 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Advantages of Perturbing Cosine Router in Sparse Mixture of Experts
May 23, 2024The cosine router in sparse Mixture of Experts (MoE) has recently emerged as an attractive alternative to the conventional linear router. Indeed, the cosine router demonstrates favorable performance in image and language tasks and exhibits better ability to mitigate the representation collapse issue, which often leads to parameter redundancy and limited representation potentials. Despite its empirical success, a comprehensive analysis of the cosine router in sparse MoE has been lacking. Considering the least square estimation of the cosine routing sparse MoE, we demonstrate that due to the intrinsic interaction of the model parameters in the cosine router via some partial differential equations, regardless of the structures of the experts, the estimation rates of experts and model parameters can be as slow as $\mathcal{O}(1/\log^{\tau}(n))$ where $\tau > 0$ is some constant and $n$ is the sample size. Surprisingly, these pessimistic non-polynomial convergence rates can be circumvented by the widely used technique in practice to stabilize the cosine router -- simply adding noises to the $\mathbb{L}_{2}$ norms in the cosine router, which we refer to as \textit{perturbed cosine router}. Under the strongly identifiable settings of the expert functions, we prove that the estimation rates for both the experts and model parameters under the perturbed cosine routing sparse MoE are significantly improved to polynomial rates. Finally, we conduct extensive simulation studies in both synthetic and real data settings to empirically validate our theoretical results.
Mixture of Experts Meets Prompt-Based Continual Learning
May 23, 2024Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
Sigmoid Gating is More Sample Efficient than Softmax Gating in Mixture of Experts
May 22, 2024



The softmax gating function is arguably the most popular choice in mixture of experts modeling. Despite its widespread use in practice, softmax gating may lead to unnecessary competition among experts, potentially causing the undesirable phenomenon of representation collapse due to its inherent structure. In response, the sigmoid gating function has been recently proposed as an alternative and has been demonstrated empirically to achieve superior performance. However, a rigorous examination of the sigmoid gating function is lacking in current literature. In this paper, we verify theoretically that sigmoid gating, in fact, enjoys a higher sample efficiency than softmax gating for the statistical task of expert estimation. Towards that goal, we consider a regression framework in which the unknown regression function is modeled as a mixture of experts, and study the rates of convergence of the least squares estimator in the over-specified case in which the number of experts fitted is larger than the true value. We show that two gating regimes naturally arise and, in each of them, we formulate identifiability conditions for the expert functions and derive the corresponding convergence rates. In both cases, we find that experts formulated as feed-forward networks with commonly used activation such as $\mathrm{ReLU}$ and $\mathrm{GELU}$ enjoy faster convergence rates under sigmoid gating than softmax gating. Furthermore, given the same choice of experts, we demonstrate that the sigmoid gating function requires a smaller sample size than its softmax counterpart to attain the same error of expert estimation and, therefore, is more sample efficient.
On Parameter Estimation in Deviated Gaussian Mixture of Experts
Feb 07, 2024We consider the parameter estimation problem in the deviated Gaussian mixture of experts in which the data are generated from $(1 - \lambda^{\ast}) g_0(Y| X)+ \lambda^{\ast} \sum_{i = 1}^{k_{\ast}} p_{i}^{\ast} f(Y|(a_{i}^{\ast})^{\top}X+b_i^{\ast},\sigma_{i}^{\ast})$, where $X, Y$ are respectively a covariate vector and a response variable, $g_{0}(Y|X)$ is a known function, $\lambda^{\ast} \in [0, 1]$ is true but unknown mixing proportion, and $(p_{i}^{\ast}, a_{i}^{\ast}, b_{i}^{\ast}, \sigma_{i}^{\ast})$ for $1 \leq i \leq k^{\ast}$ are unknown parameters of the Gaussian mixture of experts. This problem arises from the goodness-of-fit test when we would like to test whether the data are generated from $g_{0}(Y|X)$ (null hypothesis) or they are generated from the whole mixture (alternative hypothesis). Based on the algebraic structure of the expert functions and the distinguishability between $g_0$ and the mixture part, we construct novel Voronoi-based loss functions to capture the convergence rates of maximum likelihood estimation (MLE) for our models. We further demonstrate that our proposed loss functions characterize the local convergence rates of parameter estimation more accurately than the generalized Wasserstein, a loss function being commonly used for estimating parameters in the Gaussian mixture of experts.
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Feb 05, 2024As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in real world is validated by a challenging set of clinical risk prediction tasks.
On Least Squares Estimation in Softmax Gating Mixture of Experts
Feb 05, 2024Mixture of experts (MoE) model is a statistical machine learning design that aggregates multiple expert networks using a softmax gating function in order to form a more intricate and expressive model. Despite being commonly used in several applications owing to their scalability, the mathematical and statistical properties of MoE models are complex and difficult to analyze. As a result, previous theoretical works have primarily focused on probabilistic MoE models by imposing the impractical assumption that the data are generated from a Gaussian MoE model. In this work, we investigate the performance of the least squares estimators (LSE) under a deterministic MoE model where the data are sampled according to a regression model, a setting that has remained largely unexplored. We establish a condition called strong identifiability to characterize the convergence behavior of various types of expert functions. We demonstrate that the rates for estimating strongly identifiable experts, namely the widely used feed forward networks with activation functions $\mathrm{sigmoid}(\cdot)$ and $\tanh(\cdot)$, are substantially faster than those of polynomial experts, which we show to exhibit a surprising slow estimation rate. Our findings have important practical implications for expert selection.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024

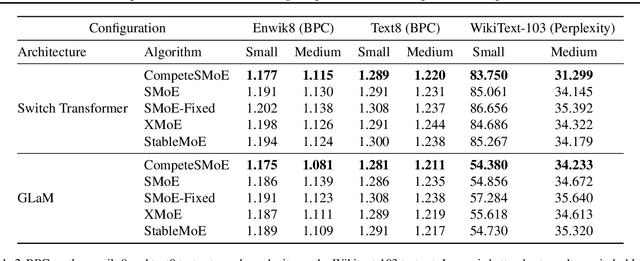

Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
Is Temperature Sample Efficient for Softmax Gaussian Mixture of Experts?
Jan 25, 2024Dense-to-sparse gating mixture of experts (MoE) has recently become an effective alternative to a well-known sparse MoE. Rather than fixing the number of activated experts as in the latter model, which could limit the investigation of potential experts, the former model utilizes the temperature to control the softmax weight distribution and the sparsity of the MoE during training in order to stabilize the expert specialization. Nevertheless, while there are previous attempts to theoretically comprehend the sparse MoE, a comprehensive analysis of the dense-to-sparse gating MoE has remained elusive. Therefore, we aim to explore the impacts of the dense-to-sparse gate on the maximum likelihood estimation under the Gaussian MoE in this paper. We demonstrate that due to interactions between the temperature and other model parameters via some partial differential equations, the convergence rates of parameter estimations are slower than any polynomial rates, and could be as slow as $\mathcal{O}(1/\log(n))$, where $n$ denotes the sample size. To address this issue, we propose using a novel activation dense-to-sparse gate, which routes the output of a linear layer to an activation function before delivering them to the softmax function. By imposing linearly independence conditions on the activation function and its derivatives, we show that the parameter estimation rates are significantly improved to polynomial rates.
AG-ReID.v2: Bridging Aerial and Ground Views for Person Re-identification
Jan 05, 2024Aerial-ground person re-identification (Re-ID) presents unique challenges in computer vision, stemming from the distinct differences in viewpoints, poses, and resolutions between high-altitude aerial and ground-based cameras. Existing research predominantly focuses on ground-to-ground matching, with aerial matching less explored due to a dearth of comprehensive datasets. To address this, we introduce AG-ReID.v2, a dataset specifically designed for person Re-ID in mixed aerial and ground scenarios. This dataset comprises 100,502 images of 1,615 unique individuals, each annotated with matching IDs and 15 soft attribute labels. Data were collected from diverse perspectives using a UAV, stationary CCTV, and smart glasses-integrated camera, providing a rich variety of intra-identity variations. Additionally, we have developed an explainable attention network tailored for this dataset. This network features a three-stream architecture that efficiently processes pairwise image distances, emphasizes key top-down features, and adapts to variations in appearance due to altitude differences. Comparative evaluations demonstrate the superiority of our approach over existing baselines. We plan to release the dataset and algorithm source code publicly, aiming to advance research in this specialized field of computer vision. For access, please visit https://github.com/huynguyen792/AG-ReID.v2.
A General Theory for Softmax Gating Multinomial Logistic Mixture of Experts
Oct 22, 2023Mixture-of-experts (MoE) model incorporates the power of multiple submodels via gating functions to achieve greater performance in numerous regression and classification applications. From a theoretical perspective, while there have been previous attempts to comprehend the behavior of that model under the regression settings through the convergence analysis of maximum likelihood estimation in the Gaussian MoE model, such analysis under the setting of a classification problem has remained missing in the literature. We close this gap by establishing the convergence rates of density estimation and parameter estimation in the softmax gating multinomial logistic MoE model. Notably, when part of the expert parameters vanish, these rates are shown to be slower than polynomial rates owing to an inherent interaction between the softmax gating and expert functions via partial differential equations. To address this issue, we propose using a novel class of modified softmax gating functions which transform the input value before delivering them to the gating functions. As a result, the previous interaction disappears and the parameter estimation rates are significantly improved.