 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Graph Contrastive Learning: A Survey and Beyond
May 20, 2024In recent years, deep learning on graphs has achieved remarkable success in various domains. However, the reliance on annotated graph data remains a significant bottleneck due to its prohibitive cost and time-intensive nature. To address this challenge, self-supervised learning (SSL) on graphs has gained increasing attention and has made significant progress. SSL enables machine learning models to produce informative representations from unlabeled graph data, reducing the reliance on expensive labeled data. While SSL on graphs has witnessed widespread adoption, one critical component, Graph Contrastive Learning (GCL), has not been thoroughly investigated in the existing literature. Thus, this survey aims to fill this gap by offering a dedicated survey on GCL. We provide a comprehensive overview of the fundamental principles of GCL, including data augmentation strategies, contrastive modes, and contrastive optimization objectives. Furthermore, we explore the extensions of GCL to other aspects of data-efficient graph learning, such as weakly supervised learning, transfer learning, and related scenarios. We also discuss practical applications spanning domains such as drug discovery, genomics analysis, recommender systems, and finally outline the challenges and potential future directions in this field.
CoRelation: Boosting Automatic ICD Coding Through Contextualized Code Relation Learning
Feb 24, 2024Automatic International Classification of Diseases (ICD) coding plays a crucial role in the extraction of relevant information from clinical notes for proper recording and billing. One of the most important directions for boosting the performance of automatic ICD coding is modeling ICD code relations. However, current methods insufficiently model the intricate relationships among ICD codes and often overlook the importance of context in clinical notes. In this paper, we propose a novel approach, a contextualized and flexible framework, to enhance the learning of ICD code representations. Our approach, unlike existing methods, employs a dependent learning paradigm that considers the context of clinical notes in modeling all possible code relations. We evaluate our approach on six public ICD coding datasets and the experimental results demonstrate the effectiveness of our approach compared to state-of-the-art baselines.
Recent Advances in Predictive Modeling with Electronic Health Records
Feb 02, 2024The development of electronic health records (EHR) systems has enabled the collection of a vast amount of digitized patient data. However, utilizing EHR data for predictive modeling presents several challenges due to its unique characteristics. With the advancements in machine learning techniques, deep learning has demonstrated its superiority in various applications, including healthcare. This survey systematically reviews recent advances in deep learning-based predictive models using EHR data. Specifically, we begin by introducing the background of EHR data and providing a mathematical definition of the predictive modeling task. We then categorize and summarize predictive deep models from multiple perspectives. Furthermore, we present benchmarks and toolkits relevant to predictive modeling in healthcare. Finally, we conclude this survey by discussing open challenges and suggesting promising directions for future research.
A Survey of Data-Efficient Graph Learning
Feb 01, 2024Graph-structured data, prevalent in domains ranging from social networks to biochemical analysis, serve as the foundation for diverse real-world systems. While graph neural networks demonstrate proficiency in modeling this type of data, their success is often reliant on significant amounts of labeled data, posing a challenge in practical scenarios with limited annotation resources. To tackle this problem, tremendous efforts have been devoted to enhancing graph machine learning performance under low-resource settings by exploring various approaches to minimal supervision. In this paper, we introduce a novel concept of Data-Efficient Graph Learning (DEGL) as a research frontier, and present the first survey that summarizes the current progress of DEGL. We initiate by highlighting the challenges inherent in training models with large labeled data, paving the way for our exploration into DEGL. Next, we systematically review recent advances on this topic from several key aspects, including self-supervised graph learning, semi-supervised graph learning, and few-shot graph learning. Also, we state promising directions for future research, contributing to the evolution of graph machine learning.
Hierarchical Pretraining on Multimodal Electronic Health Records
Oct 20, 2023



Pretraining has proven to be a powerful technique in natural language processing (NLP), exhibiting remarkable success in various NLP downstream tasks. However, in the medical domain, existing pretrained models on electronic health records (EHR) fail to capture the hierarchical nature of EHR data, limiting their generalization capability across diverse downstream tasks using a single pretrained model. To tackle this challenge, this paper introduces a novel, general, and unified pretraining framework called MEDHMP, specifically designed for hierarchically multimodal EHR data. The effectiveness of the proposed MEDHMP is demonstrated through experimental results on eight downstream tasks spanning three levels. Comparisons against eighteen baselines further highlight the efficacy of our approach.
Zero-Resource Hallucination Prevention for Large Language Models
Sep 12, 2023



The prevalent use of large language models (LLMs) in various domains has drawn attention to the issue of "hallucination," which refers to instances where LLMs generate factually inaccurate or ungrounded information. Existing techniques for hallucination detection in language assistants rely on intricate fuzzy, specific free-language-based chain of thought (CoT) techniques or parameter-based methods that suffer from interpretability issues. Additionally, the methods that identify hallucinations post-generation could not prevent their occurrence and suffer from inconsistent performance due to the influence of the instruction format and model style. In this paper, we introduce a novel pre-detection self-evaluation technique, referred to as SELF-FAMILIARITY, which focuses on evaluating the model's familiarity with the concepts present in the input instruction and withholding the generation of response in case of unfamiliar concepts. This approach emulates the human ability to refrain from responding to unfamiliar topics, thus reducing hallucinations. We validate SELF-FAMILIARITY across four different large language models, demonstrating consistently superior performance compared to existing techniques. Our findings propose a significant shift towards preemptive strategies for hallucination mitigation in LLM assistants, promising improvements in reliability, applicability, and interpretability.
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
Apr 13, 2022



3D visual grounding aims to locate the referred target object in 3D point cloud scenes according to a free-form language description. Previous methods mostly follow a two-stage paradigm, i.e., language-irrelevant detection and cross-modal matching, which is limited by the isolated architecture. In such a paradigm, the detector needs to sample keypoints from raw point clouds due to the inherent properties of 3D point clouds (irregular and large-scale), to generate the corresponding object proposal for each keypoint. However, sparse proposals may leave out the target in detection, while dense proposals may confuse the matching model. Moreover, the language-irrelevant detection stage can only sample a small proportion of keypoints on the target, deteriorating the target prediction. In this paper, we propose a 3D Single-Stage Referred Point Progressive Selection (3D-SPS) method, which progressively selects keypoints with the guidance of language and directly locates the target. Specifically, we propose a Description-aware Keypoint Sampling (DKS) module to coarsely focus on the points of language-relevant objects, which are significant clues for grounding. Besides, we devise a Target-oriented Progressive Mining (TPM) module to finely concentrate on the points of the target, which is enabled by progressive intra-modal relation modeling and inter-modal target mining. 3D-SPS bridges the gap between detection and matching in the 3D visual grounding task, localizing the target at a single stage. Experiments demonstrate that 3D-SPS achieves state-of-the-art performance on both ScanRefer and Nr3D/Sr3D datasets.
MedAttacker: Exploring Black-Box Adversarial Attacks on Risk Prediction Models in Healthcare
Dec 11, 2021



Deep neural networks (DNNs) have been broadly adopted in health risk prediction to provide healthcare diagnoses and treatments. To evaluate their robustness, existing research conducts adversarial attacks in the white/gray-box setting where model parameters are accessible. However, a more realistic black-box adversarial attack is ignored even though most real-world models are trained with private data and released as black-box services on the cloud. To fill this gap, we propose the first black-box adversarial attack method against health risk prediction models named MedAttacker to investigate their vulnerability. MedAttacker addresses the challenges brought by EHR data via two steps: hierarchical position selection which selects the attacked positions in a reinforcement learning (RL) framework and substitute selection which identifies substitute with a score-based principle. Particularly, by considering the temporal context inside EHRs, it initializes its RL position selection policy by using the contribution score of each visit and the saliency score of each code, which can be well integrated with the deterministic substitute selection process decided by the score changes. In experiments, MedAttacker consistently achieves the highest average success rate and even outperforms a recent white-box EHR adversarial attack technique in certain cases when attacking three advanced health risk prediction models in the black-box setting across multiple real-world datasets. In addition, based on the experiment results we include a discussion on defending EHR adversarial attacks.
FedSkel: Efficient Federated Learning on Heterogeneous Systems with Skeleton Gradients Update
Aug 20, 2021



Federated learning aims to protect users' privacy while performing data analysis from different participants. However, it is challenging to guarantee the training efficiency on heterogeneous systems due to the various computational capabilities and communication bottlenecks. In this work, we propose FedSkel to enable computation-efficient and communication-efficient federated learning on edge devices by only updating the model's essential parts, named skeleton networks. FedSkel is evaluated on real edge devices with imbalanced datasets. Experimental results show that it could achieve up to 5.52$\times$ speedups for CONV layers' back-propagation, 1.82$\times$ speedups for the whole training process, and reduce 64.8% communication cost, with negligible accuracy loss.
TransRefer3D: Entity-and-Relation Aware Transformer for Fine-Grained 3D Visual Grounding
Aug 11, 2021
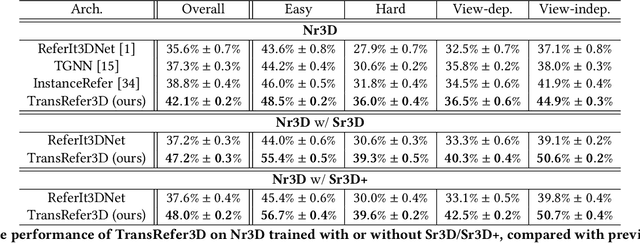


Recently proposed fine-grained 3D visual grounding is an essential and challenging task, whose goal is to identify the 3D object referred by a natural language sentence from other distractive objects of the same category. Existing works usually adopt dynamic graph networks to indirectly model the intra/inter-modal interactions, making the model difficult to distinguish the referred object from distractors due to the monolithic representations of visual and linguistic contents. In this work, we exploit Transformer for its natural suitability on permutation-invariant 3D point clouds data and propose a TransRefer3D network to extract entity-and-relation aware multimodal context among objects for more discriminative feature learning. Concretely, we devise an Entity-aware Attention (EA) module and a Relation-aware Attention (RA) module to conduct fine-grained cross-modal feature matching. Facilitated by co-attention operation, our EA module matches visual entity features with linguistic entity features while RA module matches pair-wise visual relation features with linguistic relation features, respectively. We further integrate EA and RA modules into an Entity-and-Relation aware Contextual Block (ERCB) and stack several ERCBs to form our TransRefer3D for hierarchical multimodal context modeling. Extensive experiments on both Nr3D and Sr3D datasets demonstrate that our proposed model significantly outperforms existing approaches by up to 10.6% and claims the new state-of-the-art. To the best of our knowledge, this is the first work investigating Transformer architecture for fine-grained 3D visual grounding task.