 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.
On the Maximal Local Disparity of Fairness-Aware Classifiers
Jun 05, 2024Fairness has become a crucial aspect in the development of trustworthy machine learning algorithms. Current fairness metrics to measure the violation of demographic parity have the following drawbacks: (i) the average difference of model predictions on two groups cannot reflect their distribution disparity, and (ii) the overall calculation along all possible predictions conceals the extreme local disparity at or around certain predictions. In this work, we propose a novel fairness metric called Maximal Cumulative ratio Disparity along varying Predictions' neighborhood (MCDP), for measuring the maximal local disparity of the fairness-aware classifiers. To accurately and efficiently calculate the MCDP, we develop a provably exact and an approximate calculation algorithm that greatly reduces the computational complexity with low estimation error. We further propose a bi-level optimization algorithm using a differentiable approximation of the MCDP for improving the algorithmic fairness. Extensive experiments on both tabular and image datasets validate that our fair training algorithm can achieve superior fairness-accuracy trade-offs.
Attaining Human`s Desirable Outcomes in Human-AI Interaction via Structural Causal Games
May 26, 2024In human-AI interaction, a prominent goal is to attain human`s desirable outcome with the assistance of AI agents, which can be ideally delineated as a problem of seeking the optimal Nash Equilibrium that matches the human`s desirable outcome. However, reaching the outcome is usually challenging due to the existence of multiple Nash Equilibria that are related to the assisting task but do not correspond to the human`s desirable outcome. To tackle this issue, we employ a theoretical framework called structural causal game (SCG) to formalize the human-AI interactive process. Furthermore, we introduce a strategy referred to as pre-policy intervention on the SCG to steer AI agents towards attaining the human`s desirable outcome. In more detail, a pre-policy is learned as a generalized intervention to guide the agents` policy selection, under a transparent and interpretable procedure determined by the SCG. To make the framework practical, we propose a reinforcement learning-like algorithm to search out this pre-policy. The proposed algorithm is tested in both gridworld environments and realistic dialogue scenarios with large language models, demonstrating its adaptability in a broader class of problems and potential effectiveness in real-world situations.
Explainable Few-shot Knowledge Tracing
May 23, 2024Knowledge tracing (KT), aiming to mine students' mastery of knowledge by their exercise records and predict their performance on future test questions, is a critical task in educational assessment. While researchers achieved tremendous success with the rapid development of deep learning techniques, current knowledge tracing tasks fall into the cracks from real-world teaching scenarios. Relying heavily on extensive student data and solely predicting numerical performances differs from the settings where teachers assess students' knowledge state from limited practices and provide explanatory feedback. To fill this gap, we explore a new task formulation: Explainable Few-shot Knowledge Tracing. By leveraging the powerful reasoning and generation abilities of large language models (LLMs), we then propose a cognition-guided framework that can track the student knowledge from a few student records while providing natural language explanations. Experimental results from three widely used datasets show that LLMs can perform comparable or superior to competitive deep knowledge tracing methods. We also discuss potential directions and call for future improvements in relevant topics.
Be Aware of the Neighborhood Effect: Modeling Selection Bias under Interference
Apr 30, 2024



Selection bias in recommender system arises from the recommendation process of system filtering and the interactive process of user selection. Many previous studies have focused on addressing selection bias to achieve unbiased learning of the prediction model, but ignore the fact that potential outcomes for a given user-item pair may vary with the treatments assigned to other user-item pairs, named neighborhood effect. To fill the gap, this paper formally formulates the neighborhood effect as an interference problem from the perspective of causal inference and introduces a treatment representation to capture the neighborhood effect. On this basis, we propose a novel ideal loss that can be used to deal with selection bias in the presence of neighborhood effect. We further develop two new estimators for estimating the proposed ideal loss. We theoretically establish the connection between the proposed and previous debiasing methods ignoring the neighborhood effect, showing that the proposed methods can achieve unbiased learning when both selection bias and neighborhood effect are present, while the existing methods are biased. Extensive semi-synthetic and real-world experiments are conducted to demonstrate the effectiveness of the proposed methods.
Debiased Collaborative Filtering with Kernel-Based Causal Balancing
Apr 30, 2024Debiased collaborative filtering aims to learn an unbiased prediction model by removing different biases in observational datasets. To solve this problem, one of the simple and effective methods is based on the propensity score, which adjusts the observational sample distribution to the target one by reweighting observed instances. Ideally, propensity scores should be learned with causal balancing constraints. However, existing methods usually ignore such constraints or implement them with unreasonable approximations, which may affect the accuracy of the learned propensity scores. To bridge this gap, in this paper, we first analyze the gaps between the causal balancing requirements and existing methods such as learning the propensity with cross-entropy loss or manually selecting functions to balance. Inspired by these gaps, we propose to approximate the balancing functions in reproducing kernel Hilbert space and demonstrate that, based on the universal property and representer theorem of kernel functions, the causal balancing constraints can be better satisfied. Meanwhile, we propose an algorithm that adaptively balances the kernel function and theoretically analyze the generalization error bound of our methods. We conduct extensive experiments to demonstrate the effectiveness of our methods, and to promote this research direction, we have released our project at https://github.com/haoxuanli-pku/ICLR24-Kernel-Balancing.
MetaCoCo: A New Few-Shot Classification Benchmark with Spurious Correlation
Apr 30, 2024Out-of-distribution (OOD) problems in few-shot classification (FSC) occur when novel classes sampled from testing distributions differ from base classes drawn from training distributions, which considerably degrades the performance of deep learning models deployed in real-world applications. Recent studies suggest that the OOD problems in FSC mainly including: (a) cross-domain few-shot classification (CD-FSC) and (b) spurious-correlation few-shot classification (SC-FSC). Specifically, CD-FSC occurs when a classifier learns transferring knowledge from base classes drawn from seen training distributions but recognizes novel classes sampled from unseen testing distributions. In contrast, SC-FSC arises when a classifier relies on non-causal features (or contexts) that happen to be correlated with the labels (or concepts) in base classes but such relationships no longer hold during the model deployment. Despite CD-FSC has been extensively studied, SC-FSC remains understudied due to lack of the corresponding evaluation benchmarks. To this end, we present Meta Concept Context (MetaCoCo), a benchmark with spurious-correlation shifts collected from real-world scenarios. Moreover, to quantify the extent of spurious-correlation shifts of the presented MetaCoCo, we further propose a metric by using CLIP as a pre-trained vision-language model. Extensive experiments on the proposed benchmark are performed to evaluate the state-of-the-art methods in FSC, cross-domain shifts, and self-supervised learning. The experimental results show that the performance of the existing methods degrades significantly in the presence of spurious-correlation shifts. We open-source all codes of our benchmark and hope that the proposed MetaCoCo can facilitate future research on spurious-correlation shifts problems in FSC. The code is available at: https://github.com/remiMZ/MetaCoCo-ICLR24.
Wasserstein Dependent Graph Attention Network for Collaborative Filtering with Uncertainty
Apr 09, 2024Collaborative filtering (CF) is an essential technique in recommender systems that provides personalized recommendations by only leveraging user-item interactions. However, most CF methods represent users and items as fixed points in the latent space, lacking the ability to capture uncertainty. In this paper, we propose a novel approach, called the Wasserstein dependent Graph ATtention network (W-GAT), for collaborative filtering with uncertainty. We utilize graph attention network and Wasserstein distance to address the limitations of LightGCN and Kullback-Leibler divergence (KL) divergence to learn Gaussian embedding for each user and item. Additionally, our method incorporates Wasserstein-dependent mutual information further to increase the similarity between positive pairs and to tackle the challenges induced by KL divergence. Experimental results on three benchmark datasets show the superiority of W-GAT compared to several representative baselines. Extensive experimental analysis validates the effectiveness of W-GAT in capturing uncertainty by modeling the range of user preferences and categories associated with items.
Contrastive Balancing Representation Learning for Heterogeneous Dose-Response Curves Estimation
Mar 21, 2024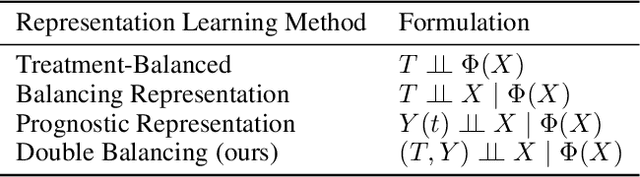
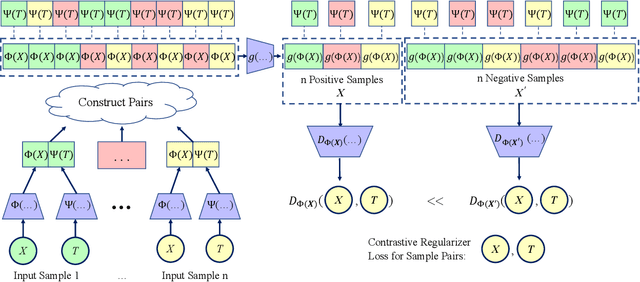
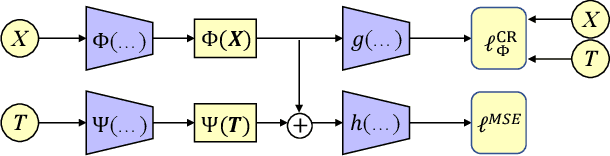
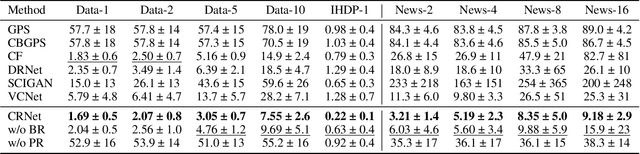
Estimating the individuals' potential response to varying treatment doses is crucial for decision-making in areas such as precision medicine and management science. Most recent studies predict counterfactual outcomes by learning a covariate representation that is independent of the treatment variable. However, such independence constraints neglect much of the covariate information that is useful for counterfactual prediction, especially when the treatment variables are continuous. To tackle the above issue, in this paper, we first theoretically demonstrate the importance of the balancing and prognostic representations for unbiased estimation of the heterogeneous dose-response curves, that is, the learned representations are constrained to satisfy the conditional independence between the covariates and both of the treatment variables and the potential responses. Based on this, we propose a novel Contrastive balancing Representation learning Network using a partial distance measure, called CRNet, for estimating the heterogeneous dose-response curves without losing the continuity of treatments. Extensive experiments are conducted on synthetic and real-world datasets demonstrating that our proposal significantly outperforms previous methods.
Pareto-Optimal Estimation and Policy Learning on Short-term and Long-term Treatment Effects
Mar 12, 2024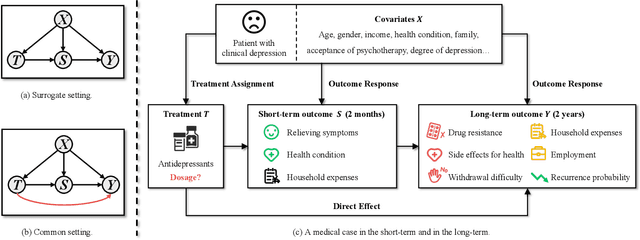
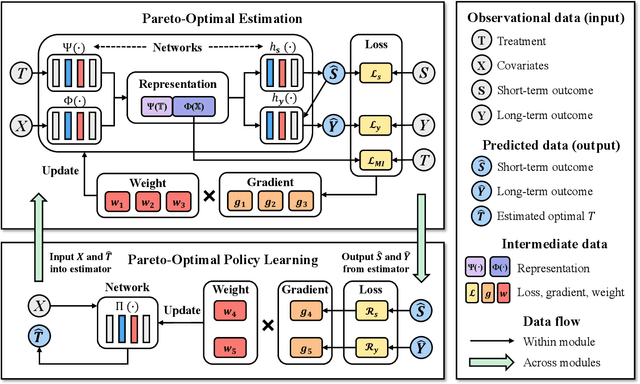
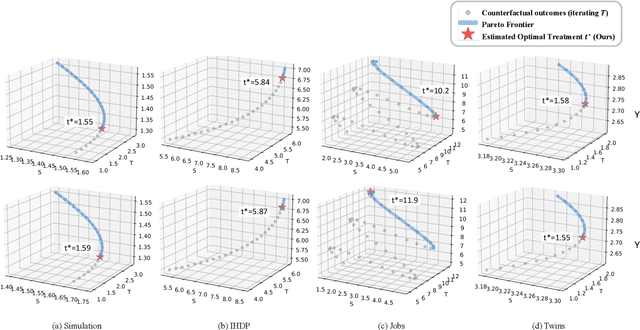
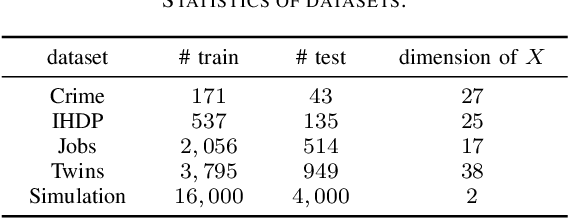
This paper focuses on developing Pareto-optimal estimation and policy learning to identify the most effective treatment that maximizes the total reward from both short-term and long-term effects, which might conflict with each other. For example, a higher dosage of medication might increase the speed of a patient's recovery (short-term) but could also result in severe long-term side effects. Although recent works have investigated the problems about short-term or long-term effects or the both, how to trade-off between them to achieve optimal treatment remains an open challenge. Moreover, when multiple objectives are directly estimated using conventional causal representation learning, the optimization directions among various tasks can conflict as well. In this paper, we systematically investigate these issues and introduce a Pareto-Efficient algorithm, comprising Pareto-Optimal Estimation (POE) and Pareto-Optimal Policy Learning (POPL), to tackle them. POE incorporates a continuous Pareto module with representation balancing, enhancing estimation efficiency across multiple tasks. As for POPL, it involves deriving short-term and long-term outcomes linked with various treatment levels, facilitating an exploration of the Pareto frontier emanating from these outcomes. Results on both the synthetic and real-world datasets demonstrate the superiority of our method.