 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
Mar 21, 2024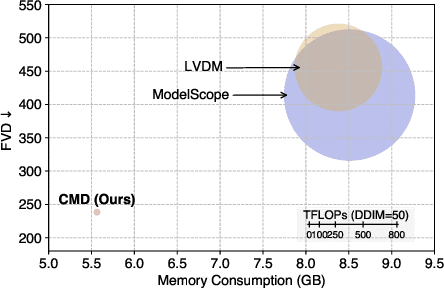
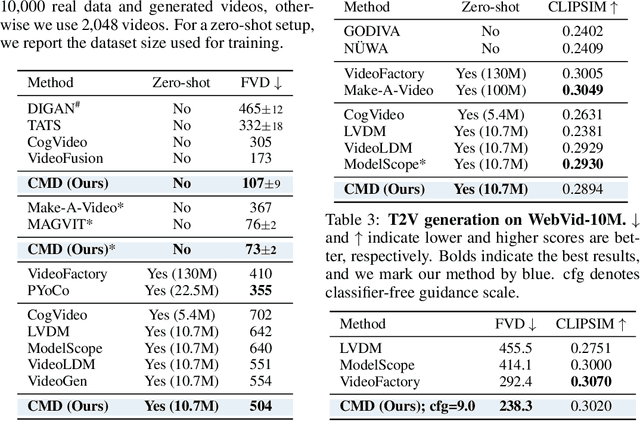
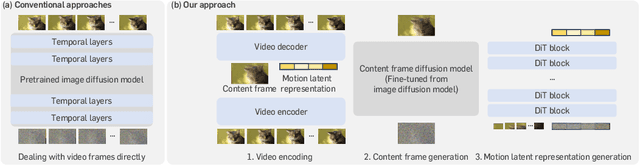
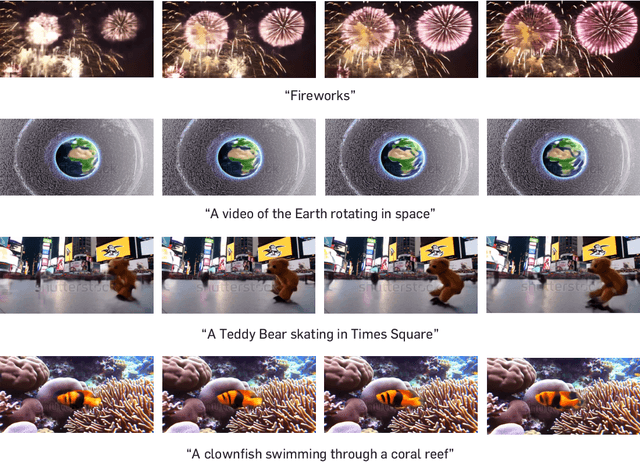
Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements. This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation. The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model. A key innovation here is the design of a compact latent space that can directly utilizes a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs. For instance, CMD can sample a video 7.7$\times$ faster than prior approaches by generating a video of 512$\times$1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
Driving Everywhere with Large Language Model Policy Adaptation
Feb 08, 2024Adapting driving behavior to new environments, customs, and laws is a long-standing problem in autonomous driving, precluding the widespread deployment of autonomous vehicles (AVs). In this paper, we present LLaDA, a simple yet powerful tool that enables human drivers and autonomous vehicles alike to drive everywhere by adapting their tasks and motion plans to traffic rules in new locations. LLaDA achieves this by leveraging the impressive zero-shot generalizability of large language models (LLMs) in interpreting the traffic rules in the local driver handbook. Through an extensive user study, we show that LLaDA's instructions are useful in disambiguating in-the-wild unexpected situations. We also demonstrate LLaDA's ability to adapt AV motion planning policies in real-world datasets; LLaDA outperforms baseline planning approaches on all our metrics. Please check our website for more details: https://boyiliee.github.io/llada.
Synthesizing Moving People with 3D Control
Jan 19, 2024In this paper, we present a diffusion model-based framework for animating people from a single image for a given target 3D motion sequence. Our approach has two core components: a) learning priors about invisible parts of the human body and clothing, and b) rendering novel body poses with proper clothing and texture. For the first part, we learn an in-filling diffusion model to hallucinate unseen parts of a person given a single image. We train this model on texture map space, which makes it more sample-efficient since it is invariant to pose and viewpoint. Second, we develop a diffusion-based rendering pipeline, which is controlled by 3D human poses. This produces realistic renderings of novel poses of the person, including clothing, hair, and plausible in-filling of unseen regions. This disentangled approach allows our method to generate a sequence of images that are faithful to the target motion in the 3D pose and, to the input image in terms of visual similarity. In addition to that, the 3D control allows various synthetic camera trajectories to render a person. Our experiments show that our method is resilient in generating prolonged motions and varied challenging and complex poses compared to prior methods. Please check our website for more details: https://boyiliee.github.io/3DHM.github.io/.
Self-correcting LLM-controlled Diffusion Models
Nov 27, 2023Text-to-image generation has witnessed significant progress with the advent of diffusion models. Despite the ability to generate photorealistic images, current text-to-image diffusion models still often struggle to accurately interpret and follow complex input text prompts. In contrast to existing models that aim to generate images only with their best effort, we introduce Self-correcting LLM-controlled Diffusion (SLD). SLD is a framework that generates an image from the input prompt, assesses its alignment with the prompt, and performs self-corrections on the inaccuracies in the generated image. Steered by an LLM controller, SLD turns text-to-image generation into an iterative closed-loop process, ensuring correctness in the resulting image. SLD is not only training-free but can also be seamlessly integrated with diffusion models behind API access, such as DALL-E 3, to further boost the performance of state-of-the-art diffusion models. Experimental results show that our approach can rectify a majority of incorrect generations, particularly in generative numeracy, attribute binding, and spatial relationships. Furthermore, by simply adjusting the instructions to the LLM, SLD can perform image editing tasks, bridging the gap between text-to-image generation and image editing pipelines. We will make our code available for future research and applications.
From Wrong To Right: A Recursive Approach Towards Vision-Language Explanation
Nov 21, 2023Addressing the challenge of adapting pre-trained vision-language models for generating insightful explanations for visual reasoning tasks with limited annotations, we present ReVisE: a $\textbf{Re}$cursive $\textbf{Vis}$ual $\textbf{E}$xplanation algorithm. Our method iteratively computes visual features (conditioned on the text input), an answer, and an explanation, to improve the explanation quality step by step until the answer converges. We find that this multi-step approach guides the model to correct its own answers and outperforms single-step explanation generation. Furthermore, explanations generated by ReVisE also serve as valuable annotations for few-shot self-training. Our approach outperforms previous methods while utilizing merely 5% of the human-annotated explanations across 10 metrics, demonstrating up to a 4.2 and 1.3 increase in BLEU-1 score on the VCR and VQA-X datasets, underscoring the efficacy and data-efficiency of our method.
EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
Nov 03, 2023We present EmerNeRF, a simple yet powerful approach for learning spatial-temporal representations of dynamic driving scenes. Grounded in neural fields, EmerNeRF simultaneously captures scene geometry, appearance, motion, and semantics via self-bootstrapping. EmerNeRF hinges upon two core components: First, it stratifies scenes into static and dynamic fields. This decomposition emerges purely from self-supervision, enabling our model to learn from general, in-the-wild data sources. Second, EmerNeRF parameterizes an induced flow field from the dynamic field and uses this flow field to further aggregate multi-frame features, amplifying the rendering precision of dynamic objects. Coupling these three fields (static, dynamic, and flow) enables EmerNeRF to represent highly-dynamic scenes self-sufficiently, without relying on ground truth object annotations or pre-trained models for dynamic object segmentation or optical flow estimation. Our method achieves state-of-the-art performance in sensor simulation, significantly outperforming previous methods when reconstructing static (+2.93 PSNR) and dynamic (+3.70 PSNR) scenes. In addition, to bolster EmerNeRF's semantic generalization, we lift 2D visual foundation model features into 4D space-time and address a general positional bias in modern Transformers, significantly boosting 3D perception performance (e.g., 37.50% relative improvement in occupancy prediction accuracy on average). Finally, we construct a diverse and challenging 120-sequence dataset to benchmark neural fields under extreme and highly-dynamic settings.
Interactive Task Planning with Language Models
Oct 16, 2023



An interactive robot framework accomplishes long-horizon task planning and can easily generalize to new goals or distinct tasks, even during execution. However, most traditional methods require predefined module design, which makes it hard to generalize to different goals. Recent large language model based approaches can allow for more open-ended planning but often require heavy prompt engineering or domain-specific pretrained models. To tackle this, we propose a simple framework that achieves interactive task planning with language models. Our system incorporates both high-level planning and low-level function execution via language. We verify the robustness of our system in generating novel high-level instructions for unseen objectives and its ease of adaptation to different tasks by merely substituting the task guidelines, without the need for additional complex prompt engineering. Furthermore, when the user sends a new request, our system is able to replan accordingly with precision based on the new request, task guidelines and previously executed steps. Please check more details on our https://wuphilipp.github.io/itp_site and https://youtu.be/TrKLuyv26_g.
LLM-grounded Video Diffusion Models
Oct 02, 2023



Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion (e.g., even lacking the ability to be prompted for objects moving from left to right). To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.