 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifiably Byzantine-Robust Federated Conformal Prediction
Jun 04, 2024Conformal prediction has shown impressive capacity in constructing statistically rigorous prediction sets for machine learning models with exchangeable data samples. The siloed datasets, coupled with the escalating privacy concerns related to local data sharing, have inspired recent innovations extending conformal prediction into federated environments with distributed data samples. However, this framework for distributed uncertainty quantification is susceptible to Byzantine failures. A minor subset of malicious clients can significantly compromise the practicality of coverage guarantees. To address this vulnerability, we introduce a novel framework Rob-FCP, which executes robust federated conformal prediction, effectively countering malicious clients capable of reporting arbitrary statistics with the conformal calibration process. We theoretically provide the conformal coverage bound of Rob-FCP in the Byzantine setting and show that the coverage of Rob-FCP is asymptotically close to the desired coverage level. We also propose a malicious client number estimator to tackle a more challenging setting where the number of malicious clients is unknown to the defender and theoretically shows its effectiveness. We empirically demonstrate the robustness of Rob-FCP against diverse proportions of malicious clients under a variety of Byzantine attacks on five standard benchmark and real-world healthcare datasets.
Contextualized Sequence Likelihood: Enhanced Confidence Scores for Natural Language Generation
Jun 03, 2024The advent of large language models (LLMs) has dramatically advanced the state-of-the-art in numerous natural language generation tasks. For LLMs to be applied reliably, it is essential to have an accurate measure of their confidence. Currently, the most commonly used confidence score function is the likelihood of the generated sequence, which, however, conflates semantic and syntactic components. For instance, in question-answering (QA) tasks, an awkward phrasing of the correct answer might result in a lower probability prediction. Additionally, different tokens should be weighted differently depending on the context. In this work, we propose enhancing the predicted sequence probability by assigning different weights to various tokens using attention values elicited from the base LLM. By employing a validation set, we can identify the relevant attention heads, thereby significantly improving the reliability of the vanilla sequence probability confidence measure. We refer to this new score as the Contextualized Sequence Likelihood (CSL). CSL is easy to implement, fast to compute, and offers considerable potential for further improvement with task-specific prompts. Across several QA datasets and a diverse array of LLMs, CSL has demonstrated significantly higher reliability than state-of-the-art baselines in predicting generation quality, as measured by the AUROC or AUARC.
Cross-Table Pretraining towards a Universal Function Space for Heterogeneous Tabular Data
Jun 01, 2024Tabular data from different tables exhibit significant diversity due to varied definitions and types of features, as well as complex inter-feature and feature-target relationships. Cross-dataset pretraining, which learns reusable patterns from upstream data to support downstream tasks, have shown notable success in various fields. Yet, when applied to tabular data prediction, this paradigm faces challenges due to the limited reusable patterns among diverse tabular datasets (tables) and the general scarcity of tabular data available for fine-tuning. In this study, we fill this gap by introducing a cross-table pretrained Transformer, XTFormer, for versatile downstream tabular prediction tasks. Our methodology insight is pretraining XTFormer to establish a "meta-function" space that encompasses all potential feature-target mappings. In pre-training, a variety of potential mappings are extracted from pre-training tabular datasets and are embedded into the "meta-function" space, and suited mappings are extracted from the "meta-function" space for downstream tasks by a specified coordinate positioning approach. Experiments show that, in 190 downstream tabular prediction tasks, our cross-table pretrained XTFormer wins both XGBoost and Catboost on 137 (72%) tasks, and surpasses representative deep learning models FT-Transformer and the tabular pre-training approach XTab on 144 (76%) and 162 (85%) tasks.
KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge
May 26, 2024Knowledge Graph Embedding (KGE) techniques are crucial in learning compact representations of entities and relations within a knowledge graph, facilitating efficient reasoning and knowledge discovery. While existing methods typically focus either on training KGE models solely based on graph structure or fine-tuning pre-trained language models with classification data in KG, KG-FIT leverages LLM-guided refinement to construct a semantically coherent hierarchical structure of entity clusters. By incorporating this hierarchical knowledge along with textual information during the fine-tuning process, KG-FIT effectively captures both global semantics from the LLM and local semantics from the KG. Extensive experiments on the benchmark datasets FB15K-237, YAGO3-10, and PrimeKG demonstrate the superiority of KG-FIT over state-of-the-art pre-trained language model-based methods, achieving improvements of 14.4%, 13.5%, and 11.9% in the Hits@10 metric for the link prediction task, respectively. Furthermore, KG-FIT yields substantial performance gains of 12.6%, 6.7%, and 17.7% compared to the structure-based base models upon which it is built. These results highlight the effectiveness of KG-FIT in incorporating open-world knowledge from LLMs to significantly enhance the expressiveness and informativeness of KG embeddings.
Contactless Polysomnography: What Radio Waves Tell Us about Sleep
May 20, 2024The ability to assess sleep at home, capture sleep stages, and detect the occurrence of apnea (without on-body sensors) simply by analyzing the radio waves bouncing off people's bodies while they sleep is quite powerful. Such a capability would allow for longitudinal data collection in patients' homes, informing our understanding of sleep and its interaction with various diseases and their therapeutic responses, both in clinical trials and routine care. In this article, we develop an advanced machine learning algorithm for passively monitoring sleep and nocturnal breathing from radio waves reflected off people while asleep. Validation results in comparison with the gold standard (i.e., polysomnography) (n=849) demonstrate that the model captures the sleep hypnogram (with an accuracy of 81% for 30-second epochs categorized into Wake, Light Sleep, Deep Sleep, or REM), detects sleep apnea (AUROC = 0.88), and measures the patient's Apnea-Hypopnea Index (ICC=0.95; 95% CI = [0.93, 0.97]). Notably, the model exhibits equitable performance across race, sex, and age. Moreover, the model uncovers informative interactions between sleep stages and a range of diseases including neurological, psychiatric, cardiovascular, and immunological disorders. These findings not only hold promise for clinical practice and interventional trials but also underscore the significance of sleep as a fundamental component in understanding and managing various diseases.
Language Interaction Network for Clinical Trial Approval Estimation
Apr 26, 2024Clinical trial outcome prediction seeks to estimate the likelihood that a clinical trial will successfully reach its intended endpoint. This process predominantly involves the development of machine learning models that utilize a variety of data sources such as descriptions of the clinical trials, characteristics of the drug molecules, and specific disease conditions being targeted. Accurate predictions of trial outcomes are crucial for optimizing trial planning and prioritizing investments in a drug portfolio. While previous research has largely concentrated on small-molecule drugs, there is a growing need to focus on biologics-a rapidly expanding category of therapeutic agents that often lack the well-defined molecular properties associated with traditional drugs. Additionally, applying conventional methods like graph neural networks to biologics data proves challenging due to their complex nature. To address these challenges, we introduce the Language Interaction Network (LINT), a novel approach that predicts trial outcomes using only the free-text descriptions of the trials. We have rigorously tested the effectiveness of LINT across three phases of clinical trials, where it achieved ROC-AUC scores of 0.770, 0.740, and 0.748 for phases I, II, and III, respectively, specifically concerning trials involving biologic interventions.
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Apr 25, 2024



Large Language Models (LLMs) have shown promising capabilities in handling clinical text summarization tasks. In this study, we demonstrate that a small open-source LLM can be effectively trained to generate high-quality clinical notes from outpatient patient-doctor dialogues. We achieve this through a comprehensive domain- and task-specific adaptation process for the LLaMA-2 13 billion parameter model. This process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced an enhanced approach, termed DistillDirect, for performing on-policy reinforcement learning with Gemini Pro serving as the teacher model. Our resulting model, LLaMA-Clinic, is capable of generating clinical notes that are comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as "acceptable" or higher across all three criteria: real-world readiness, completeness, and accuracy. Notably, in the more challenging "Assessment and Plan" section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness compared to physician-authored notes (4.1/5). Additionally, we identified caveats in public clinical note datasets, such as ACI-BENCH. We highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format. Overall, our research demonstrates the potential and feasibility of training smaller, open-source LLMs to assist with clinical documentation, capitalizing on healthcare institutions' access to patient records and domain expertise. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research in this field.
TriSum: Learning Summarization Ability from Large Language Models with Structured Rationale
Mar 15, 2024
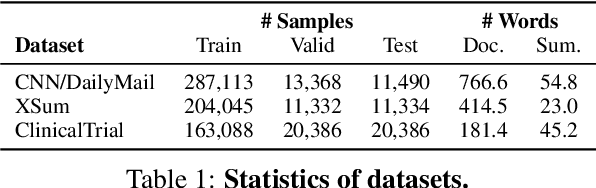
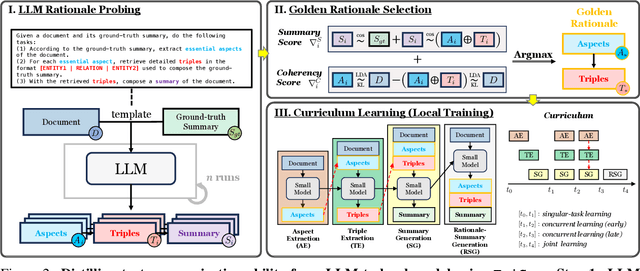
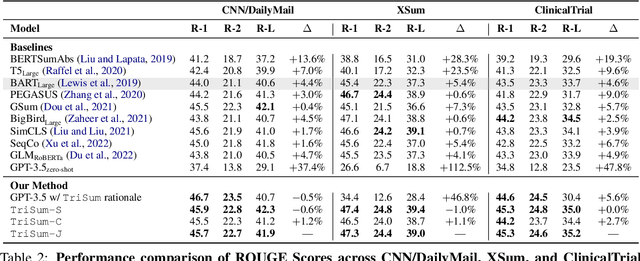
The advent of large language models (LLMs) has significantly advanced natural language processing tasks like text summarization. However, their large size and computational demands, coupled with privacy concerns in data transmission, limit their use in resource-constrained and privacy-centric settings. To overcome this, we introduce TriSum, a framework for distilling LLMs' text summarization abilities into a compact, local model. Initially, LLMs extract a set of aspect-triple rationales and summaries, which are refined using a dual-scoring method for quality. Next, a smaller local model is trained with these tasks, employing a curriculum learning strategy that evolves from simple to complex tasks. Our method enhances local model performance on various benchmarks (CNN/DailyMail, XSum, and ClinicalTrial), outperforming baselines by 4.5%, 8.5%, and 7.4%, respectively. It also improves interpretability by providing insights into the summarization rationale.
Making Pre-trained Language Models Great on Tabular Prediction
Mar 12, 2024



The transferability of deep neural networks (DNNs) has made significant progress in image and language processing. However, due to the heterogeneity among tables, such DNN bonus is still far from being well exploited on tabular data prediction (e.g., regression or classification tasks). Condensing knowledge from diverse domains, language models (LMs) possess the capability to comprehend feature names from various tables, potentially serving as versatile learners in transferring knowledge across distinct tables and diverse prediction tasks, but their discrete text representation space is inherently incompatible with numerical feature values in tables. In this paper, we present TP-BERTa, a specifically pre-trained LM for tabular data prediction. Concretely, a novel relative magnitude tokenization converts scalar numerical feature values to finely discrete, high-dimensional tokens, and an intra-feature attention approach integrates feature values with the corresponding feature names. Comprehensive experiments demonstrate that our pre-trained TP-BERTa leads the performance among tabular DNNs and is competitive with Gradient Boosted Decision Tree models in typical tabular data regime.
SERVAL: Synergy Learning between Vertical Models and LLMs towards Oracle-Level Zero-shot Medical Prediction
Mar 03, 2024



Recent development of large language models (LLMs) has exhibited impressive zero-shot proficiency on generic and common sense questions. However, LLMs' application on domain-specific vertical questions still lags behind, primarily due to the humiliation problems and deficiencies in vertical knowledge. Furthermore, the vertical data annotation process often requires labor-intensive expert involvement, thereby presenting an additional challenge in enhancing the model's vertical capabilities. In this paper, we propose SERVAL, a synergy learning pipeline designed for unsupervised development of vertical capabilities in both LLMs and small models by mutual enhancement. Specifically, SERVAL utilizes the LLM's zero-shot outputs as annotations, leveraging its confidence to teach a robust vertical model from scratch. Reversely, the trained vertical model guides the LLM fine-tuning to enhance its zero-shot capability, progressively improving both models through an iterative process. In medical domain, known for complex vertical knowledge and costly annotations, comprehensive experiments show that, without access to any gold labels, SERVAL with the synergy learning of OpenAI GPT-3.5 and a simple model attains fully-supervised competitive performance across ten widely used medical datasets. These datasets represent vertically specialized medical diagnostic scenarios (e.g., diabetes, heart diseases, COVID-19), highlighting the potential of SERVAL in refining the vertical capabilities of LLMs and training vertical models from scratch, all achieved without the need for annotations.