 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidentially Calibrated Source-Free Time-Series Domain Adaptation with Temporal Imputation
Jun 04, 2024Source-free domain adaptation (SFDA) aims to adapt a model pre-trained on a labeled source domain to an unlabeled target domain without access to source data, preserving the source domain's privacy. While SFDA is prevalent in computer vision, it remains largely unexplored in time series analysis. Existing SFDA methods, designed for visual data, struggle to capture the inherent temporal dynamics of time series, hindering adaptation performance. This paper proposes MAsk And imPUte (MAPU), a novel and effective approach for time series SFDA. MAPU addresses the critical challenge of temporal consistency by introducing a novel temporal imputation task. This task involves randomly masking time series signals and leveraging a dedicated temporal imputer to recover the original signal within the learned embedding space, bypassing the complexities of noisy raw data. Notably, MAPU is the first method to explicitly address temporal consistency in the context of time series SFDA. Additionally, it offers seamless integration with existing SFDA methods, providing greater flexibility. We further introduce E-MAPU, which incorporates evidential uncertainty estimation to address the overconfidence issue inherent in softmax predictions. To achieve that, we leverage evidential deep learning to obtain a better-calibrated pre-trained model and adapt the target encoder to map out-of-support target samples to a new feature representation closer to the source domain's support. This fosters better alignment, ultimately enhancing adaptation performance. Extensive experiments on five real-world time series datasets demonstrate that both MAPU and E-MAPU achieve significant performance gains compared to existing methods. These results highlight the effectiveness of our proposed approaches for tackling various time series domain adaptation problems.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
TSLANet: Rethinking Transformers for Time Series Representation Learning
Apr 12, 2024



Time series data, characterized by its intrinsic long and short-range dependencies, poses a unique challenge across analytical applications. While Transformer-based models excel at capturing long-range dependencies, they face limitations in noise sensitivity, computational efficiency, and overfitting with smaller datasets. In response, we introduce a novel Time Series Lightweight Adaptive Network (TSLANet), as a universal convolutional model for diverse time series tasks. Specifically, we propose an Adaptive Spectral Block, harnessing Fourier analysis to enhance feature representation and to capture both long-term and short-term interactions while mitigating noise via adaptive thresholding. Additionally, we introduce an Interactive Convolution Block and leverage self-supervised learning to refine the capacity of TSLANet for decoding complex temporal patterns and improve its robustness on different datasets. Our comprehensive experiments demonstrate that TSLANet outperforms state-of-the-art models in various tasks spanning classification, forecasting, and anomaly detection, showcasing its resilience and adaptability across a spectrum of noise levels and data sizes. The code is available at \url{https://github.com/emadeldeen24/TSLANet}
An Experiment with the Use of ChatGPT for LCSH Subject Assignment on Electronic Theses and Dissertations
Apr 03, 2024This study delves into the potential use of Large Language Models (LLMs) for generating Library of Congress Subject Headings (LCSH). The authors employed ChatGPT to generate subject headings for electronic theses and dissertations (ETDs) based on their titles and summaries. The results revealed that although some generated subject headings were valid, there were issues regarding specificity and exhaustiveness. The study showcases that LLMs can serve as a strategic response to the backlog of items awaiting cataloging in academic libraries, while also offering a cost-effective approach for promptly generating LCSH. Nonetheless, human catalogers remain essential for verifying and enhancing the validity, exhaustiveness, and specificity of LCSH generated by LLMs.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024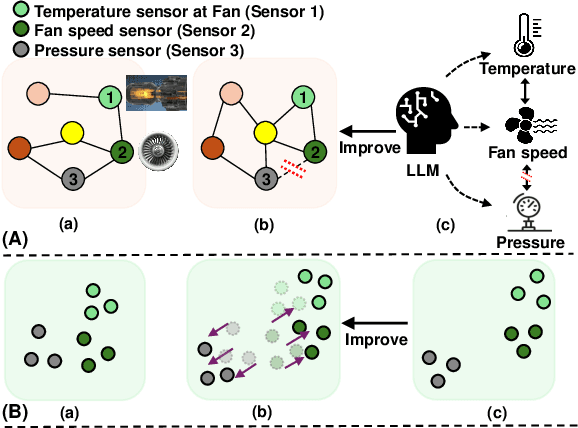
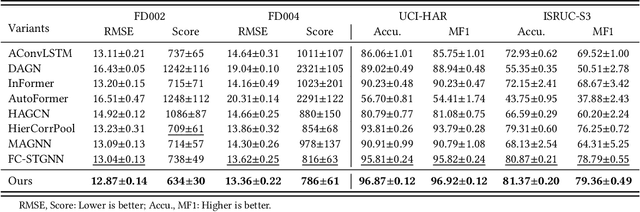
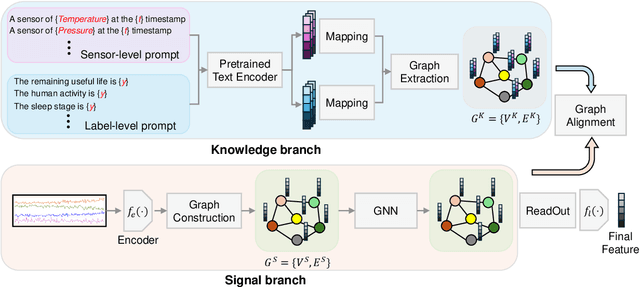
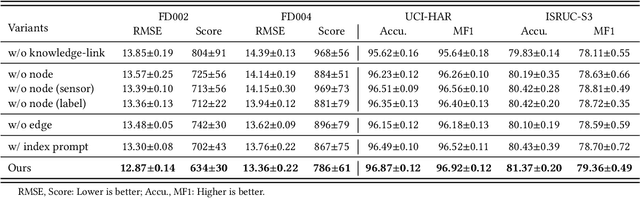
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
Generative Semi-supervised Graph Anomaly Detection
Feb 19, 2024



This work considers a practical semi-supervised graph anomaly detection (GAD) scenario, where part of the nodes in a graph are known to be normal, contrasting to the unsupervised setting in most GAD studies with a fully unlabeled graph. As expected, we find that having access to these normal nodes helps enhance the detection performance of existing unsupervised GAD methods when they are adapted to the semi-supervised setting. However, their utilization of these normal nodes is limited. In this paper, we propose a novel Generative GAD approach (GGAD) for the semi-supervised scenario to better exploit the normal nodes. The key idea is to generate outlier nodes that assimilate anomaly nodes in both local structure and node representations for providing effective negative node samples in training a discriminative one-class classifier. There have been many generative anomaly detection approaches, but they are designed for non-graph data, and as a result, they fail to take account of the graph structure information. Our approach tackles this problem by generating graph structure-aware outlier nodes that have asymmetric affinity separability from normal nodes while being enforced to achieve egocentric closeness to normal nodes in the node representation space. Comprehensive experiments on four real-world datasets are performed to establish a benchmark for semi-supervised GAD and show that GGAD substantially outperforms state-of-the-art unsupervised and semi-supervised GAD methods with varying numbers of training normal nodes. Code will be made available at https://github.com/mala-lab/GGAD.
Self-evolving Autoencoder Embedded Q-Network
Feb 18, 2024



In the realm of sequential decision-making tasks, the exploration capability of a reinforcement learning (RL) agent is paramount for achieving high rewards through interactions with the environment. To enhance this crucial ability, we propose SAQN, a novel approach wherein a self-evolving autoencoder (SA) is embedded with a Q-Network (QN). In SAQN, the self-evolving autoencoder architecture adapts and evolves as the agent explores the environment. This evolution enables the autoencoder to capture a diverse range of raw observations and represent them effectively in its latent space. By leveraging the disentangled states extracted from the encoder generated latent space, the QN is trained to determine optimal actions that improve rewards. During the evolution of the autoencoder architecture, a bias-variance regulatory strategy is employed to elicit the optimal response from the RL agent. This strategy involves two key components: (i) fostering the growth of nodes to retain previously acquired knowledge, ensuring a rich representation of the environment, and (ii) pruning the least contributing nodes to maintain a more manageable and tractable latent space. Extensive experimental evaluations conducted on three distinct benchmark environments and a real-world molecular environment demonstrate that the proposed SAQN significantly outperforms state-of-the-art counterparts. The results highlight the effectiveness of the self-evolving autoencoder and its collaboration with the Q-Network in tackling sequential decision-making tasks.
Evolving Restricted Boltzmann Machine-Kohonen Network for Online Clustering
Feb 14, 2024



A novel online clustering algorithm is presented where an Evolving Restricted Boltzmann Machine (ERBM) is embedded with a Kohonen Network called ERBM-KNet. The proposed ERBM-KNet efficiently handles streaming data in a single-pass mode using the ERBM, employing a bias-variance strategy for neuron growing and pruning, as well as online clustering based on a cluster update strategy for cluster prediction and cluster center update using KNet. Initially, ERBM evolves its architecture while processing unlabeled image data, effectively disentangling the data distribution in the latent space. Subsequently, the KNet utilizes the feature extracted from ERBM to predict the number of clusters and updates the cluster centers. By overcoming the common challenges associated with clustering algorithms, such as prior initialization of the number of clusters and subpar clustering accuracy, the proposed ERBM-KNet offers significant improvements. Extensive experimental evaluations on four benchmarks and one industry dataset demonstrate the superiority of ERBM-KNet compared to state-of-the-art approaches.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024

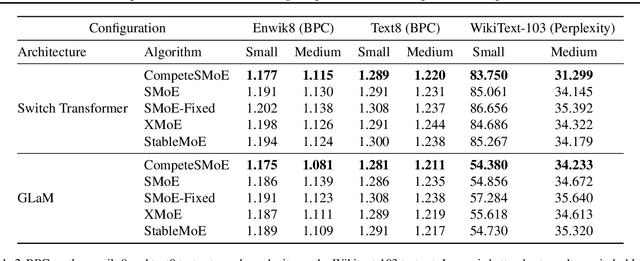

Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.