 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Graph Learning Improve Task Planning?
May 29, 2024Task planning is emerging as an important research topic alongside the development of large language models (LLMs). It aims to break down complex user requests into solvable sub-tasks, thereby fulfilling the original requests. In this context, the sub-tasks can be naturally viewed as a graph, where the nodes represent the sub-tasks, and the edges denote the dependencies among them. Consequently, task planning is a decision-making problem that involves selecting a connected path or subgraph within the corresponding graph and invoking it. In this paper, we explore graph learning-based methods for task planning, a direction that is orthogonal to the prevalent focus on prompt design. Our interest in graph learning stems from a theoretical discovery: the biases of attention and auto-regressive loss impede LLMs' ability to effectively navigate decision-making on graphs, which is adeptly addressed by graph neural networks (GNNs). This theoretical insight led us to integrate GNNs with LLMs to enhance overall performance. Extensive experiments demonstrate that GNN-based methods surpass existing solutions even without training, and minimal training can further enhance their performance. Additionally, our approach complements prompt engineering and fine-tuning techniques, with performance further enhanced by improved prompts or a fine-tuned model.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024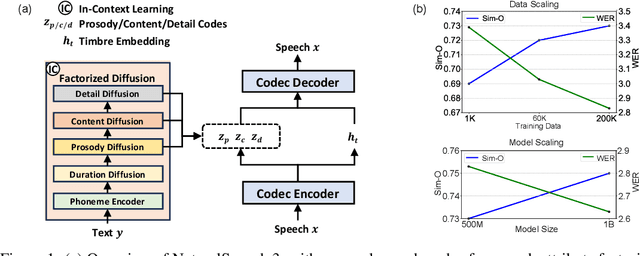
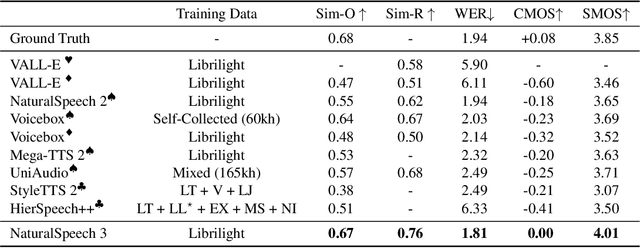
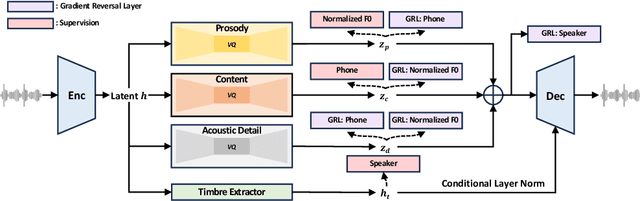
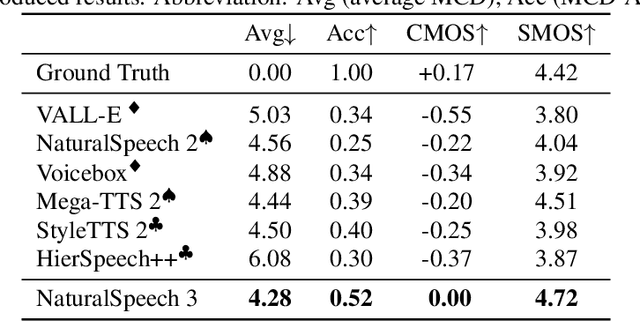
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
EASYTOOL: Enhancing LLM-based Agents with Concise Tool Instruction
Jan 11, 2024To address intricate real-world tasks, there has been a rising interest in tool utilization in applications of large language models (LLMs). To develop LLM-based agents, it usually requires LLMs to understand many tool functions from different tool documentation. But these documentations could be diverse, redundant or incomplete, which immensely affects the capability of LLMs in using tools. To solve this, we introduce EASYTOOL, a framework transforming diverse and lengthy tool documentation into a unified and concise tool instruction for easier tool usage. EasyTool purifies essential information from extensive tool documentation of different sources, and elaborates a unified interface (i.e., tool instruction) to offer standardized tool descriptions and functionalities for LLM-based agents. Extensive experiments on multiple different tasks demonstrate that EasyTool can significantly reduce token consumption and improve the performance of tool utilization in real-world scenarios. Our code will be available at \url{https://github.com/microsoft/JARVIS/} in the future.
EEGFormer: Towards Transferable and Interpretable Large-Scale EEG Foundation Model
Jan 11, 2024Self-supervised learning has emerged as a highly effective approach in the fields of natural language processing and computer vision. It is also applicable to brain signals such as electroencephalography (EEG) data, given the abundance of available unlabeled data that exist in a wide spectrum of real-world medical applications ranging from seizure detection to wave analysis. The existing works leveraging self-supervised learning on EEG modeling mainly focus on pretraining upon each individual dataset corresponding to a single downstream task, which cannot leverage the power of abundant data, and they may derive sub-optimal solutions with a lack of generalization. Moreover, these methods rely on end-to-end model learning which is not easy for humans to understand. In this paper, we present a novel EEG foundation model, namely EEGFormer, pretrained on large-scale compound EEG data. The pretrained model cannot only learn universal representations on EEG signals with adaptable performance on various downstream tasks but also provide interpretable outcomes of the useful patterns within the data. To validate the effectiveness of our model, we extensively evaluate it on various downstream tasks and assess the performance under different transfer settings. Furthermore, we demonstrate how the learned model exhibits transferable anomaly detection performance and provides valuable interpretability of the acquired patterns via self-supervised learning.
TaskBench: Benchmarking Large Language Models for Task Automation
Nov 30, 2023Recently, the incredible progress of large language models (LLMs) has ignited the spark of task automation, which decomposes the complex tasks described by user instructions into sub-tasks, and invokes external tools to execute them, and plays a central role in autonomous agents. However, there lacks a systematic and standardized benchmark to foster the development of LLMs in task automation. To this end, we introduce TaskBench to evaluate the capability of LLMs in task automation. Specifically, task automation can be formulated into three critical stages: task decomposition, tool invocation, and parameter prediction to fulfill user intent. This complexity makes data collection and evaluation more challenging compared to common NLP tasks. To generate high-quality evaluation datasets, we introduce the concept of Tool Graph to represent the decomposed tasks in user intent, and adopt a back-instruct method to simulate user instruction and annotations. Furthermore, we propose TaskEval to evaluate the capability of LLMs from different aspects, including task decomposition, tool invocation, and parameter prediction. Experimental results demonstrate that TaskBench can effectively reflects the capability of LLMs in task automation. Benefiting from the mixture of automated data construction and human verification, TaskBench achieves a high consistency compared to the human evaluation, which can be utilized as a comprehensive and faithful benchmark for LLM-based autonomous agents.
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
Oct 25, 2023



AI-empowered music processing is a diverse field that encompasses dozens of tasks, ranging from generation tasks (e.g., timbre synthesis) to comprehension tasks (e.g., music classification). For developers and amateurs, it is very difficult to grasp all of these task to satisfy their requirements in music processing, especially considering the huge differences in the representations of music data and the model applicability across platforms among various tasks. Consequently, it is necessary to build a system to organize and integrate these tasks, and thus help practitioners to automatically analyze their demand and call suitable tools as solutions to fulfill their requirements. Inspired by the recent success of large language models (LLMs) in task automation, we develop a system, named MusicAgent, which integrates numerous music-related tools and an autonomous workflow to address user requirements. More specifically, we build 1) toolset that collects tools from diverse sources, including Hugging Face, GitHub, and Web API, etc. 2) an autonomous workflow empowered by LLMs (e.g., ChatGPT) to organize these tools and automatically decompose user requests into multiple sub-tasks and invoke corresponding music tools. The primary goal of this system is to free users from the intricacies of AI-music tools, enabling them to concentrate on the creative aspect. By granting users the freedom to effortlessly combine tools, the system offers a seamless and enriching music experience.
Learning To Teach Large Language Models Logical Reasoning
Oct 13, 2023Large language models (LLMs) have gained enormous attention from both academia and industry, due to their exceptional ability in language generation and extremely powerful generalization. However, current LLMs still output unreliable content in practical reasoning tasks due to their inherent issues (e.g., hallucination). To better disentangle this problem, in this paper, we conduct an in-depth investigation to systematically explore the capability of LLMs in logical reasoning. More in detail, we first investigate the deficiency of LLMs in logical reasoning on different tasks, including event relation extraction and deductive reasoning. Our study demonstrates that LLMs are not good reasoners in solving tasks with rigorous reasoning and will produce counterfactual answers, which require us to iteratively refine. Therefore, we comprehensively explore different strategies to endow LLMs with logical reasoning ability, and thus enable them to generate more logically consistent answers across different scenarios. Based on our approach, we also contribute a synthesized dataset (LLM-LR) involving multi-hop reasoning for evaluation and pre-training. Extensive quantitative and qualitative analyses on different tasks also validate the effectiveness and necessity of teaching LLMs with logic and provide insights for solving practical tasks with LLMs in future work.
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Sep 15, 2023



Large Language Models (LLMs) excel in various tasks, but they rely on carefully crafted prompts that often demand substantial human effort. To automate this process, in this paper, we propose a novel framework for discrete prompt optimization, called EvoPrompt, which borrows the idea of evolutionary algorithms (EAs) as they exhibit good performance and fast convergence. To enable EAs to work on discrete prompts, which are natural language expressions that need to be coherent and human-readable, we connect LLMs with EAs. This approach allows us to simultaneously leverage the powerful language processing capabilities of LLMs and the efficient optimization performance of EAs. Specifically, abstaining from any gradients or parameters, EvoPrompt starts from a population of prompts and iteratively generates new prompts with LLMs based on the evolutionary operators, improving the population based on the development set. We optimize prompts for both closed- and open-source LLMs including GPT-3.5 and Alpaca, on 9 datasets spanning language understanding and generation tasks. EvoPrompt significantly outperforms human-engineered prompts and existing methods for automatic prompt generation by up to 25% and 14% respectively. Furthermore, EvoPrompt demonstrates that connecting LLMs with EAs creates synergies, which could inspire further research on the combination of LLMs and conventional algorithms.
PromptTTS 2: Describing and Generating Voices with Text Prompt
Sep 05, 2023



Speech conveys more information than just text, as the same word can be uttered in various voices to convey diverse information. Compared to traditional text-to-speech (TTS) methods relying on speech prompts (reference speech) for voice variability, using text prompts (descriptions) is more user-friendly since speech prompts can be hard to find or may not exist at all. TTS approaches based on the text prompt face two challenges: 1) the one-to-many problem, where not all details about voice variability can be described in the text prompt, and 2) the limited availability of text prompt datasets, where vendors and large cost of data labeling are required to write text prompt for speech. In this work, we introduce PromptTTS 2 to address these challenges with a variation network to provide variability information of voice not captured by text prompts, and a prompt generation pipeline to utilize the large language models (LLM) to compose high quality text prompts. Specifically, the variation network predicts the representation extracted from the reference speech (which contains full information about voice) based on the text prompt representation. For the prompt generation pipeline, it generates text prompts for speech with a speech understanding model to recognize voice attributes (e.g., gender, speed) from speech and a large language model to formulate text prompt based on the recognition results. Experiments on a large-scale (44K hours) speech dataset demonstrate that compared to the previous works, PromptTTS 2 generates voices more consistent with text prompts and supports the sampling of diverse voice variability, thereby offering users more choices on voice generation. Additionally, the prompt generation pipeline produces high-quality prompts, eliminating the large labeling cost. The demo page of PromptTTS 2 is available online\footnote{https://speechresearch.github.io/prompttts2}.
End-to-End Word-Level Pronunciation Assessment with MASK Pre-training
Jun 05, 2023



Pronunciation assessment is a major challenge in the computer-aided pronunciation training system, especially at the word (phoneme)-level. To obtain word (phoneme)-level scores, current methods usually rely on aligning components to obtain acoustic features of each word (phoneme), which limits the performance of assessment to the accuracy of alignments. Therefore, to address this problem, we propose a simple yet effective method, namely \underline{M}asked pre-training for \underline{P}ronunciation \underline{A}ssessment (MPA). Specifically, by incorporating a mask-predict strategy, our MPA supports end-to-end training without leveraging any aligning components and can solve misalignment issues to a large extent during prediction. Furthermore, we design two evaluation strategies to enable our model to conduct assessments in both unsupervised and supervised settings. Experimental results on SpeechOcean762 dataset demonstrate that MPA could achieve better performance than previous methods, without any explicit alignment. In spite of this, MPA still has some limitations, such as requiring more inference time and reference text. They expect to be addressed in future work.