 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZAPP! Zonotope Agreement of Prediction and Planning for Continuous-Time Collision Avoidance with Discrete-Time Dynamics
Jun 03, 2024The past few years have seen immense progress on two fronts that are critical to safe, widespread mobile robot deployment: predicting uncertain motion of multiple agents, and planning robot motion under uncertainty. However, the numerical methods required on each front have resulted in a mismatch of representation for prediction and planning. In prediction, numerical tractability is usually achieved by coarsely discretizing time, and by representing multimodal multi-agent interactions as distributions with infinite support. On the other hand, safe planning typically requires very fine time discretization, paired with distributions with compact support, to reduce conservativeness and ensure numerical tractability. The result is, when existing predictors are coupled with planning and control, one may often find unsafe motion plans. This paper proposes ZAPP (Zonotope Agreement of Prediction and Planning) to resolve the representation mismatch. ZAPP unites a prediction-friendly coarse time discretization and a planning-friendly zonotope uncertainty representation; the method also enables differentiating through a zonotope collision check, allowing one to integrate prediction and planning within a gradient-based optimization framework. Numerical examples show how ZAPP can produce safer trajectories compared to baselines in interactive scenes.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
Closing the Loop on Runtime Monitors with Fallback-Safe MPC
Sep 18, 2023When we rely on deep-learned models for robotic perception, we must recognize that these models may behave unreliably on inputs dissimilar from the training data, compromising the closed-loop system's safety. This raises fundamental questions on how we can assess confidence in perception systems and to what extent we can take safety-preserving actions when external environmental changes degrade our perception model's performance. Therefore, we present a framework to certify the safety of a perception-enabled system deployed in novel contexts. To do so, we leverage robust model predictive control (MPC) to control the system using the perception estimates while maintaining the feasibility of a safety-preserving fallback plan that does not rely on the perception system. In addition, we calibrate a runtime monitor using recently proposed conformal prediction techniques to certifiably detect when the perception system degrades beyond the tolerance of the MPC controller, resulting in an end-to-end safety assurance. We show that this control framework and calibration technique allows us to certify the system's safety with orders of magnitudes fewer samples than required to retrain the perception network when we deploy in a novel context on a photo-realistic aircraft taxiing simulator. Furthermore, we illustrate the safety-preserving behavior of the MPC on simulated examples of a quadrotor. We open-source our simulation platform and provide videos of our results at our project page: https://tinyurl.com/fallback-safe-mpc.
Refining Obstacle Perception Safety Zones via Maneuver-Based Decomposition
Aug 11, 2023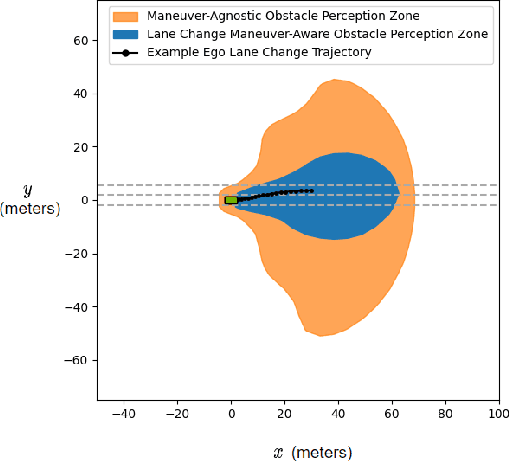
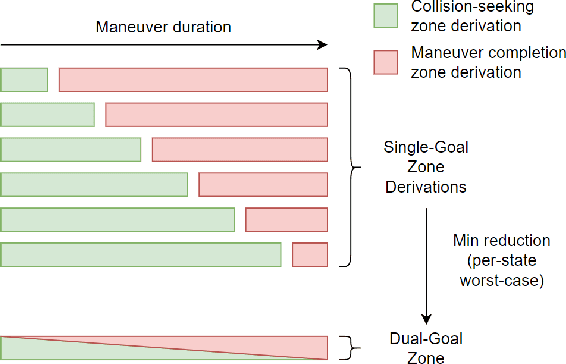
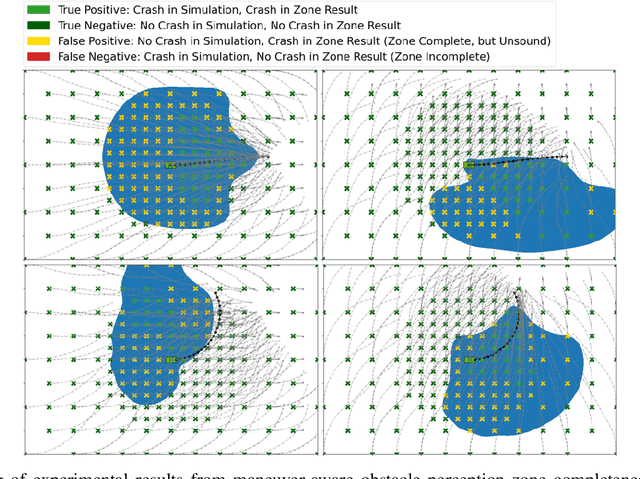
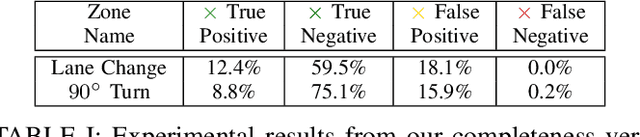
A critical task for developing safe autonomous driving stacks is to determine whether an obstacle is safety-critical, i.e., poses an imminent threat to the autonomous vehicle. Our previous work showed that Hamilton Jacobi reachability theory can be applied to compute interaction-dynamics-aware perception safety zones that better inform an ego vehicle's perception module which obstacles are considered safety-critical. For completeness, these zones are typically larger than absolutely necessary, forcing the perception module to pay attention to a larger collection of objects for the sake of conservatism. As an improvement, we propose a maneuver-based decomposition of our safety zones that leverages information about the ego maneuver to reduce the zone volume. In particular, we propose a "temporal convolution" operation that produces safety zones for specific ego maneuvers, thus limiting the ego's behavior to reduce the size of the safety zones. We show with numerical experiments that maneuver-based zones are significantly smaller (up to 76% size reduction) than the baseline while maintaining completeness.
Semantic Anomaly Detection with Large Language Models
May 18, 2023



As robots acquire increasingly sophisticated skills and see increasingly complex and varied environments, the threat of an edge case or anomalous failure is ever present. For example, Tesla cars have seen interesting failure modes ranging from autopilot disengagements due to inactive traffic lights carried by trucks to phantom braking caused by images of stop signs on roadside billboards. These system-level failures are not due to failures of any individual component of the autonomy stack but rather system-level deficiencies in semantic reasoning. Such edge cases, which we call \textit{semantic anomalies}, are simple for a human to disentangle yet require insightful reasoning. To this end, we study the application of large language models (LLMs), endowed with broad contextual understanding and reasoning capabilities, to recognize these edge semantic cases. We introduce a monitoring framework for semantic anomaly detection in vision-based policies to do so. Our experiments evaluate this framework in monitoring a learned policy for object manipulation and a finite state machine policy for autonomous driving and demonstrate that an LLM-based monitor can serve as a proxy for human reasoning. Finally, we provide an extended discussion on the strengths and weaknesses of this approach and motivate a research outlook on how we can further use foundation models for semantic anomaly detection.
A System-Level View on Out-of-Distribution Data in Robotics
Dec 28, 2022

When testing conditions differ from those represented in training data, so-called out-of-distribution (OOD) inputs can mar the reliability of black-box learned components in the modern robot autonomy stack. Therefore, coping with OOD data is an important challenge on the path towards trustworthy learning-enabled open-world autonomy. In this paper, we aim to demystify the topic of OOD data and its associated challenges in the context of data-driven robotic systems, drawing connections to emerging paradigms in the ML community that study the effect of OOD data on learned models in isolation. We argue that as roboticists, we should reason about the overall system-level competence of a robot as it performs tasks in OOD conditions. We highlight key research questions around this system-level view of OOD problems to guide future research toward safe and reliable learning-enabled autonomy.
Online Distribution Shift Detection via Recency Prediction
Nov 17, 2022



When deploying modern machine learning-enabled robotic systems in high-stakes applications, detecting distribution shift is critical. However, most existing methods for detecting distribution shift are not well-suited to robotics settings, where data often arrives in a streaming fashion and may be very high-dimensional. In this work, we present an online method for detecting distribution shift with guarantees on the false positive rate - i.e., when there is no distribution shift, our system is very unlikely (with probability $< \epsilon$) to falsely issue an alert; any alerts that are issued should therefore be heeded. Our method is specifically designed for efficient detection even with high dimensional data, and it empirically achieves up to 11x faster detection on realistic robotics settings compared to prior work while maintaining a low false negative rate in practice (whenever there is a distribution shift in our experiments, our method indeed emits an alert).
Learning Autonomous Vehicle Safety Concepts from Demonstrations
Oct 06, 2022



Evaluating the safety of an autonomous vehicle (AV) depends on the behavior of surrounding agents which can be heavily influenced by factors such as environmental context and informally-defined driving etiquette. A key challenge is in determining a minimum set of assumptions on what constitutes reasonable foreseeable behaviors of other road users for the development of AV safety models and techniques. In this paper, we propose a data-driven AV safety design methodology that first learns ``reasonable'' behavioral assumptions from data, and then synthesizes an AV safety concept using these learned behavioral assumptions. We borrow techniques from control theory, namely high order control barrier functions and Hamilton-Jacobi reachability, to provide inductive bias to aid interpretability, verifiability, and tractability of our approach. In our experiments, we learn an AV safety concept using demonstrations collected from a highway traffic-weaving scenario, compare our learned concept to existing baselines, and showcase its efficacy in evaluating real-world driving logs.
Data Lifecycle Management in Evolving Input Distributions for Learning-based Aerospace Applications
Sep 24, 2022



As input distributions evolve over a mission lifetime, maintaining performance of learning-based models becomes challenging. This paper presents a framework to incrementally retrain a model by selecting a subset of test inputs to label, which allows the model to adapt to changing input distributions. Algorithms within this framework are evaluated based on (1) model performance throughout mission lifetime and (2) cumulative costs associated with labeling and model retraining. We provide an open-source benchmark of a satellite pose estimation model trained on images of a satellite in space and deployed in novel scenarios (e.g., different backgrounds or misbehaving pixels), where algorithms are evaluated on their ability to maintain high performance by retraining on a subset of inputs. We also propose a novel algorithm to select a diverse subset of inputs for labeling, by characterizing the information gain from an input using Bayesian uncertainty quantification and choosing a subset that maximizes collective information gain using concepts from batch active learning. We show that our algorithm outperforms others on the benchmark, e.g., achieves comparable performance to an algorithm that labels 100% of inputs, while only labeling 50% of inputs, resulting in low costs and high performance over the mission lifetime.
Motion Planning for a Climbing Robot with Stochastic Grasps
Sep 21, 2022



Motion planning for a multi-limbed climbing robot must consider the robot's posture, joint torques, and how it uses contact forces to interact with its environment. This paper focuses on motion planning for a robot that uses nontraditional locomotion to explore unpredictable environments such as martian caves. Our robotic concept, ReachBot, uses extendable and retractable booms as limbs to achieve a large reachable workspace while climbing. Each extendable boom is capped by a microspine gripper designed for grasping rocky surfaces. ReachBot leverages its large workspace to navigate around obstacles, over crevasses, and through challenging terrain. Our planning approach must be versatile to accommodate variable terrain features and robust to mitigate risks from the stochastic nature of grasping with spines. In this paper, we introduce a graph traversal algorithm to select a discrete sequence of grasps based on available terrain features suitable for grasping. This discrete plan is complemented by a decoupled motion planner that considers the alternating phases of body movement and end-effector movement, using a combination of sampling-based planning and sequential convex programming to optimize individual phases. We use our motion planner to plan a trajectory across a simulated 2D cave environment with at least 95% probability of success and demonstrate improved robustness over a baseline trajectory. Finally, we verify our motion planning algorithm through experimentation on a 2D planar prototype.