 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructing Prompt-to-Prompt Generation for Zero-Shot Learning
Jun 05, 2024Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a \textbf{P}rompt-to-\textbf{P}rompt generation methodology (\textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Jun 02, 2024Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy
Mar 21, 2024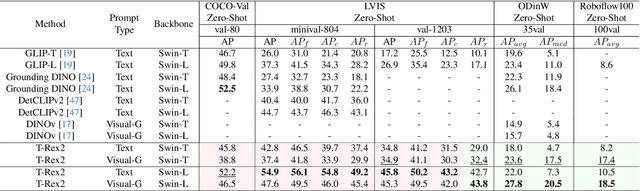

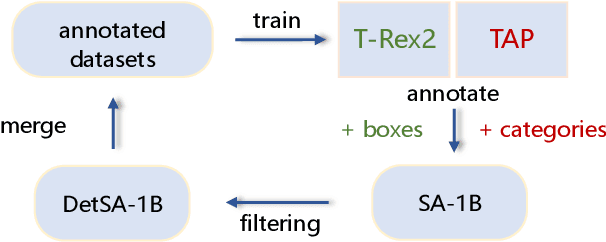

We present T-Rex2, a highly practical model for open-set object detection. Previous open-set object detection methods relying on text prompts effectively encapsulate the abstract concept of common objects, but struggle with rare or complex object representation due to data scarcity and descriptive limitations. Conversely, visual prompts excel in depicting novel objects through concrete visual examples, but fall short in conveying the abstract concept of objects as effectively as text prompts. Recognizing the complementary strengths and weaknesses of both text and visual prompts, we introduce T-Rex2 that synergizes both prompts within a single model through contrastive learning. T-Rex2 accepts inputs in diverse formats, including text prompts, visual prompts, and the combination of both, so that it can handle different scenarios by switching between the two prompt modalities. Comprehensive experiments demonstrate that T-Rex2 exhibits remarkable zero-shot object detection capabilities across a wide spectrum of scenarios. We show that text prompts and visual prompts can benefit from each other within the synergy, which is essential to cover massive and complicated real-world scenarios and pave the way towards generic object detection. Model API is now available at \url{https://github.com/IDEA-Research/T-Rex}.
TAPTR: Tracking Any Point with Transformers as Detection
Mar 19, 2024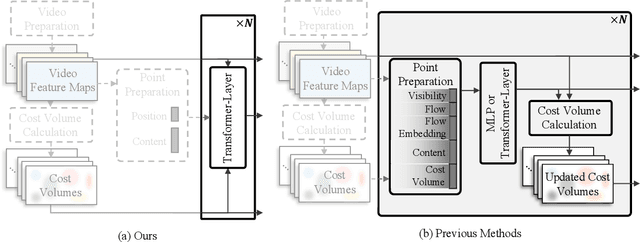
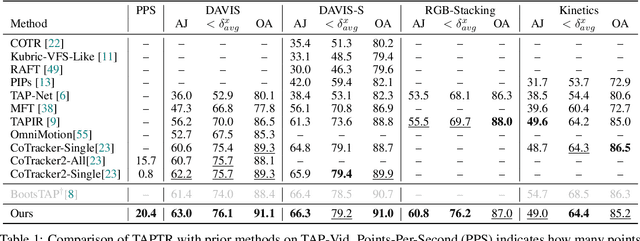
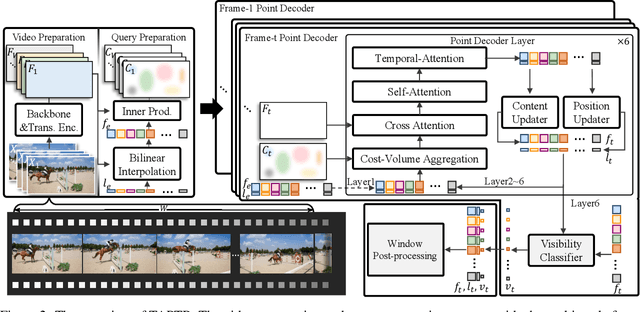

In this paper, we propose a simple and strong framework for Tracking Any Point with TRansformers (TAPTR). Based on the observation that point tracking bears a great resemblance to object detection and tracking, we borrow designs from DETR-like algorithms to address the task of TAP. In the proposed framework, in each video frame, each tracking point is represented as a point query, which consists of a positional part and a content part. As in DETR, each query (its position and content feature) is naturally updated layer by layer. Its visibility is predicted by its updated content feature. Queries belonging to the same tracking point can exchange information through self-attention along the temporal dimension. As all such operations are well-designed in DETR-like algorithms, the model is conceptually very simple. We also adopt some useful designs such as cost volume from optical flow models and develop simple designs to provide long temporal information while mitigating the feature drifting issue. Our framework demonstrates strong performance with state-of-the-art performance on various TAP datasets with faster inference speed.
BlindDiff: Empowering Degradation Modelling in Diffusion Models for Blind Image Super-Resolution
Mar 15, 2024



Diffusion models (DM) have achieved remarkable promise in image super-resolution (SR). However, most of them are tailored to solving non-blind inverse problems with fixed known degradation settings, limiting their adaptability to real-world applications that involve complex unknown degradations. In this work, we propose BlindDiff, a DM-based blind SR method to tackle the blind degradation settings in SISR. BlindDiff seamlessly integrates the MAP-based optimization into DMs, which constructs a joint distribution of the low-resolution (LR) observation, high-resolution (HR) data, and degradation kernels for the data and kernel priors, and solves the blind SR problem by unfolding MAP approach along with the reverse process. Unlike most DMs, BlindDiff firstly presents a modulated conditional transformer (MCFormer) that is pre-trained with noise and kernel constraints, further serving as a posterior sampler to provide both priors simultaneously. Then, we plug a simple yet effective kernel-aware gradient term between adjacent sampling iterations that guides the diffusion model to learn degradation consistency knowledge. This also enables to joint refine the degradation model as well as HR images by observing the previous denoised sample. With the MAP-based reverse diffusion process, we show that BlindDiff advocates alternate optimization for blur kernel estimation and HR image restoration in a mutual reinforcing manner. Experiments on both synthetic and real-world datasets show that BlindDiff achieves the state-of-the-art performance with significant model complexity reduction compared to recent DM-based methods. Code will be available at \url{https://github.com/lifengcs/BlindDiff}
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Jan 25, 2024We introduce Grounded SAM, which uses Grounding DINO as an open-set object detector to combine with the segment anything model (SAM). This integration enables the detection and segmentation of any regions based on arbitrary text inputs and opens a door to connecting various vision models. As shown in Fig.1, a wide range of vision tasks can be achieved by using the versatile Grounded SAM pipeline. For example, an automatic annotation pipeline based solely on input images can be realized by incorporating models such as BLIP and Recognize Anything. Additionally, incorporating Stable-Diffusion allows for controllable image editing, while the integration of OSX facilitates promptable 3D human motion analysis. Grounded SAM also shows superior performance on open-vocabulary benchmarks, achieving 48.7 mean AP on SegInW (Segmentation in the wild) zero-shot benchmark with the combination of Grounding DINO-Base and SAM-Huge models.
Interfacing Foundation Models' Embeddings
Dec 12, 2023We present FIND, a generalized interface for aligning foundation models' embeddings. As shown in teaser figure, a lightweight transformer interface without tuning any foundation model weights is enough for a unified image (segmentation) and dataset-level (retrieval) understanding. The proposed interface has the following favorable attributes: (1) Generalizable. It applies to various tasks spanning retrieval, segmentation, \textit{etc.}, under the same architecture and weights. (2) Prototypable. Different tasks are able to be implemented through prototyping attention masks and embedding types. (3) Extendable. The proposed interface is adaptive to new tasks, and new models. (4) Interleavable. With the benefit of multi-task multi-modal training, the proposed interface creates an interleaved shared embedding space. In light of the interleaved embedding space, we introduce the FIND-Bench, which introduces new training and evaluation annotations to the COCO dataset for interleave segmentation and retrieval. Our approach achieves state-of-the-art performance on FIND-Bench and competitive performance on standard retrieval and segmentation settings. The training, evaluation, and demo code as well as the dataset have been released at https://github.com/UX-Decoder/FIND.
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models
Dec 05, 2023



With the recent significant advancements in large multi-modal models (LMMs), the importance of their grounding capability in visual chat is increasingly recognized. Despite recent efforts to enable LMMs to support grounding, their capabilities for grounding and chat are usually separate, and their chat performance drops dramatically when asked to ground. The problem is the lack of a dataset for grounded visual chat (GVC). Existing grounding datasets only contain short captions. To address this issue, we have created GVC data that allows for the combination of grounding and chat capabilities. To better evaluate the GVC capabilities, we have introduced a benchmark called Grounding-Bench. Additionally, we have proposed a model design that can support GVC and various types of visual prompts by connecting segmentation models with language models. Experimental results demonstrate that our model outperforms other LMMs on Grounding-Bench. Furthermore, our model achieves competitive performance on classic grounding benchmarks like RefCOCO/+/g and Flickr30K Entities. Our code will be released at https://github.com/UX-Decoder/LLaVA-Grounding .