 29, 2023



Image style transfer occupies an important place in both computer graphics and computer vision. However, most current methods require reference to stylized images and cannot individually stylize specific objects. To overcome this limitation, we propose the "Soulstyler" framework, which allows users to guide the stylization of specific objects in an image through simple textual descriptions. We introduce a large language model to parse the text and identify stylization goals and specific styles. Combined with a CLIP-based semantic visual embedding encoder, the model understands and matches text and image content. We also introduce a novel localized text-image block matching loss that ensures that style transfer is performed only on specified target objects, while non-target regions remain in their original style. Experimental results demonstrate that our model is able to accurately perform style transfer on target objects according to textual descriptions without affecting the style of background regions. Our code will be available at https://github.com/yisuanwang/Soulstyler.
Asca: less audio data is more insightful
Sep 23, 2023



Audio recognition in specialized areas such as birdsong and submarine acoustics faces challenges in large-scale pre-training due to the limitations in available samples imposed by sampling environments and specificity requirements. While the Transformer model excels in audio recognition, its dependence on vast amounts of data becomes restrictive in resource-limited settings. Addressing this, we introduce the Audio Spectrogram Convolution Attention (ASCA) based on CoAtNet, integrating a Transformer-convolution hybrid architecture, novel network design, and attention techniques, further augmented with data enhancement and regularization strategies. On the BirdCLEF2023 and AudioSet(Balanced), ASCA achieved accuracies of 81.2% and 35.1%, respectively, significantly outperforming competing methods. The unique structure of our model enriches output, enabling generalization across various audio detection tasks. Our code can be found at https://github.com/LeeCiang/ASCA.
ZhuJiu: A Multi-dimensional, Multi-faceted Chinese Benchmark for Large Language Models
Aug 28, 2023



The unprecedented performance of large language models (LLMs) requires comprehensive and accurate evaluation. We argue that for LLMs evaluation, benchmarks need to be comprehensive and systematic. To this end, we propose the ZhuJiu benchmark, which has the following strengths: (1) Multi-dimensional ability coverage: We comprehensively evaluate LLMs across 7 ability dimensions covering 51 tasks. Especially, we also propose a new benchmark that focuses on knowledge ability of LLMs. (2) Multi-faceted evaluation methods collaboration: We use 3 different yet complementary evaluation methods to comprehensively evaluate LLMs, which can ensure the authority and accuracy of the evaluation results. (3) Comprehensive Chinese benchmark: ZhuJiu is the pioneering benchmark that fully assesses LLMs in Chinese, while also providing equally robust evaluation abilities in English. (4) Avoiding potential data leakage: To avoid data leakage, we construct evaluation data specifically for 37 tasks. We evaluate 10 current mainstream LLMs and conduct an in-depth discussion and analysis of their results. The ZhuJiu benchmark and open-participation leaderboard are publicly released at http://www.zhujiu-benchmark.com/ and we also provide a demo video at https://youtu.be/qypkJ89L1Ic.
IncreLoRA: Incremental Parameter Allocation Method for Parameter-Efficient Fine-tuning
Aug 23, 2023With the increasing size of pre-trained language models (PLMs), fine-tuning all the parameters in the model is not efficient, especially when there are a large number of downstream tasks, which incur significant training and storage costs. Many parameter-efficient fine-tuning (PEFT) approaches have been proposed, among which, Low-Rank Adaptation (LoRA) is a representative approach that injects trainable rank decomposition matrices into every target module. Yet LoRA ignores the importance of parameters in different modules. To address this problem, many works have been proposed to prune the parameters of LoRA. However, under limited training conditions, the upper bound of the rank of the pruned parameter matrix is still affected by the preset values. We, therefore, propose IncreLoRA, an incremental parameter allocation method that adaptively adds trainable parameters during training based on the importance scores of each module. This approach is different from the pruning method as it is not limited by the initial number of training parameters, and each parameter matrix has a higher rank upper bound for the same training overhead. We conduct extensive experiments on GLUE to demonstrate the effectiveness of IncreLoRA. The results show that our method owns higher parameter efficiency, especially when under the low-resource settings where our method significantly outperforms the baselines. Our code is publicly available.