 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Flexible Interactive Reflection Removal with Human Guidance
Jun 03, 2024Single image reflection removal is inherently ambiguous, as both the reflection and transmission components requiring separation may follow natural image statistics. Existing methods attempt to address the issue by using various types of low-level and physics-based cues as sources of reflection signals. However, these cues are not universally applicable, since they are only observable in specific capture scenarios. This leads to a significant performance drop when test images do not align with their assumptions. In this paper, we aim to explore a novel flexible interactive reflection removal approach that leverages various forms of sparse human guidance, such as points and bounding boxes, as auxiliary high-level prior to achieve robust reflection removal. However, incorporating the raw user guidance naively into the existing reflection removal network does not result in performance gains. To this end, we innovatively transform raw user input into a unified form -- reflection masks using an Interactive Segmentation Foundation Model. Such a design absorbs the quintessence of the foundational segmentation model and flexible human guidance, thereby mitigating the challenges of reflection separations. Furthermore, to fully utilize user guidance and reduce user annotation costs, we design a mask-guided reflection removal network, comprising our proposed self-adaptive prompt block. This block adaptively incorporates user guidance as anchors and refines transmission features via cross-attention mechanisms. Extensive results on real-world images validate that our method demonstrates state-of-the-art performance on various datasets with the help of flexible and sparse user guidance. Our code and dataset will be publicly available here https://github.com/ShawnChenn/FlexibleReflectionRemoval.
Learning Object-Centric Representation via Reverse Hierarchy Guidance
May 17, 2024Object-Centric Learning (OCL) seeks to enable Neural Networks to identify individual objects in visual scenes, which is crucial for interpretable visual comprehension and reasoning. Most existing OCL models adopt auto-encoding structures and learn to decompose visual scenes through specially designed inductive bias, which causes the model to miss small objects during reconstruction. Reverse hierarchy theory proposes that human vision corrects perception errors through a top-down visual pathway that returns to bottom-level neurons and acquires more detailed information, inspired by which we propose Reverse Hierarchy Guided Network (RHGNet) that introduces a top-down pathway that works in different ways in the training and inference processes. This pathway allows for guiding bottom-level features with top-level object representations during training, as well as encompassing information from bottom-level features into perception during inference. Our model achieves SOTA performance on several commonly used datasets including CLEVR, CLEVRTex and MOVi-C. We demonstrate with experiments that our method promotes the discovery of small objects and also generalizes well on complex real-world scenes. Code will be available at https://anonymous.4open.science/r/RHGNet-6CEF.
VS-Assistant: Versatile Surgery Assistant on the Demand of Surgeons
May 14, 2024The surgical intervention is crucial to patient healthcare, and many studies have developed advanced algorithms to provide understanding and decision-making assistance for surgeons. Despite great progress, these algorithms are developed for a single specific task and scenario, and in practice require the manual combination of different functions, thus limiting the applicability. Thus, an intelligent and versatile surgical assistant is expected to accurately understand the surgeon's intentions and accordingly conduct the specific tasks to support the surgical process. In this work, by leveraging advanced multimodal large language models (MLLMs), we propose a Versatile Surgery Assistant (VS-Assistant) that can accurately understand the surgeon's intention and complete a series of surgical understanding tasks, e.g., surgical scene analysis, surgical instrument detection, and segmentation on demand. Specifically, to achieve superior surgical multimodal understanding, we devise a mixture of projectors (MOP) module to align the surgical MLLM in VS-Assistant to balance the natural and surgical knowledge. Moreover, we devise a surgical Function-Calling Tuning strategy to enable the VS-Assistant to understand surgical intentions, and thus make a series of surgical function calls on demand to meet the needs of the surgeons. Extensive experiments on neurosurgery data confirm that our VS-Assistant can understand the surgeon's intention more accurately than the existing MLLM, resulting in overwhelming performance in textual analysis and visual tasks. Source code and models will be made public.
A Survey on Personalized Content Synthesis with Diffusion Models
May 09, 2024Recent advancements in generative models have significantly impacted content creation, leading to the emergence of Personalized Content Synthesis (PCS). With a small set of user-provided examples, PCS aims to customize the subject of interest to specific user-defined prompts. Over the past two years, more than 150 methods have been proposed. However, existing surveys mainly focus on text-to-image generation, with few providing up-to-date summaries on PCS. This paper offers a comprehensive survey of PCS, with a particular focus on the diffusion models. Specifically, we introduce the generic frameworks of PCS research, which can be broadly classified into optimization-based and learning-based approaches. We further categorize and analyze these methodologies, discussing their strengths, limitations, and key techniques. Additionally, we delve into specialized tasks within the field, such as personalized object generation, face synthesis, and style personalization, highlighting their unique challenges and innovations. Despite encouraging progress, we also present an analysis of the challenges such as overfitting and the trade-off between subject fidelity and text alignment. Through this detailed overview and analysis, we propose future directions to advance the development of PCS.
Enhancing Surgical Robots with Embodied Intelligence for Autonomous Ultrasound Scanning
May 01, 2024Ultrasound robots are increasingly used in medical diagnostics and early disease screening. However, current ultrasound robots lack the intelligence to understand human intentions and instructions, hindering autonomous ultrasound scanning. To solve this problem, we propose a novel Ultrasound Embodied Intelligence system that equips ultrasound robots with the large language model (LLM) and domain knowledge, thereby improving the efficiency of ultrasound robots. Specifically, we first design an ultrasound operation knowledge database to add expertise in ultrasound scanning to the LLM, enabling the LLM to perform precise motion planning. Furthermore, we devise a dynamic ultrasound scanning strategy based on a \textit{think-observe-execute} prompt engineering, allowing LLMs to dynamically adjust motion planning strategies during the scanning procedures. Extensive experiments demonstrate that our system significantly improves ultrasound scan efficiency and quality from verbal commands. This advancement in autonomous medical scanning technology contributes to non-invasive diagnostics and streamlined medical workflows.
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024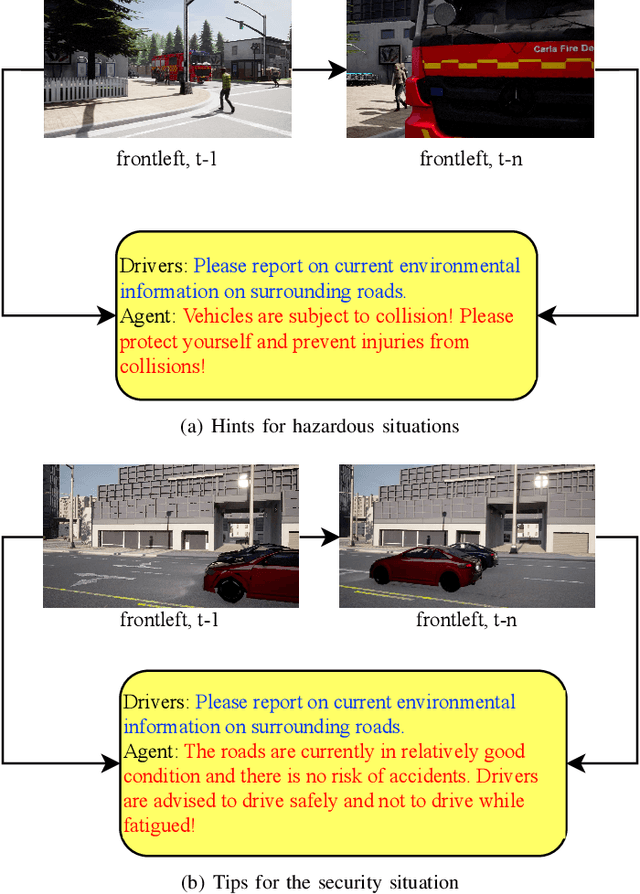
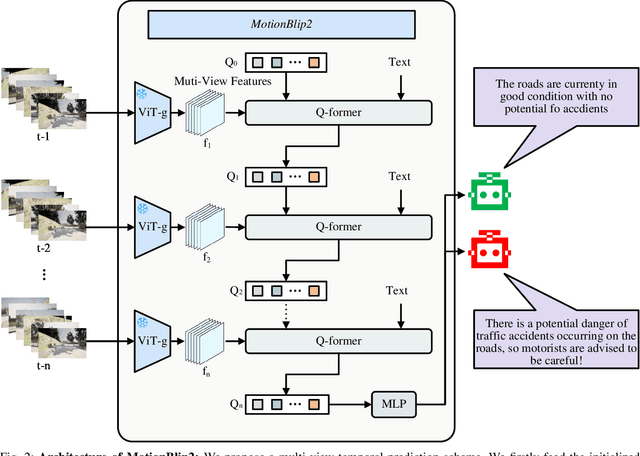
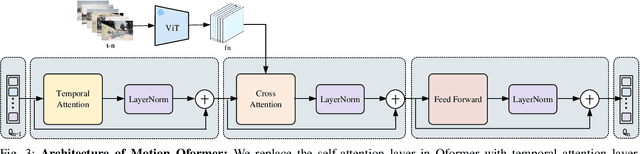
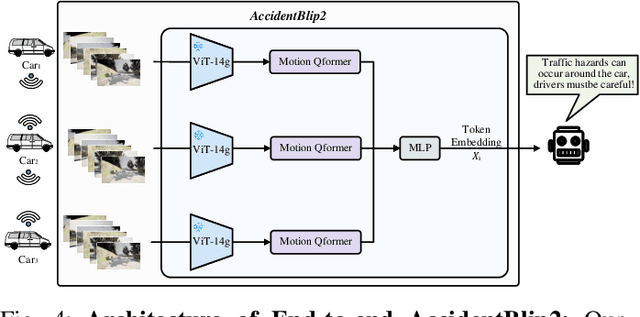
Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Solving Parametric PDEs with Radial Basis Functions and Deep Neural Networks
Apr 12, 2024We propose the POD-DNN, a novel algorithm leveraging deep neural networks (DNNs) along with radial basis functions (RBFs) in the context of the proper orthogonal decomposition (POD) reduced basis method (RBM), aimed at approximating the parametric mapping of parametric partial differential equations on irregular domains. The POD-DNN algorithm capitalizes on the low-dimensional characteristics of the solution manifold for parametric equations, alongside the inherent offline-online computational strategy of RBM and DNNs. In numerical experiments, POD-DNN demonstrates significantly accelerated computation speeds during the online phase. Compared to other algorithms that utilize RBF without integrating DNNs, POD-DNN substantially improves the computational speed in the online inference process. Furthermore, under reasonable assumptions, we have rigorously derived upper bounds on the complexity of approximating parametric mappings with POD-DNN, thereby providing a theoretical analysis of the algorithm's empirical performance.
FusionMamba: Efficient Image Fusion with State Space Model
Apr 11, 2024Image fusion aims to generate a high-resolution multi/hyper-spectral image by combining a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Current deep learning (DL)-based methods for image fusion primarily rely on CNNs or Transformers to extract features and merge different types of data. While CNNs are efficient, their receptive fields are limited, restricting their capacity to capture global context. Conversely, Transformers excel at learning global information but are hindered by their quadratic complexity. Fortunately, recent advancements in the State Space Model (SSM), particularly Mamba, offer a promising solution to this issue by enabling global awareness with linear complexity. However, there have been few attempts to explore the potential of SSM in information fusion, which is a crucial ability in domains like image fusion. Therefore, we propose FusionMamba, an innovative method for efficient image fusion. Our contributions mainly focus on two aspects. Firstly, recognizing that images from different sources possess distinct properties, we incorporate Mamba blocks into two U-shaped networks, presenting a novel architecture that extracts spatial and spectral features in an efficient, independent, and hierarchical manner. Secondly, to effectively combine spatial and spectral information, we extend the Mamba block to accommodate dual inputs. This expansion leads to the creation of a new module called the FusionMamba block, which outperforms existing fusion techniques such as concatenation and cross-attention. To validate FusionMamba's effectiveness, we conduct a series of experiments on five datasets related to three image fusion tasks. The quantitative and qualitative evaluation results demonstrate that our method achieves state-of-the-art (SOTA) performance, underscoring the superiority of FusionMamba.
Unified Physical-Digital Attack Detection Challenge
Apr 09, 2024Face Anti-Spoofing (FAS) is crucial to safeguard Face Recognition (FR) Systems. In real-world scenarios, FRs are confronted with both physical and digital attacks. However, existing algorithms often address only one type of attack at a time, which poses significant limitations in real-world scenarios where FR systems face hybrid physical-digital threats. To facilitate the research of Unified Attack Detection (UAD) algorithms, a large-scale UniAttackData dataset has been collected. UniAttackData is the largest public dataset for Unified Attack Detection, with a total of 28,706 videos, where each unique identity encompasses all advanced attack types. Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections. It attracted 136 teams for the development phase, with 13 qualifying for the final round. The results re-verified by the organizing team were used for the final ranking. This paper comprehensively reviews the challenge, detailing the dataset introduction, protocol definition, evaluation criteria, and a summary of published results. Finally, we focus on the detailed analysis of the highest-performing algorithms and offer potential directions for unified physical-digital attack detection inspired by this competition. Challenge Website: https://sites.google.com/view/face-anti-spoofing-challenge/welcome/challengecvpr2024.