 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Wang
Multi-Stream Keypoint Attention Network for Sign Language Recognition and Translation
May 09, 2024
Sign language serves as a non-vocal means of communication, transmitting information and significance through gestures, facial expressions, and bodily movements. The majority of current approaches for sign language recognition (SLR) and translation rely on RGB video inputs, which are vulnerable to fluctuations in the background. Employing a keypoint-based strategy not only mitigates the effects of background alterations but also substantially diminishes the computational demands of the model. Nevertheless, contemporary keypoint-based methodologies fail to fully harness the implicit knowledge embedded in keypoint sequences. To tackle this challenge, our inspiration is derived from the human cognition mechanism, which discerns sign language by analyzing the interplay between gesture configurations and supplementary elements. We propose a multi-stream keypoint attention network to depict a sequence of keypoints produced by a readily available keypoint estimator. In order to facilitate interaction across multiple streams, we investigate diverse methodologies such as keypoint fusion strategies, head fusion, and self-distillation. The resulting framework is denoted as MSKA-SLR, which is expanded into a sign language translation (SLT) model through the straightforward addition of an extra translation network. We carry out comprehensive experiments on well-known benchmarks like Phoenix-2014, Phoenix-2014T, and CSL-Daily to showcase the efficacy of our methodology. Notably, we have attained a novel state-of-the-art performance in the sign language translation task of Phoenix-2014T. The code and models can be accessed at: https://github.com/sutwangyan/MSKA.
A Causal Explainable Guardrails for Large Language Models
May 07, 2024Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs towards desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardaril, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardaril systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardaril's effectiveness in steering LLMs towards desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes. We discuss the limitations and future research directions, highlighting the need for ongoing research to address the ethical implications of large language models.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
I$^3$Net: Inter-Intra-slice Interpolation Network for Medical Slice Synthesis
May 05, 2024



Medical imaging is limited by acquisition time and scanning equipment. CT and MR volumes, reconstructed with thicker slices, are anisotropic with high in-plane resolution and low through-plane resolution. We reveal an intriguing phenomenon that due to the mentioned nature of data, performing slice-wise interpolation from the axial view can yield greater benefits than performing super-resolution from other views. Based on this observation, we propose an Inter-Intra-slice Interpolation Network (I$^3$Net), which fully explores information from high in-plane resolution and compensates for low through-plane resolution. The through-plane branch supplements the limited information contained in low through-plane resolution from high in-plane resolution and enables continual and diverse feature learning. In-plane branch transforms features to the frequency domain and enforces an equal learning opportunity for all frequency bands in a global context learning paradigm. We further propose a cross-view block to take advantage of the information from all three views online. Extensive experiments on two public datasets demonstrate the effectiveness of I$^3$Net, and noticeably outperforms state-of-the-art super-resolution, video frame interpolation and slice interpolation methods by a large margin. We achieve 43.90dB in PSNR, with at least 1.14dB improvement under the upscale factor of $\times$2 on MSD dataset with faster inference. Code is available at https://github.com/DeepMed-Lab-ECNU/Medical-Image-Reconstruction.
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities
Apr 25, 2024



Multimodal sentiment analysis (MSA) aims to understand human sentiment through multimodal data. Most MSA efforts are based on the assumption of modality completeness. However, in real-world applications, some practical factors cause uncertain modality missingness, which drastically degrades the model's performance. To this end, we propose a Correlation-decoupled Knowledge Distillation (CorrKD) framework for the MSA task under uncertain missing modalities. Specifically, we present a sample-level contrastive distillation mechanism that transfers comprehensive knowledge containing cross-sample correlations to reconstruct missing semantics. Moreover, a category-guided prototype distillation mechanism is introduced to capture cross-category correlations using category prototypes to align feature distributions and generate favorable joint representations. Eventually, we design a response-disentangled consistency distillation strategy to optimize the sentiment decision boundaries of the student network through response disentanglement and mutual information maximization. Comprehensive experiments on three datasets indicate that our framework can achieve favorable improvements compared with several baselines.
Adaptive Prompt Learning with Negative Textual Semantics and Uncertainty Modeling for Universal Multi-Source Domain Adaptation
Apr 24, 2024



Universal Multi-source Domain Adaptation (UniMDA) transfers knowledge from multiple labeled source domains to an unlabeled target domain under domain shifts (different data distribution) and class shifts (unknown target classes). Existing solutions focus on excavating image features to detect unknown samples, ignoring abundant information contained in textual semantics. In this paper, we propose an Adaptive Prompt learning with Negative textual semantics and uncErtainty modeling method based on Contrastive Language-Image Pre-training (APNE-CLIP) for UniMDA classification tasks. Concretely, we utilize the CLIP with adaptive prompts to leverage textual information of class semantics and domain representations, helping the model identify unknown samples and address domain shifts. Additionally, we design a novel global instance-level alignment objective by utilizing negative textual semantics to achieve more precise image-text pair alignment. Furthermore, we propose an energy-based uncertainty modeling strategy to enlarge the margin distance between known and unknown samples. Extensive experiments demonstrate the superiority of our proposed method.
Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning
Apr 23, 2024Generative Zero-shot learning (ZSL) learns a generator to synthesize visual samples for unseen classes, which is an effective way to advance ZSL. However, existing generative methods rely on the conditions of Gaussian noise and the predefined semantic prototype, which limit the generator only optimized on specific seen classes rather than characterizing each visual instance, resulting in poor generalizations (\textit{e.g.}, overfitting to seen classes). To address this issue, we propose a novel Visual-Augmented Dynamic Semantic prototype method (termed VADS) to boost the generator to learn accurate semantic-visual mapping by fully exploiting the visual-augmented knowledge into semantic conditions. In detail, VADS consists of two modules: (1) Visual-aware Domain Knowledge Learning module (VDKL) learns the local bias and global prior of the visual features (referred to as domain visual knowledge), which replace pure Gaussian noise to provide richer prior noise information; (2) Vision-Oriented Semantic Updation module (VOSU) updates the semantic prototype according to the visual representations of the samples. Ultimately, we concatenate their output as a dynamic semantic prototype, which serves as the condition of the generator. Extensive experiments demonstrate that our VADS achieves superior CZSL and GZSL performances on three prominent datasets and outperforms other state-of-the-art methods with averaging increases by 6.4\%, 5.9\% and 4.2\% on SUN, CUB and AWA2, respectively.
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024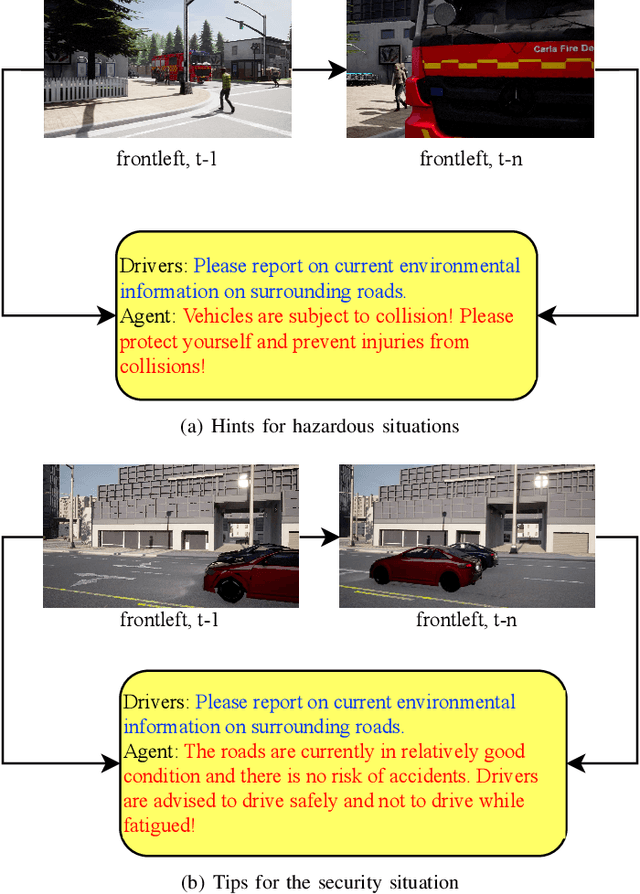
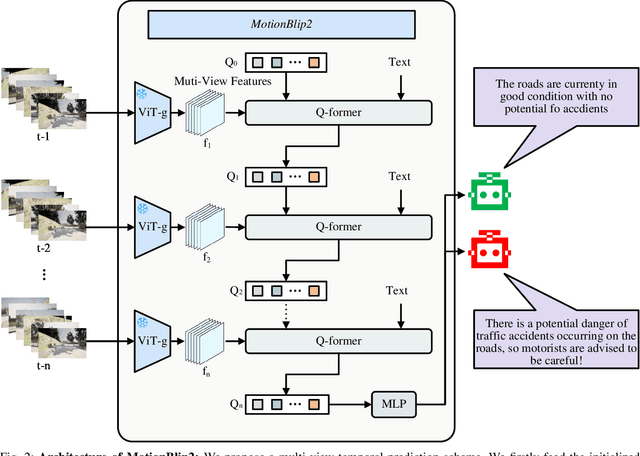
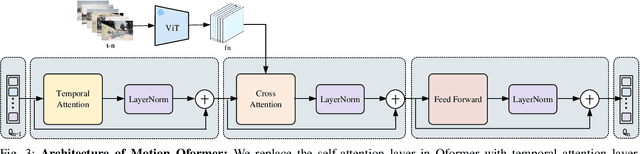
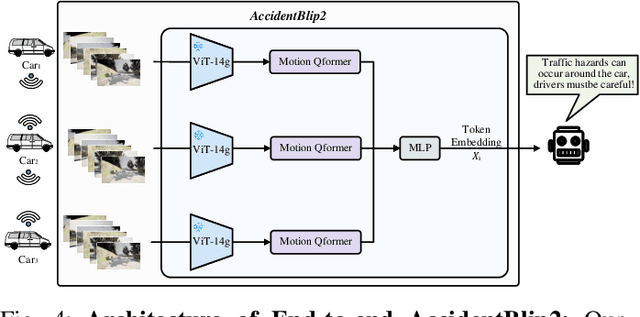
Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.
Causal Deconfounding via Confounder Disentanglement for Dual-Target Cross-Domain Recommendation
Apr 17, 2024In recent years, dual-target Cross-Domain Recommendation (CDR) has been proposed to capture comprehensive user preferences in order to ultimately enhance the recommendation accuracy in both data-richer and data-sparser domains simultaneously. However, in addition to users' true preferences, the user-item interactions might also be affected by confounders (e.g., free shipping, sales promotion). As a result, dual-target CDR has to meet two challenges: (1) how to effectively decouple observed confounders, including single-domain confounders and cross-domain confounders, and (2) how to preserve the positive effects of observed confounders on predicted interactions, while eliminating their negative effects on capturing comprehensive user preferences. To address the above two challenges, we propose a Causal Deconfounding framework via Confounder Disentanglement for dual-target Cross-Domain Recommendation, called CD2CDR. In CD2CDR, we first propose a confounder disentanglement module to effectively decouple observed single-domain and cross-domain confounders. We then propose a causal deconfounding module to preserve the positive effects of such observed confounders and eliminate their negative effects via backdoor adjustment, thereby enhancing the recommendation accuracy in each domain. Extensive experiments conducted on five real-world datasets demonstrate that CD2CDR significantly outperforms the state-of-the-art methods.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.