 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifiably Byzantine-Robust Federated Conformal Prediction
Jun 04, 2024Conformal prediction has shown impressive capacity in constructing statistically rigorous prediction sets for machine learning models with exchangeable data samples. The siloed datasets, coupled with the escalating privacy concerns related to local data sharing, have inspired recent innovations extending conformal prediction into federated environments with distributed data samples. However, this framework for distributed uncertainty quantification is susceptible to Byzantine failures. A minor subset of malicious clients can significantly compromise the practicality of coverage guarantees. To address this vulnerability, we introduce a novel framework Rob-FCP, which executes robust federated conformal prediction, effectively countering malicious clients capable of reporting arbitrary statistics with the conformal calibration process. We theoretically provide the conformal coverage bound of Rob-FCP in the Byzantine setting and show that the coverage of Rob-FCP is asymptotically close to the desired coverage level. We also propose a malicious client number estimator to tackle a more challenging setting where the number of malicious clients is unknown to the defender and theoretically shows its effectiveness. We empirically demonstrate the robustness of Rob-FCP against diverse proportions of malicious clients under a variety of Byzantine attacks on five standard benchmark and real-world healthcare datasets.
Enhancing Visual-Language Modality Alignment in Large Vision Language Models via Self-Improvement
May 29, 2024Large vision-language models (LVLMs) have achieved impressive results in various visual question-answering and reasoning tasks through vision instruction tuning on specific datasets. However, there is still significant room for improvement in the alignment between visual and language modalities. Previous methods to enhance this alignment typically require external models or data, heavily depending on their capabilities and quality, which inevitably sets an upper bound on performance. In this paper, we propose SIMA, a framework that enhances visual and language modality alignment through self-improvement, eliminating the needs for external models or data. SIMA leverages prompts from existing vision instruction tuning datasets to self-generate responses and employs an in-context self-critic mechanism to select response pairs for preference tuning. The key innovation is the introduction of three vision metrics during the in-context self-critic process, which can guide the LVLM in selecting responses that enhance image comprehension. Through experiments across 14 hallucination and comprehensive benchmarks, we demonstrate that SIMA not only improves model performance across all benchmarks but also achieves superior modality alignment, outperforming previous approaches.
KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge
May 26, 2024Knowledge Graph Embedding (KGE) techniques are crucial in learning compact representations of entities and relations within a knowledge graph, facilitating efficient reasoning and knowledge discovery. While existing methods typically focus either on training KGE models solely based on graph structure or fine-tuning pre-trained language models with classification data in KG, KG-FIT leverages LLM-guided refinement to construct a semantically coherent hierarchical structure of entity clusters. By incorporating this hierarchical knowledge along with textual information during the fine-tuning process, KG-FIT effectively captures both global semantics from the LLM and local semantics from the KG. Extensive experiments on the benchmark datasets FB15K-237, YAGO3-10, and PrimeKG demonstrate the superiority of KG-FIT over state-of-the-art pre-trained language model-based methods, achieving improvements of 14.4%, 13.5%, and 11.9% in the Hits@10 metric for the link prediction task, respectively. Furthermore, KG-FIT yields substantial performance gains of 12.6%, 6.7%, and 17.7% compared to the structure-based base models upon which it is built. These results highlight the effectiveness of KG-FIT in incorporating open-world knowledge from LLMs to significantly enhance the expressiveness and informativeness of KG embeddings.
TriSum: Learning Summarization Ability from Large Language Models with Structured Rationale
Mar 15, 2024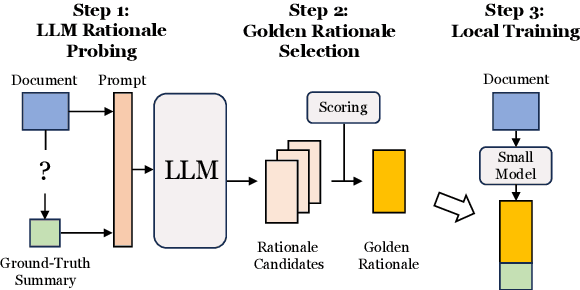
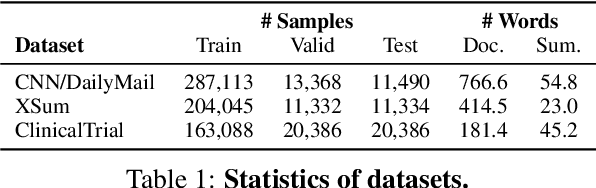
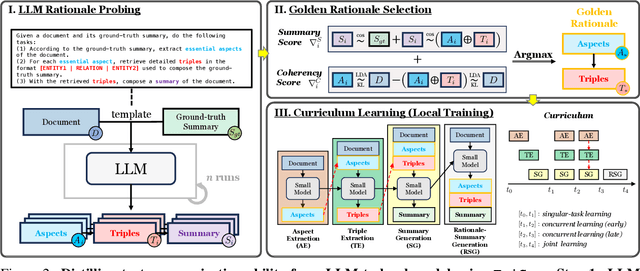
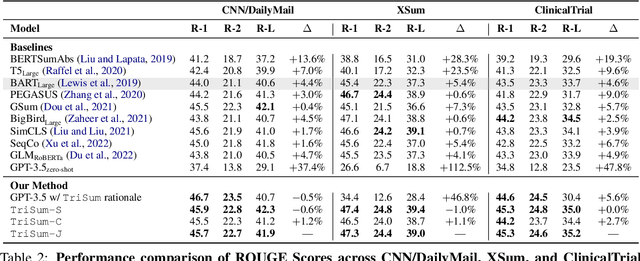
The advent of large language models (LLMs) has significantly advanced natural language processing tasks like text summarization. However, their large size and computational demands, coupled with privacy concerns in data transmission, limit their use in resource-constrained and privacy-centric settings. To overcome this, we introduce TriSum, a framework for distilling LLMs' text summarization abilities into a compact, local model. Initially, LLMs extract a set of aspect-triple rationales and summaries, which are refined using a dual-scoring method for quality. Next, a smaller local model is trained with these tasks, employing a curriculum learning strategy that evolves from simple to complex tasks. Our method enhances local model performance on various benchmarks (CNN/DailyMail, XSum, and ClinicalTrial), outperforming baselines by 4.5%, 8.5%, and 7.4%, respectively. It also improves interpretability by providing insights into the summarization rationale.
Recent Advances in Predictive Modeling with Electronic Health Records
Feb 02, 2024The development of electronic health records (EHR) systems has enabled the collection of a vast amount of digitized patient data. However, utilizing EHR data for predictive modeling presents several challenges due to its unique characteristics. With the advancements in machine learning techniques, deep learning has demonstrated its superiority in various applications, including healthcare. This survey systematically reviews recent advances in deep learning-based predictive models using EHR data. Specifically, we begin by introducing the background of EHR data and providing a mathematical definition of the predictive modeling task. We then categorize and summarize predictive deep models from multiple perspectives. Furthermore, we present benchmarks and toolkits relevant to predictive modeling in healthcare. Finally, we conclude this survey by discussing open challenges and suggesting promising directions for future research.
PILOT: Legal Case Outcome Prediction with Case Law
Jan 28, 2024Machine learning shows promise in predicting the outcome of legal cases, but most research has concentrated on civil law cases rather than case law systems. We identified two unique challenges in making legal case outcome predictions with case law. First, it is crucial to identify relevant precedent cases that serve as fundamental evidence for judges during decision-making. Second, it is necessary to consider the evolution of legal principles over time, as early cases may adhere to different legal contexts. In this paper, we proposed a new model named PILOT (PredictIng Legal case OuTcome) for case outcome prediction. It comprises two modules for relevant case retrieval and temporal pattern handling, respectively. To benchmark the performance of existing legal case outcome prediction models, we curated a dataset from a large-scale case law database. We demonstrate the importance of accurately identifying precedent cases and mitigating the temporal shift when making predictions for case law, as our method shows a significant improvement over the prior methods that focus on civil law case outcome predictions.
ConSequence: Synthesizing Logically Constrained Sequences for Electronic Health Record Generation
Dec 20, 2023Generative models can produce synthetic patient records for analytical tasks when real data is unavailable or limited. However, current methods struggle with adhering to domain-specific knowledge and removing invalid data. We present ConSequence, an effective approach to integrating domain knowledge into sequential generative neural network outputs. Our rule-based formulation includes temporal aggregation and antecedent evaluation modules, ensured by an efficient matrix multiplication formulation, to satisfy hard and soft logical constraints across time steps. Existing constraint methods often fail to guarantee constraint satisfaction, lack the ability to handle temporal constraints, and hinder the learning and computational efficiency of the model. In contrast, our approach efficiently handles all types of constraints with guaranteed logical coherence. We demonstrate ConSequence's effectiveness in generating electronic health records, outperforming competitors in achieving complete temporal and spatial constraint satisfaction without compromising runtime performance or generative quality. Specifically, ConSequence successfully prevents all rule violations while improving the model quality in reducing its test perplexity by 5% and incurring less than a 13% slowdown in generation speed compared to an unconstrained model.
Zero-Resource Hallucination Prevention for Large Language Models
Sep 12, 2023



The prevalent use of large language models (LLMs) in various domains has drawn attention to the issue of "hallucination," which refers to instances where LLMs generate factually inaccurate or ungrounded information. Existing techniques for hallucination detection in language assistants rely on intricate fuzzy, specific free-language-based chain of thought (CoT) techniques or parameter-based methods that suffer from interpretability issues. Additionally, the methods that identify hallucinations post-generation could not prevent their occurrence and suffer from inconsistent performance due to the influence of the instruction format and model style. In this paper, we introduce a novel pre-detection self-evaluation technique, referred to as SELF-FAMILIARITY, which focuses on evaluating the model's familiarity with the concepts present in the input instruction and withholding the generation of response in case of unfamiliar concepts. This approach emulates the human ability to refrain from responding to unfamiliar topics, thus reducing hallucinations. We validate SELF-FAMILIARITY across four different large language models, demonstrating consistently superior performance compared to existing techniques. Our findings propose a significant shift towards preemptive strategies for hallucination mitigation in LLM assistants, promising improvements in reliability, applicability, and interpretability.
TREEMENT: Interpretable Patient-Trial Matching via Personalized Dynamic Tree-Based Memory Network
Jul 19, 2023



Clinical trials are critical for drug development but often suffer from expensive and inefficient patient recruitment. In recent years, machine learning models have been proposed for speeding up patient recruitment via automatically matching patients with clinical trials based on longitudinal patient electronic health records (EHR) data and eligibility criteria of clinical trials. However, they either depend on trial-specific expert rules that cannot expand to other trials or perform matching at a very general level with a black-box model where the lack of interpretability makes the model results difficult to be adopted. To provide accurate and interpretable patient trial matching, we introduce a personalized dynamic tree-based memory network model named TREEMENT. It utilizes hierarchical clinical ontologies to expand the personalized patient representation learned from sequential EHR data, and then uses an attentional beam-search query learned from eligibility criteria embedding to offer a granular level of alignment for improved performance and interpretability. We evaluated TREEMENT against existing models on real-world datasets and demonstrated that TREEMENT outperforms the best baseline by 7% in terms of error reduction in criteria-level matching and achieves state-of-the-art results in its trial-level matching ability. Furthermore, we also show TREEMENT can offer good interpretability to make the model results easier for adoption.
PyTrial: A Comprehensive Platform for Artificial Intelligence for Drug Development
Jun 06, 2023



Drug development is a complex process that aims to test the efficacy and safety of candidate drugs in the human body for regulatory approval via clinical trials. Recently, machine learning has emerged as a vital tool for drug development, offering new opportunities to improve the efficiency and success rates of the process. To facilitate the research and development of artificial intelligence (AI) for drug development, we developed a Python package, namely PyTrial, that implements various clinical trial tasks supported by AI algorithms. To be specific, PyTrial implements 6 essential drug development tasks, including patient outcome prediction, trial site selection, trial outcome prediction, patient-trial matching, trial similarity search, and synthetic data generation. In PyTrial, all tasks are defined by four steps: load data, model definition, model training, and model evaluation, which can be done with a couple of lines of code. In addition, the modular API design allows practitioners to extend the framework to new algorithms and tasks easily. PyTrial is featured for a unified API, detailed documentation, and interactive examples with preprocessed benchmark data for all implemented algorithms. This package can be installed through Python Package Index (PyPI) and is publicly available at https://github.com/RyanWangZf/PyTrial.