 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuli Feng
Fair Recommendations with Limited Sensitive Attributes: A Distributionally Robust Optimization Approach
May 02, 2024
As recommender systems are indispensable in various domains such as job searching and e-commerce, providing equitable recommendations to users with different sensitive attributes becomes an imperative requirement. Prior approaches for enhancing fairness in recommender systems presume the availability of all sensitive attributes, which can be difficult to obtain due to privacy concerns or inadequate means of capturing these attributes. In practice, the efficacy of these approaches is limited, pushing us to investigate ways of promoting fairness with limited sensitive attribute information. Toward this goal, it is important to reconstruct missing sensitive attributes. Nevertheless, reconstruction errors are inevitable due to the complexity of real-world sensitive attribute reconstruction problems and legal regulations. Thus, we pursue fair learning methods that are robust to reconstruction errors. To this end, we propose Distributionally Robust Fair Optimization (DRFO), which minimizes the worst-case unfairness over all potential probability distributions of missing sensitive attributes instead of the reconstructed one to account for the impact of the reconstruction errors. We provide theoretical and empirical evidence to demonstrate that our method can effectively ensure fairness in recommender systems when only limited sensitive attributes are accessible.
Be Aware of the Neighborhood Effect: Modeling Selection Bias under Interference
Apr 30, 2024



Selection bias in recommender system arises from the recommendation process of system filtering and the interactive process of user selection. Many previous studies have focused on addressing selection bias to achieve unbiased learning of the prediction model, but ignore the fact that potential outcomes for a given user-item pair may vary with the treatments assigned to other user-item pairs, named neighborhood effect. To fill the gap, this paper formally formulates the neighborhood effect as an interference problem from the perspective of causal inference and introduces a treatment representation to capture the neighborhood effect. On this basis, we propose a novel ideal loss that can be used to deal with selection bias in the presence of neighborhood effect. We further develop two new estimators for estimating the proposed ideal loss. We theoretically establish the connection between the proposed and previous debiasing methods ignoring the neighborhood effect, showing that the proposed methods can achieve unbiased learning when both selection bias and neighborhood effect are present, while the existing methods are biased. Extensive semi-synthetic and real-world experiments are conducted to demonstrate the effectiveness of the proposed methods.
A Survey of Generative Search and Recommendation in the Era of Large Language Models
Apr 25, 2024



With the information explosion on the Web, search and recommendation are foundational infrastructures to satisfying users' information needs. As the two sides of the same coin, both revolve around the same core research problem, matching queries with documents or users with items. In the recent few decades, search and recommendation have experienced synchronous technological paradigm shifts, including machine learning-based and deep learning-based paradigms. Recently, the superintelligent generative large language models have sparked a new paradigm in search and recommendation, i.e., generative search (retrieval) and recommendation, which aims to address the matching problem in a generative manner. In this paper, we provide a comprehensive survey of the emerging paradigm in information systems and summarize the developments in generative search and recommendation from a unified perspective. Rather than simply categorizing existing works, we abstract a unified framework for the generative paradigm and break down the existing works into different stages within this framework to highlight the strengths and weaknesses. And then, we distinguish generative search and recommendation with their unique challenges, identify open problems and future directions, and envision the next information-seeking paradigm.
Exact and Efficient Unlearning for Large Language Model-based Recommendation
Apr 16, 2024The evolving paradigm of Large Language Model-based Recommendation (LLMRec) customizes Large Language Models (LLMs) through parameter-efficient fine-tuning (PEFT) using recommendation data. The inclusion of user data in LLMs raises privacy concerns. To protect users, the unlearning process in LLMRec, specifically removing unusable data (e.g., historical behaviors) from established LLMRec models, becomes crucial. However, existing unlearning methods are insufficient for the unique characteristics of LLM-Rec, mainly due to high computational costs or incomplete data erasure. In this study, we introduce the Adapter Partition and Aggregation (APA) framework for exact and efficient unlearning while maintaining recommendation performance. APA achieves this by establishing distinct adapters for partitioned training data shards and retraining only the adapters impacted by unusable data for unlearning. To preserve recommendation performance and mitigate considerable inference costs, APA employs parameter-level adapter aggregation with sample-adaptive attention for individual testing samples. Extensive experiments substantiate the effectiveness and efficiency of our proposed framework
Leave No Patient Behind: Enhancing Medication Recommendation for Rare Disease Patients
Mar 26, 2024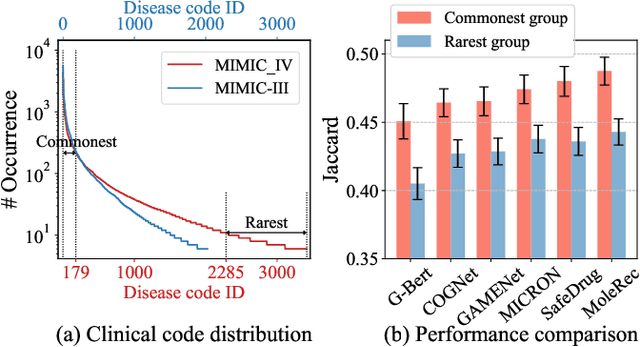

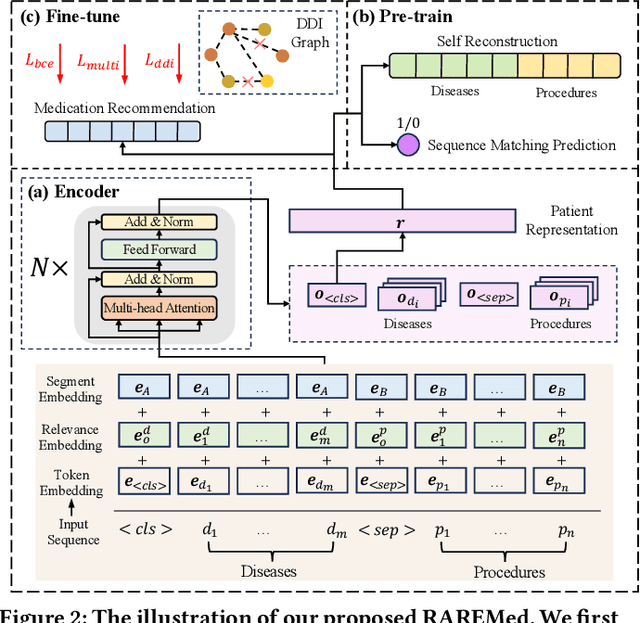
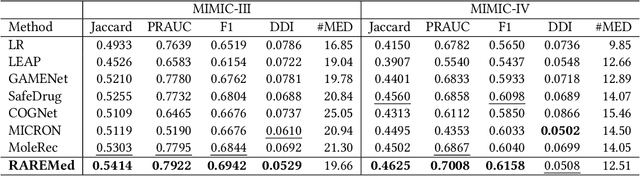
Medication recommendation systems have gained significant attention in healthcare as a means of providing tailored and effective drug combinations based on patients' clinical information. However, existing approaches often suffer from fairness issues, as recommendations tend to be more accurate for patients with common diseases compared to those with rare conditions. In this paper, we propose a novel model called Robust and Accurate REcommendations for Medication (RAREMed), which leverages the pretrain-finetune learning paradigm to enhance accuracy for rare diseases. RAREMed employs a transformer encoder with a unified input sequence approach to capture complex relationships among disease and procedure codes. Additionally, it introduces two self-supervised pre-training tasks, namely Sequence Matching Prediction (SMP) and Self Reconstruction (SR), to learn specialized medication needs and interrelations among clinical codes. Experimental results on two real-world datasets demonstrate that RAREMed provides accurate drug sets for both rare and common disease patients, thereby mitigating unfairness in medication recommendation systems.
Think Twice Before Assure: Confidence Estimation for Large Language Models through Reflection on Multiple Answers
Mar 15, 2024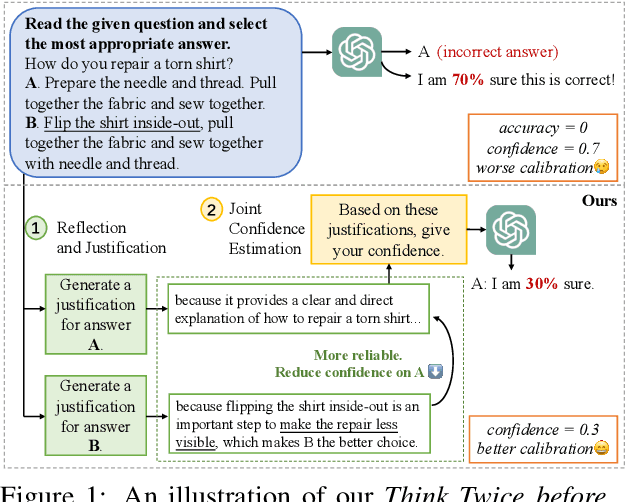

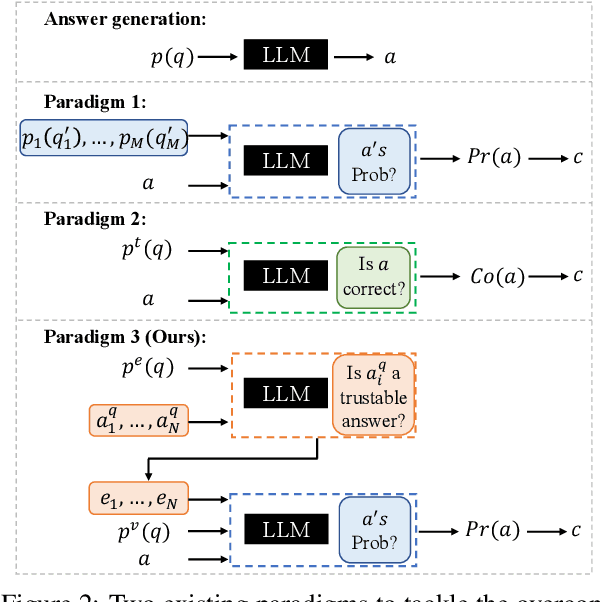
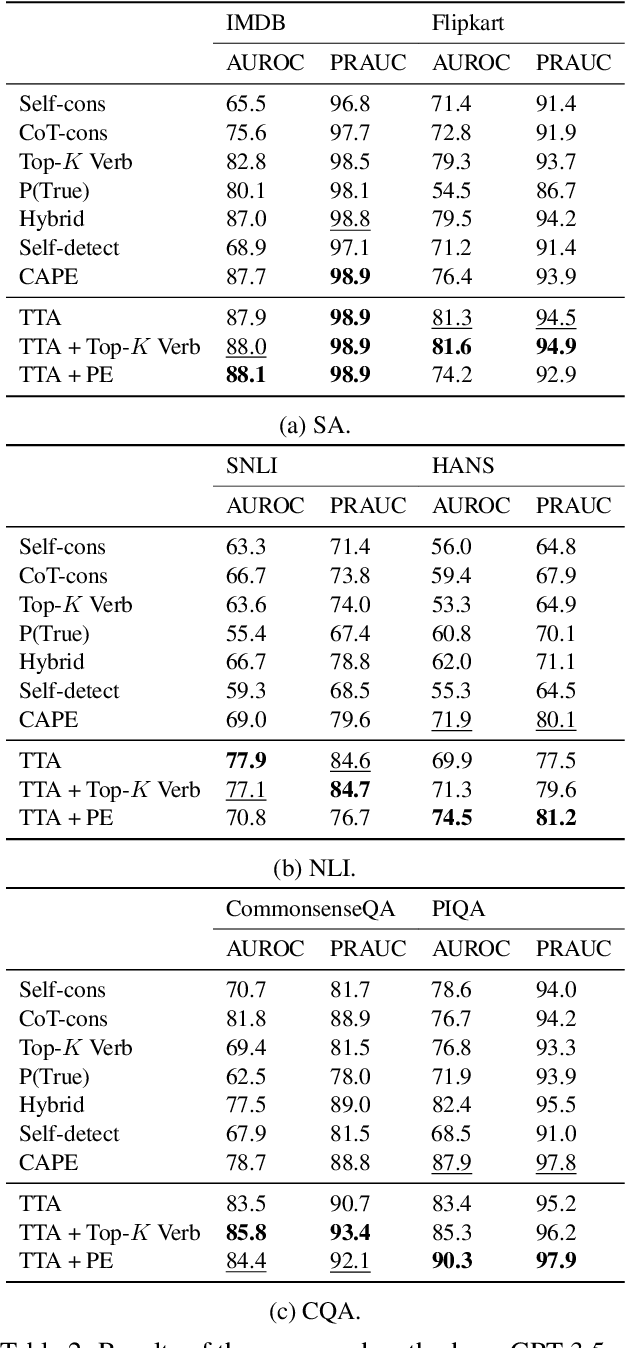
Confidence estimation aiming to evaluate output trustability is crucial for the application of large language models (LLM), especially the black-box ones. Existing confidence estimation of LLM is typically not calibrated due to the overconfidence of LLM on its generated incorrect answers. Existing approaches addressing the overconfidence issue are hindered by a significant limitation that they merely consider the confidence of one answer generated by LLM. To tackle this limitation, we propose a novel paradigm that thoroughly evaluates the trustability of multiple candidate answers to mitigate the overconfidence on incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each answer, and then aggregates the justifications for comprehensive confidence estimation. This framework can be integrated with existing confidence estimation approaches for superior calibration. Experimental results on six datasets of three tasks demonstrate the rationality and effectiveness of the proposed framework.
Proactive Recommendation with Iterative Preference Guidance
Mar 12, 2024



Recommender systems mainly tailor personalized recommendations according to user interests learned from user feedback. However, such recommender systems passively cater to user interests and even reinforce existing interests in the feedback loop, leading to problems like filter bubbles and opinion polarization. To counteract this, proactive recommendation actively steers users towards developing new interests in a target item or topic by strategically modulating recommendation sequences. Existing work for proactive recommendation faces significant hurdles: 1) overlooking the user feedback in the guidance process; 2) lacking explicit modeling of the guiding objective; and 3) insufficient flexibility for integration into existing industrial recommender systems. To address these issues, we introduce an Iterative Preference Guidance (IPG) framework. IPG performs proactive recommendation in a flexible post-processing manner by ranking items according to their IPG scores that consider both interaction probability and guiding value. These scores are explicitly estimated with iteratively updated user representation that considers the most recent user interactions. Extensive experiments validate that IPG can effectively guide user interests toward target interests with a reasonable trade-off in recommender accuracy. The code is available at https://github.com/GabyUSTC/IPG-Rec.
The 2nd Workshop on Recommendation with Generative Models
Mar 07, 2024
The rise of generative models has driven significant advancements in recommender systems, leaving unique opportunities for enhancing users' personalized recommendations. This workshop serves as a platform for researchers to explore and exchange innovative concepts related to the integration of generative models into recommender systems. It primarily focuses on five key perspectives: (i) improving recommender algorithms, (ii) generating personalized content, (iii) evolving the user-system interaction paradigm, (iv) enhancing trustworthiness checks, and (v) refining evaluation methodologies for generative recommendations. With generative models advancing rapidly, an increasing body of research is emerging in these domains, underscoring the timeliness and critical importance of this workshop. The related research will introduce innovative technologies to recommender systems and contribute to fresh challenges in both academia and industry. In the long term, this research direction has the potential to revolutionize the traditional recommender paradigms and foster the development of next-generation recommender systems.
Prospect Personalized Recommendation on Large Language Model-based Agent Platform
Mar 05, 2024The new kind of Agent-oriented information system, exemplified by GPTs, urges us to inspect the information system infrastructure to support Agent-level information processing and to adapt to the characteristics of Large Language Model (LLM)-based Agents, such as interactivity. In this work, we envisage the prospect of the recommender system on LLM-based Agent platforms and introduce a novel recommendation paradigm called Rec4Agentverse, comprised of Agent Items and Agent Recommender. Rec4Agentverse emphasizes the collaboration between Agent Items and Agent Recommender, thereby promoting personalized information services and enhancing the exchange of information beyond the traditional user-recommender feedback loop. Additionally, we prospect the evolution of Rec4Agentverse and conceptualize it into three stages based on the enhancement of the interaction and information exchange among Agent Items, Agent Recommender, and the user. A preliminary study involving several cases of Rec4Agentverse validates its significant potential for application. Lastly, we discuss potential issues and promising directions for future research.
Uplift Modeling for Target User Attacks on Recommender Systems
Mar 05, 2024



Recommender systems are vulnerable to injective attacks, which inject limited fake users into the platforms to manipulate the exposure of target items to all users. In this work, we identify that conventional injective attackers overlook the fact that each item has its unique potential audience, and meanwhile, the attack difficulty across different users varies. Blindly attacking all users will result in a waste of fake user budgets and inferior attack performance. To address these issues, we focus on an under-explored attack task called target user attacks, aiming at promoting target items to a particular user group. In addition, we formulate the varying attack difficulty as heterogeneous treatment effects through a causal lens and propose an Uplift-guided Budget Allocation (UBA) framework. UBA estimates the treatment effect on each target user and optimizes the allocation of fake user budgets to maximize the attack performance. Theoretical and empirical analysis demonstrates the rationality of treatment effect estimation methods of UBA. By instantiating UBA on multiple attackers, we conduct extensive experiments on three datasets under various settings with different target items, target users, fake user budgets, victim models, and defense models, validating the effectiveness and robustness of UBA.