 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZAPP! Zonotope Agreement of Prediction and Planning for Continuous-Time Collision Avoidance with Discrete-Time Dynamics
Jun 03, 2024The past few years have seen immense progress on two fronts that are critical to safe, widespread mobile robot deployment: predicting uncertain motion of multiple agents, and planning robot motion under uncertainty. However, the numerical methods required on each front have resulted in a mismatch of representation for prediction and planning. In prediction, numerical tractability is usually achieved by coarsely discretizing time, and by representing multimodal multi-agent interactions as distributions with infinite support. On the other hand, safe planning typically requires very fine time discretization, paired with distributions with compact support, to reduce conservativeness and ensure numerical tractability. The result is, when existing predictors are coupled with planning and control, one may often find unsafe motion plans. This paper proposes ZAPP (Zonotope Agreement of Prediction and Planning) to resolve the representation mismatch. ZAPP unites a prediction-friendly coarse time discretization and a planning-friendly zonotope uncertainty representation; the method also enables differentiating through a zonotope collision check, allowing one to integrate prediction and planning within a gradient-based optimization framework. Numerical examples show how ZAPP can produce safer trajectories compared to baselines in interactive scenes.
Memorize What Matters: Emergent Scene Decomposition from Multitraverse
May 29, 2024Humans naturally retain memories of permanent elements, while ephemeral moments often slip through the cracks of memory. This selective retention is crucial for robotic perception, localization, and mapping. To endow robots with this capability, we introduce 3D Gaussian Mapping (3DGM), a self-supervised, camera-only offline mapping framework grounded in 3D Gaussian Splatting. 3DGM converts multitraverse RGB videos from the same region into a Gaussian-based environmental map while concurrently performing 2D ephemeral object segmentation. Our key observation is that the environment remains consistent across traversals, while objects frequently change. This allows us to exploit self-supervision from repeated traversals to achieve environment-object decomposition. More specifically, 3DGM formulates multitraverse environmental mapping as a robust differentiable rendering problem, treating pixels of the environment and objects as inliers and outliers, respectively. Using robust feature distillation, feature residuals mining, and robust optimization, 3DGM jointly performs 2D segmentation and 3D mapping without human intervention. We build the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets, to evaluate our method in unsupervised 2D segmentation, 3D reconstruction, and neural rendering. Extensive results verify the effectiveness and potential of our method for self-driving and robotics.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
ReachBot Field Tests in a Mojave Desert Lava Tube as a Martian Analog
May 23, 2024ReachBot is a robot concept for the planetary exploration of caves and lava tubes, which are often inaccessible with traditional robot locomotion methods. It uses extendable booms as appendages, with grippers mounted at the end, to grasp irregular rock surfaces and traverse these difficult terrains. We have built a partial ReachBot prototype consisting of a single boom and gripper, mounted on a tripod. We present the details on the design and field test of this partial ReachBot prototype in a lava tube in the Mojave Desert. The technical requirements of the field testing, implementation details, and grasp performance results are discussed. The planning and preparation of the field test and lessons learned are also given.
RuleFuser: Injecting Rules in Evidential Networks for Robust Out-of-Distribution Trajectory Prediction
May 18, 2024Modern neural trajectory predictors in autonomous driving are developed using imitation learning (IL) from driving logs. Although IL benefits from its ability to glean nuanced and multi-modal human driving behaviors from large datasets, the resulting predictors often struggle with out-of-distribution (OOD) scenarios and with traffic rule compliance. On the other hand, classical rule-based predictors, by design, can predict traffic rule satisfying behaviors while being robust to OOD scenarios, but these predictors fail to capture nuances in agent-to-agent interactions and human driver's intent. In this paper, we present RuleFuser, a posterior-net inspired evidential framework that combines neural predictors with classical rule-based predictors to draw on the complementary benefits of both, thereby striking a balance between performance and traffic rule compliance. The efficacy of our approach is demonstrated on the real-world nuPlan dataset where RuleFuser leverages the higher performance of the neural predictor in in-distribution (ID) scenarios and the higher safety offered by the rule-based predictor in OOD scenarios.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Apr 08, 2024In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms -- PPO, SAC, and DDPG -- dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym -- Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick -- by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results show that PBRL agents achieve superior performance, in terms of cumulative reward, compared to non-evolutionary baseline agents. The trained agents are finally deployed in the real world for a Franka Nut Pick task, demonstrating successful sim-to-real transfer. Code and videos of the learned policies are available on our project website.
Perfecting Periodic Trajectory Tracking: Model Predictive Control with a Periodic Observer ($Π$-MPC)
Apr 02, 2024In Model Predictive Control (MPC), discrepancies between the actual system and the predictive model can lead to substantial tracking errors and significantly degrade performance and reliability. While such discrepancies can be alleviated with more complex models, this often complicates controller design and implementation. By leveraging the fact that many trajectories of interest are periodic, we show that perfect tracking is possible when incorporating a simple observer that estimates and compensates for periodic disturbances. We present the design of the observer and the accompanying tracking MPC scheme, proving that their combination achieves zero tracking error asymptotically, regardless of the complexity of the unmodelled dynamics. We validate the effectiveness of our method, demonstrating asymptotically perfect tracking on a high-dimensional soft robot with nearly 10,000 states and a fivefold reduction in tracking errors compared to a baseline MPC on small-scale autonomous race car experiments.
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Mar 29, 2024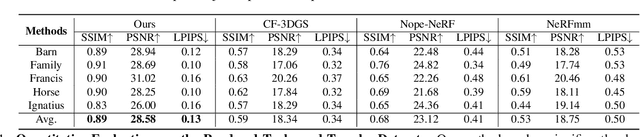
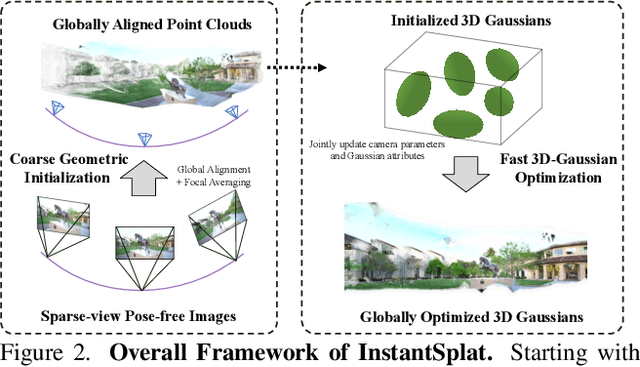
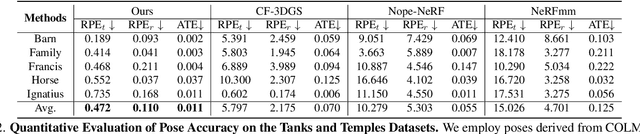

While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
Producing and Leveraging Online Map Uncertainty in Trajectory Prediction
Mar 25, 2024High-definition (HD) maps have played an integral role in the development of modern autonomous vehicle (AV) stacks, albeit with high associated labeling and maintenance costs. As a result, many recent works have proposed methods for estimating HD maps online from sensor data, enabling AVs to operate outside of previously-mapped regions. However, current online map estimation approaches are developed in isolation of their downstream tasks, complicating their integration in AV stacks. In particular, they do not produce uncertainty or confidence estimates. In this work, we extend multiple state-of-the-art online map estimation methods to additionally estimate uncertainty and show how this enables more tightly integrating online mapping with trajectory forecasting. In doing so, we find that incorporating uncertainty yields up to 50% faster training convergence and up to 15% better prediction performance on the real-world nuScenes driving dataset.