 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Tokenizer for LLM-based Generative Recommendation
May 12, 2024Harnessing Large Language Models (LLMs) for generative recommendation has garnered significant attention due to LLMs' powerful capacities such as rich world knowledge and reasoning. However, a critical challenge lies in transforming recommendation data into the language space of LLMs through effective item tokenization. Existing approaches, such as ID identifiers, textual identifiers, and codebook-based identifiers, exhibit limitations in encoding semantic information, incorporating collaborative signals, or handling code assignment bias. To address these shortcomings, we propose LETTER (a LEarnable Tokenizer for generaTivE Recommendation), designed to meet the key criteria of identifiers by integrating hierarchical semantics, collaborative signals, and code assignment diversity. LETTER integrates Residual Quantized VAE for semantic regularization, a contrastive alignment loss for collaborative regularization, and a diversity loss to mitigate code assignment bias. We instantiate LETTER within two generative recommender models and introduce a ranking-guided generation loss to enhance their ranking ability. Extensive experiments across three datasets demonstrate the superiority of LETTER in item tokenization, thereby advancing the state-of-the-art in the field of generative recommendation.
A Survey of Generative Search and Recommendation in the Era of Large Language Models
Apr 25, 2024



With the information explosion on the Web, search and recommendation are foundational infrastructures to satisfying users' information needs. As the two sides of the same coin, both revolve around the same core research problem, matching queries with documents or users with items. In the recent few decades, search and recommendation have experienced synchronous technological paradigm shifts, including machine learning-based and deep learning-based paradigms. Recently, the superintelligent generative large language models have sparked a new paradigm in search and recommendation, i.e., generative search (retrieval) and recommendation, which aims to address the matching problem in a generative manner. In this paper, we provide a comprehensive survey of the emerging paradigm in information systems and summarize the developments in generative search and recommendation from a unified perspective. Rather than simply categorizing existing works, we abstract a unified framework for the generative paradigm and break down the existing works into different stages within this framework to highlight the strengths and weaknesses. And then, we distinguish generative search and recommendation with their unique challenges, identify open problems and future directions, and envision the next information-seeking paradigm.
Conjugate-Gradient-like Based Adaptive Moment Estimation Optimization Algorithm for Deep Learning
Apr 02, 2024



Training deep neural networks is a challenging task. In order to speed up training and enhance the performance of deep neural networks, we rectify the vanilla conjugate gradient as conjugate-gradient-like and incorporate it into the generic Adam, and thus propose a new optimization algorithm named CG-like-Adam for deep learning. Specifically, both the first-order and the second-order moment estimation of generic Adam are replaced by the conjugate-gradient-like. Convergence analysis handles the cases where the exponential moving average coefficient of the first-order moment estimation is constant and the first-order moment estimation is unbiased. Numerical experiments show the superiority of the proposed algorithm based on the CIFAR10/100 dataset.
Discriminative Probing and Tuning for Text-to-Image Generation
Mar 14, 2024
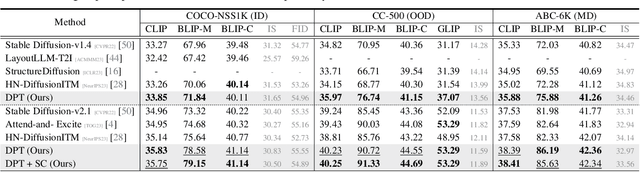
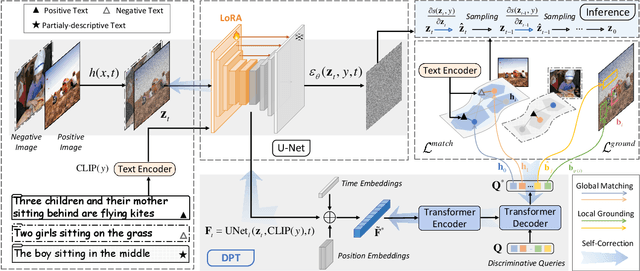
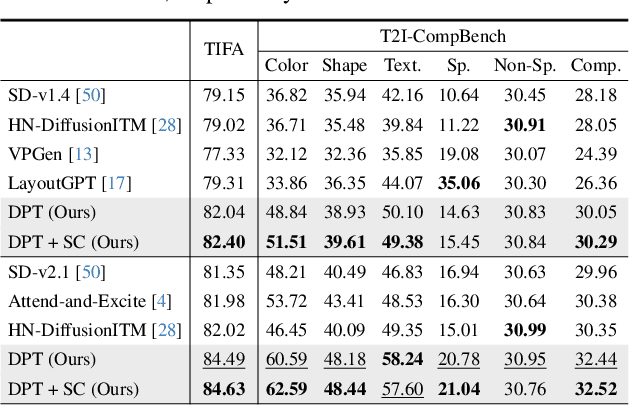
Despite advancements in text-to-image generation (T2I), prior methods often face text-image misalignment problems such as relation confusion in generated images. Existing solutions involve cross-attention manipulation for better compositional understanding or integrating large language models for improved layout planning. However, the inherent alignment capabilities of T2I models are still inadequate. By reviewing the link between generative and discriminative modeling, we posit that T2I models' discriminative abilities may reflect their text-image alignment proficiency during generation. In this light, we advocate bolstering the discriminative abilities of T2I models to achieve more precise text-to-image alignment for generation. We present a discriminative adapter built on T2I models to probe their discriminative abilities on two representative tasks and leverage discriminative fine-tuning to improve their text-image alignment. As a bonus of the discriminative adapter, a self-correction mechanism can leverage discriminative gradients to better align generated images to text prompts during inference. Comprehensive evaluations across three benchmark datasets, including both in-distribution and out-of-distribution scenarios, demonstrate our method's superior generation performance. Meanwhile, it achieves state-of-the-art discriminative performance on the two discriminative tasks compared to other generative models.
Distillation Enhanced Generative Retrieval
Feb 16, 2024Generative retrieval is a promising new paradigm in text retrieval that generates identifier strings of relevant passages as the retrieval target. This paradigm leverages powerful generative language models, distinct from traditional sparse or dense retrieval methods. In this work, we identify a viable direction to further enhance generative retrieval via distillation and propose a feasible framework, named DGR. DGR utilizes sophisticated ranking models, such as the cross-encoder, in a teacher role to supply a passage rank list, which captures the varying relevance degrees of passages instead of binary hard labels; subsequently, DGR employs a specially designed distilled RankNet loss to optimize the generative retrieval model, considering the passage rank order provided by the teacher model as labels. This framework only requires an additional distillation step to enhance current generative retrieval systems and does not add any burden to the inference stage. We conduct experiments on four public datasets, and the results indicate that DGR achieves state-of-the-art performance among the generative retrieval methods. Additionally, DGR demonstrates exceptional robustness and generalizability with various teacher models and distillation losses.
Generative Cross-Modal Retrieval: Memorizing Images in Multimodal Language Models for Retrieval and Beyond
Feb 16, 2024The recent advancements in generative language models have demonstrated their ability to memorize knowledge from documents and recall knowledge to respond to user queries effectively. Building upon this capability, we propose to enable multimodal large language models (MLLMs) to memorize and recall images within their parameters. Given a user query for visual content, the MLLM is anticipated to "recall" the relevant image from its parameters as the response. Achieving this target presents notable challenges, including inbuilt visual memory and visual recall schemes within MLLMs. To address these challenges, we introduce a generative cross-modal retrieval framework, which assigns unique identifier strings to represent images and involves two training steps: learning to memorize and learning to retrieve. The first step focuses on training the MLLM to memorize the association between images and their respective identifiers. The latter step teaches the MLLM to generate the corresponding identifier of the target image, given the textual query input. By memorizing images in MLLMs, we introduce a new paradigm to cross-modal retrieval, distinct from previous discriminative approaches. The experiments demonstrate that the generative paradigm performs effectively and efficiently even with large-scale image candidate sets.
GliDe with a CaPE: A Low-Hassle Method to Accelerate Speculative Decoding
Feb 03, 2024Speculative decoding is a relatively new decoding framework that leverages small and efficient draft models to reduce the latency of LLMs. In this study, we introduce GliDe and CaPE, two low-hassle modifications to vanilla speculative decoding to further improve the decoding speed of a frozen LLM. Specifically, GliDe is a modified draft model architecture that reuses the cached keys and values from the target LLM, while CaPE is a proposal expansion method that uses the draft model's confidence scores to help select additional candidate tokens for verification. Extensive experiments on different benchmarks demonstrate that our proposed GliDe draft model significantly reduces the expected decoding latency. Additional evaluation using walltime reveals that GliDe can accelerate Vicuna models up to 2.17x and further extend the improvement to 2.61x with CaPE. We will release our code, data, and the trained draft models.
Data-efficient Fine-tuning for LLM-based Recommendation
Jan 30, 2024Leveraging Large Language Models (LLMs) for recommendation has recently garnered considerable attention, where fine-tuning plays a key role in LLMs' adaptation. However, the cost of fine-tuning LLMs on rapidly expanding recommendation data limits their practical application. To address this challenge, few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data. We propose the task of data pruning for efficient LLM-based recommendation, aimed at identifying representative samples tailored for LLMs' few-shot fine-tuning. While coreset selection is closely related to the proposed task, existing coreset selection methods often rely on suboptimal heuristic metrics or entail costly optimization on large-scale recommendation data. To tackle these issues, we introduce two objectives for the data pruning task in the context of LLM-based recommendation: 1) high accuracy aims to identify the influential samples that can lead to high overall performance; and 2) high efficiency underlines the low costs of the data pruning process. To pursue the two objectives, we propose a novel data pruning method based on two scores, i.e., influence score and effort score, to efficiently identify the influential samples. Particularly, the influence score is introduced to accurately estimate the influence of sample removal on the overall performance. To achieve low costs of the data pruning process, we use a small-sized surrogate model to replace LLMs to obtain the influence score. Considering the potential gap between the surrogate model and LLMs, we further propose an effort score to prioritize some hard samples specifically for LLMs. Empirical results on three real-world datasets validate the effectiveness of our proposed method. In particular, the proposed method uses only 2% samples to surpass the full data fine-tuning, reducing time costs by 97%.
Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Jan 15, 2024To mitigate the high inference latency stemming from autoregressive decoding in Large Language Models (LLMs), Speculative Decoding has emerged as a novel decoding paradigm for LLM inference. In each decoding step, this method first efficiently drafts several future tokens and then verifies them in parallel. Unlike autoregressive decoding, Speculative Decoding facilitates the simultaneous decoding of multiple tokens per step, thereby accelerating inference. This paper presents a comprehensive overview and analysis of this promising decoding paradigm. We begin by providing a formal definition and formulation of Speculative Decoding. Then, we organize in-depth discussions on its key facets, including current leading techniques, the challenges faced, and potential future directions in this field. We aim for this work to serve as a catalyst for further research on Speculative Decoding, ultimately contributing to more efficient LLM inference.
Temporally and Distributionally Robust Optimization for Cold-start Recommendation
Dec 22, 2023Collaborative Filtering (CF) recommender models highly depend on user-item interactions to learn CF representations, thus falling short of recommending cold-start items. To address this issue, prior studies mainly introduce item features (e.g., thumbnails) for cold-start item recommendation. They learn a feature extractor on warm-start items to align feature representations with interactions, and then leverage the feature extractor to extract the feature representations of cold-start items for interaction prediction. Unfortunately, the features of cold-start items, especially the popular ones, tend to diverge from those of warm-start ones due to temporal feature shifts, preventing the feature extractor from accurately learning feature representations of cold-start items. To alleviate the impact of temporal feature shifts, we consider using Distributionally Robust Optimization (DRO) to enhance the generation ability of the feature extractor. Nonetheless, existing DRO methods face an inconsistency issue: the worse-case warm-start items emphasized during DRO training might not align well with the cold-start item distribution. To capture the temporal feature shifts and combat this inconsistency issue, we propose a novel temporal DRO with new optimization objectives, namely, 1) to integrate a worst-case factor to improve the worst-case performance, and 2) to devise a shifting factor to capture the shifting trend of item features and enhance the optimization of the potentially popular groups in cold-start items. Substantial experiments on three real-world datasets validate the superiority of our temporal DRO in enhancing the generalization ability of cold-start recommender models. The code is available at https://github.com/Linxyhaha/TDRO/.