 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHawk: Learning to Understand Open-World Video Anomalies
May 27, 2024Video Anomaly Detection (VAD) systems can autonomously monitor and identify disturbances, reducing the need for manual labor and associated costs. However, current VAD systems are often limited by their superficial semantic understanding of scenes and minimal user interaction. Additionally, the prevalent data scarcity in existing datasets restricts their applicability in open-world scenarios. In this paper, we introduce Hawk, a novel framework that leverages interactive large Visual Language Models (VLM) to interpret video anomalies precisely. Recognizing the difference in motion information between abnormal and normal videos, Hawk explicitly integrates motion modality to enhance anomaly identification. To reinforce motion attention, we construct an auxiliary consistency loss within the motion and video space, guiding the video branch to focus on the motion modality. Moreover, to improve the interpretation of motion-to-language, we establish a clear supervisory relationship between motion and its linguistic representation. Furthermore, we have annotated over 8,000 anomaly videos with language descriptions, enabling effective training across diverse open-world scenarios, and also created 8,000 question-answering pairs for users' open-world questions. The final results demonstrate that Hawk achieves SOTA performance, surpassing existing baselines in both video description generation and question-answering. Our codes/dataset/demo will be released at https://github.com/jqtangust/hawk.
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
May 27, 2024Due to the need to interact with the real world, embodied agents are required to possess comprehensive prior knowledge, long-horizon planning capability, and a swift response speed. Despite recent large language model (LLM) based agents achieving promising performance, they still exhibit several limitations. For instance, the output of LLMs is a descriptive sentence, which is ambiguous when determining specific actions. To address these limitations, we introduce the large auto-regressive model (LARM). LARM leverages both text and multi-view images as input and predicts subsequent actions in an auto-regressive manner. To train LARM, we develop a novel data format named auto-regressive node transmission structure and assemble a corresponding dataset. Adopting a two-phase training regimen, LARM successfully harvests enchanted equipment in Minecraft, which demands significantly more complex decision-making chains than the highest achievements of prior best methods. Besides, the speed of LARM is 6.8x faster.
Low-Light Video Enhancement via Spatial-Temporal Consistent Illumination and Reflection Decomposition
May 24, 2024Low-Light Video Enhancement (LLVE) seeks to restore dynamic and static scenes plagued by severe invisibility and noise. One critical aspect is formulating a consistency constraint specifically for temporal-spatial illumination and appearance enhanced versions, a dimension overlooked in existing methods. In this paper, we present an innovative video Retinex-based decomposition strategy that operates without the need for explicit supervision to delineate illumination and reflectance components. We leverage dynamic cross-frame correspondences for intrinsic appearance and enforce a scene-level continuity constraint on the illumination field to yield satisfactory consistent decomposition results. To further ensure consistent decomposition, we introduce a dual-structure enhancement network featuring a novel cross-frame interaction mechanism. This mechanism can seamlessly integrate with encoder-decoder single-frame networks, incurring minimal additional parameter costs. By supervising different frames simultaneously, this network encourages them to exhibit matching decomposition features, thus achieving the desired temporal propagation. Extensive experiments are conducted on widely recognized LLVE benchmarks, covering diverse scenarios. Our framework consistently outperforms existing methods, establishing a new state-of-the-art (SOTA) performance.
Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
May 24, 2024The development of AI-Generated Content (AIGC) has empowered the creation of remarkably realistic AI-generated videos, such as those involving Sora. However, the widespread adoption of these models raises concerns regarding potential misuse, including face video scams and copyright disputes. Addressing these concerns requires the development of robust tools capable of accurately determining video authenticity. The main challenges lie in the dataset and neural classifier for training. Current datasets lack a varied and comprehensive repository of real and generated content for effective discrimination. In this paper, we first introduce an extensive video dataset designed specifically for AI-Generated Video Detection (GenVidDet). It includes over 2.66 M instances of both real and generated videos, varying in categories, frames per second, resolutions, and lengths. The comprehensiveness of GenVidDet enables the training of a generalizable video detector. We also present the Dual-Branch 3D Transformer (DuB3D), an innovative and effective method for distinguishing between real and generated videos, enhanced by incorporating motion information alongside visual appearance. DuB3D utilizes a dual-branch architecture that adaptively leverages and fuses raw spatio-temporal data and optical flow. We systematically explore the critical factors affecting detection performance, achieving the optimal configuration for DuB3D. Trained on GenVidDet, DuB3D can distinguish between real and generated video content with 96.77% accuracy, and strong generalization capability even for unseen types.
CG-FedLLM: How to Compress Gradients in Federated Fune-tuning for Large Language Models
May 22, 2024The success of current Large-Language Models (LLMs) hinges on extensive training data that is collected and stored centrally, called Centralized Learning (CL). However, such a collection manner poses a privacy threat, and one potential solution is Federated Learning (FL), which transfers gradients, not raw data, among clients. Unlike traditional networks, FL for LLMs incurs significant communication costs due to their tremendous parameters. This study introduces an innovative approach to compress gradients to improve communication efficiency during LLM FL, formulating the new FL pipeline named CG-FedLLM. This approach integrates an encoder on the client side to acquire the compressed gradient features and a decoder on the server side to reconstruct the gradients. We also developed a novel training strategy that comprises Temporal-ensemble Gradient-Aware Pre-training (TGAP) to identify characteristic gradients of the target model and Federated AutoEncoder-Involved Fine-tuning (FAF) to compress gradients adaptively. Extensive experiments confirm that our approach reduces communication costs and improves performance (e.g., average 3 points increment compared with traditional CL- and FL-based fine-tuning with LlaMA on a well-recognized benchmark, C-Eval). This improvement is because our encoder-decoder, trained via TGAP and FAF, can filter gradients while selectively preserving critical features. Furthermore, we present a series of experimental analyses focusing on the signal-to-noise ratio, compression rate, and robustness within this privacy-centric framework, providing insight into developing more efficient and secure LLMs.
Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Apr 22, 2024Recently, diffusion-based purification (DBP) has emerged as a promising approach for defending against adversarial attacks. However, previous studies have used questionable methods to evaluate the robustness of DBP models, their explanations of DBP robustness also lack experimental support. We re-examine DBP robustness using precise gradient, and discuss the impact of stochasticity on DBP robustness. To better explain DBP robustness, we assess DBP robustness under a novel attack setting, Deterministic White-box, and pinpoint stochasticity as the main factor in DBP robustness. Our results suggest that DBP models rely on stochasticity to evade the most effective attack direction, rather than directly countering adversarial perturbations. To improve the robustness of DBP models, we propose Adversarial Denoising Diffusion Training (ADDT). This technique uses Classifier-Guided Perturbation Optimization (CGPO) to generate adversarial perturbation through guidance from a pre-trained classifier, and uses Rank-Based Gaussian Mapping (RBGM) to convert adversarial pertubation into a normal Gaussian distribution. Empirical results show that ADDT improves the robustness of DBP models. Further experiments confirm that ADDT equips DBP models with the ability to directly counter adversarial perturbations.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024



This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Boosting Image Restoration via Priors from Pre-trained Models
Mar 19, 2024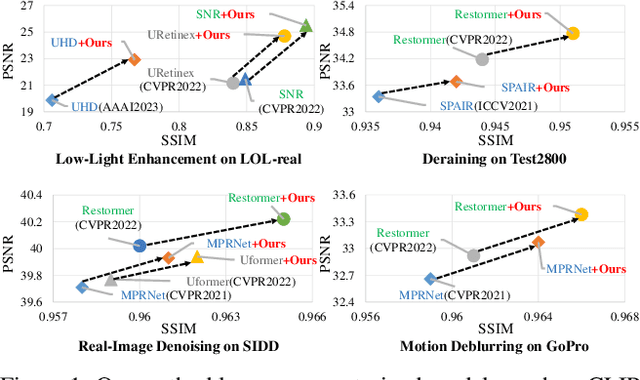

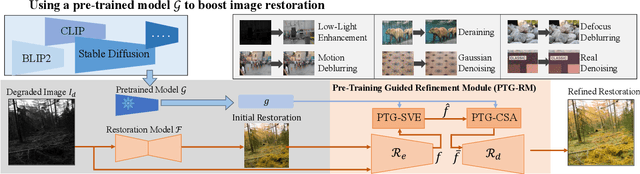
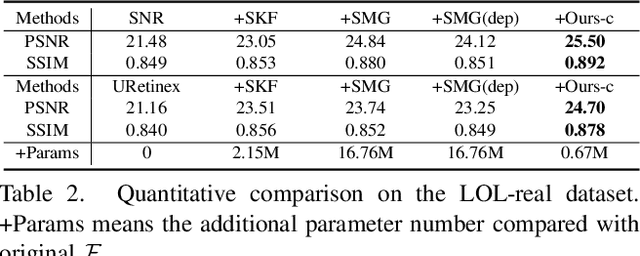
Pre-trained models with large-scale training data, such as CLIP and Stable Diffusion, have demonstrated remarkable performance in various high-level computer vision tasks such as image understanding and generation from language descriptions. Yet, their potential for low-level tasks such as image restoration remains relatively unexplored. In this paper, we explore such models to enhance image restoration. As off-the-shelf features (OSF) from pre-trained models do not directly serve image restoration, we propose to learn an additional lightweight module called Pre-Train-Guided Refinement Module (PTG-RM) to refine restoration results of a target restoration network with OSF. PTG-RM consists of two components, Pre-Train-Guided Spatial-Varying Enhancement (PTG-SVE), and Pre-Train-Guided Channel-Spatial Attention (PTG-CSA). PTG-SVE enables optimal short- and long-range neural operations, while PTG-CSA enhances spatial-channel attention for restoration-related learning. Extensive experiments demonstrate that PTG-RM, with its compact size ($<$1M parameters), effectively enhances restoration performance of various models across different tasks, including low-light enhancement, deraining, deblurring, and denoising.
Learning to Remove Wrinkled Transparent Film with Polarized Prior
Mar 07, 2024
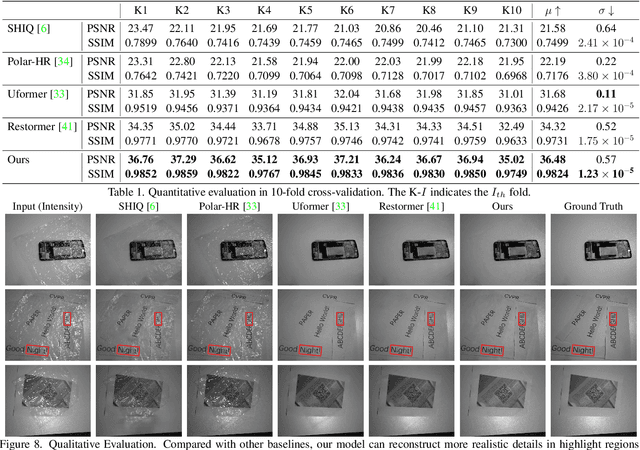
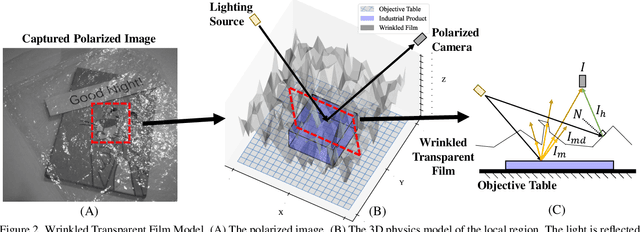
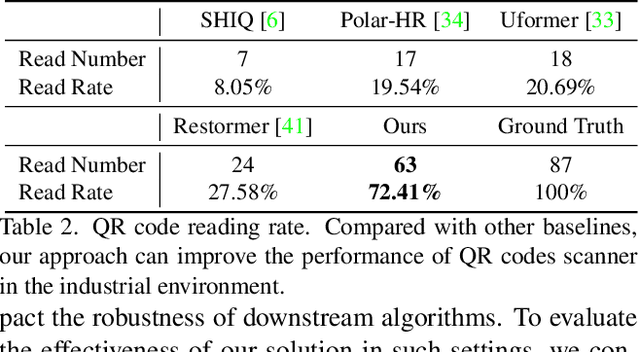
In this paper, we study a new problem, Film Removal (FR), which attempts to remove the interference of wrinkled transparent films and reconstruct the original information under films for industrial recognition systems. We first physically model the imaging of industrial materials covered by the film. Considering the specular highlight from the film can be effectively recorded by the polarized camera, we build a practical dataset with polarization information containing paired data with and without transparent film. We aim to remove interference from the film (specular highlights and other degradations) with an end-to-end framework. To locate the specular highlight, we use an angle estimation network to optimize the polarization angle with the minimized specular highlight. The image with minimized specular highlight is set as a prior for supporting the reconstruction network. Based on the prior and the polarized images, the reconstruction network can decouple all degradations from the film. Extensive experiments show that our framework achieves SOTA performance in both image reconstruction and industrial downstream tasks. Our code will be released at \url{https://github.com/jqtangust/FilmRemoval}.