 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Active Multi-Task Learning in Reinforcement Learning from Human Feedback
May 18, 2024Reinforcement learning from human feedback (RLHF) has contributed to performance improvements in large language models. To tackle its reliance on substantial amounts of human-labeled data, a successful approach is multi-task representation learning, which involves learning a high-quality, low-dimensional representation from a wide range of source tasks. In this paper, we formulate RLHF as the contextual dueling bandit problem and assume a common linear representation. We demonstrate that the sample complexity of source tasks in multi-task RLHF can be reduced by considering task relevance and allocating different sample sizes to source tasks with varying task relevance. We further propose an algorithm to estimate task relevance by a small number of additional data and then learn a policy. We prove that to achieve $\varepsilon-$optimal, the sample complexity of the source tasks can be significantly reduced compared to uniform sampling. Additionally, the sample complexity of the target task is only linear in the dimension of the latent space, thanks to representation learning.
DPO Meets PPO: Reinforced Token Optimization for RLHF
Apr 29, 2024In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (\texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, \texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, \texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Apr 03, 2024We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.80, inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Beyond Embeddings: The Promise of Visual Table in Multi-Modal Models
Mar 27, 2024



Visual representation learning has been a cornerstone in computer vision, evolving from supervised learning with human-annotated labels to aligning image-text pairs from the Internet. Despite recent advancements in multi-modal large language models (MLLMs), the visual representations they rely on, such as CLIP embeddings, often lack access to external world knowledge critical for real-world visual reasoning. In this work, we propose Visual Table, a novel visual representation tailored for MLLMs. It provides hierarchical text descriptions of holistic visual scenes, consisting of a scene description and multiple object-centric descriptions that encompass categories, attributes, and knowledge at instance level. We further develop a scalable generator for visual table generation and train it on small-scale annotations from GPT4V. Extensive evaluations demonstrate that, with generated visual tables as additional visual representations, our model can consistently outperform the state-of-the-art (SOTA) MLLMs across diverse benchmarks. When visual tables serve as standalone visual representations, our model can closely match or even beat the SOTA MLLMs that are built on CLIP visual embeddings. Our code is available at https://github.com/LaVi-Lab/Visual-Table.
GiT: Towards Generalist Vision Transformer through Universal Language Interface
Mar 14, 2024



This paper proposes a simple, yet effective framework, called GiT, simultaneously applicable for various vision tasks only with a vanilla ViT. Motivated by the universality of the Multi-layer Transformer architecture (e.g, GPT) widely used in large language models (LLMs), we seek to broaden its scope to serve as a powerful vision foundation model (VFM). However, unlike language modeling, visual tasks typically require specific modules, such as bounding box heads for detection and pixel decoders for segmentation, greatly hindering the application of powerful multi-layer transformers in the vision domain. To solve this, we design a universal language interface that empowers the successful auto-regressive decoding to adeptly unify various visual tasks, from image-level understanding (e.g., captioning), over sparse perception (e.g., detection), to dense prediction (e.g., segmentation). Based on the above designs, the entire model is composed solely of a ViT, without any specific additions, offering a remarkable architectural simplification. GiT is a multi-task visual model, jointly trained across five representative benchmarks without task-specific fine-tuning. Interestingly, our GiT builds a new benchmark in generalist performance, and fosters mutual enhancement across tasks, leading to significant improvements compared to isolated training. This reflects a similar impact observed in LLMs. Further enriching training with 27 datasets, GiT achieves strong zero-shot results over various tasks. Due to its simple design, this paradigm holds promise for narrowing the architectural gap between vision and language. Code and models will be available at \url{https://github.com/Haiyang-W/GiT}.
On Cyclical MCMC Sampling
Mar 01, 2024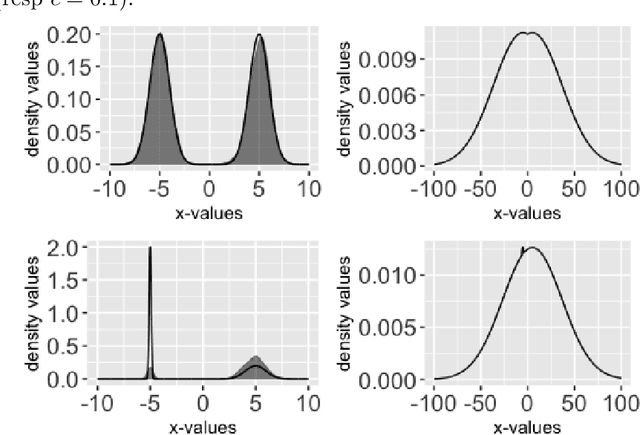
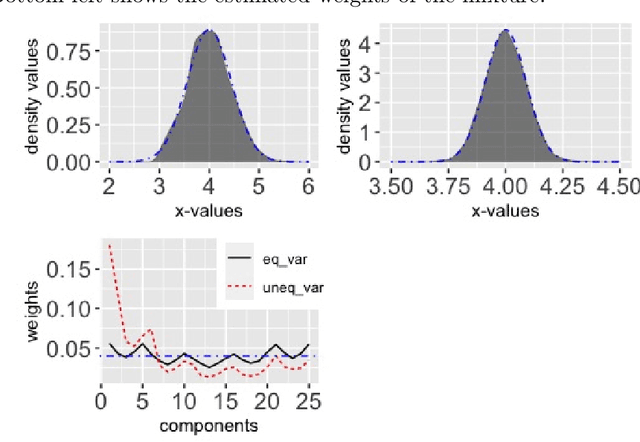
Cyclical MCMC is a novel MCMC framework recently proposed by Zhang et al. (2019) to address the challenge posed by high-dimensional multimodal posterior distributions like those arising in deep learning. The algorithm works by generating a nonhomogeneous Markov chain that tracks -- cyclically in time -- tempered versions of the target distribution. We show in this work that cyclical MCMC converges to the desired probability distribution in settings where the Markov kernels used are fast mixing, and sufficiently long cycles are employed. However in the far more common settings of slow mixing kernels, the algorithm may fail to produce samples from the desired distribution. In particular, in a simple mixture example with unequal variance, we show by simulation that cyclical MCMC fails to converge to the desired limit. Finally, we show that cyclical MCMC typically estimates well the local shape of the target distribution around each mode, even when we do not have convergence to the target.
Do Efficient Transformers Really Save Computation?
Feb 21, 2024



As transformer-based language models are trained on increasingly large datasets and with vast numbers of parameters, finding more efficient alternatives to the standard Transformer has become very valuable. While many efficient Transformers and Transformer alternatives have been proposed, none provide theoretical guarantees that they are a suitable replacement for the standard Transformer. This makes it challenging to identify when to use a specific model and what directions to prioritize for further investigation. In this paper, we aim to understand the capabilities and limitations of efficient Transformers, specifically the Sparse Transformer and the Linear Transformer. We focus on their reasoning capability as exhibited by Chain-of-Thought (CoT) prompts and follow previous works to model them as Dynamic Programming (DP) problems. Our results show that while these models are expressive enough to solve general DP tasks, contrary to expectations, they require a model size that scales with the problem size. Nonetheless, we identify a class of DP problems for which these models can be more efficient than the standard Transformer. We confirm our theoretical results through experiments on representative DP tasks, adding to the understanding of efficient Transformers' practical strengths and weaknesses.
DOF: Accelerating High-order Differential Operators with Forward Propagation
Feb 15, 2024Solving partial differential equations (PDEs) efficiently is essential for analyzing complex physical systems. Recent advancements in leveraging deep learning for solving PDE have shown significant promise. However, machine learning methods, such as Physics-Informed Neural Networks (PINN), face challenges in handling high-order derivatives of neural network-parameterized functions. Inspired by Forward Laplacian, a recent method of accelerating Laplacian computation, we propose an efficient computational framework, Differential Operator with Forward-propagation (DOF), for calculating general second-order differential operators without losing any precision. We provide rigorous proof of the advantages of our method over existing methods, demonstrating two times improvement in efficiency and reduced memory consumption on any architectures. Empirical results illustrate that our method surpasses traditional automatic differentiation (AutoDiff) techniques, achieving 2x improvement on the MLP structure and nearly 20x improvement on the MLP with Jacobian sparsity.
Two Stones Hit One Bird: Bilevel Positional Encoding for Better Length Extrapolation
Jan 29, 2024In this work, we leverage the intrinsic segmentation of language sequences and design a new positional encoding method called Bilevel Positional Encoding (BiPE). For each position, our BiPE blends an intra-segment encoding and an inter-segment encoding. The intra-segment encoding identifies the locations within a segment and helps the model capture the semantic information therein via absolute positional encoding. The inter-segment encoding specifies the segment index, models the relationships between segments, and aims to improve extrapolation capabilities via relative positional encoding. Theoretical analysis shows this disentanglement of positional information makes learning more effective. The empirical results also show that our BiPE has superior length extrapolation capabilities across a wide range of tasks in diverse text modalities.
Deep Learning with Information Fusion and Model Interpretation for Health Monitoring of Fetus based on Long-term Prenatal Electronic Fetal Heart Rate Monitoring Data
Jan 27, 2024Long-term fetal heart rate (FHR) monitoring during the antepartum period, increasingly popularized by electronic FHR monitoring, represents a growing approach in FHR monitoring. This kind of continuous monitoring, in contrast to the short-term one, collects an extended period of fetal heart data. This offers a more comprehensive understanding of fetus's conditions. However, the interpretation of long-term antenatal fetal heart monitoring is still in its early stages, lacking corresponding clinical standards. Furthermore, the substantial amount of data generated by continuous monitoring imposes a significant burden on clinical work when analyzed manually. To address above challenges, this study develops an automatic analysis system named LARA (Long-term Antepartum Risk Analysis system) for continuous FHR monitoring, combining deep learning and information fusion methods. LARA's core is a well-established convolutional neural network (CNN) model. It processes long-term FHR data as input and generates a Risk Distribution Map (RDM) and Risk Index (RI) as the analysis results. We evaluate LARA on inner test dataset, the performance metrics are as follows: AUC 0.872, accuracy 0.816, specificity 0.811, sensitivity 0.806, precision 0.271, and F1 score 0.415. In our study, we observe that long-term FHR monitoring data with higher RI is more likely to result in adverse outcomes (p=0.0021). In conclusion, this study introduces LARA, the first automated analysis system for long-term FHR monitoring, initiating the further explorations into its clinical value in the future.