 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024



This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024



This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Streamlined Photoacoustic Image Processing with Foundation Models: A Training-Free Solution
Apr 11, 2024Foundation models have rapidly evolved and have achieved significant accomplishments in computer vision tasks. Specifically, the prompt mechanism conveniently allows users to integrate image prior information into the model, making it possible to apply models without any training. Therefore, we propose a method based on foundation models and zero training to solve the tasks of photoacoustic (PA) image segmentation. We employed the segment anything model (SAM) by setting simple prompts and integrating the model's outputs with prior knowledge of the imaged objects to accomplish various tasks, including: (1) removing the skin signal in three-dimensional PA image rendering; (2) dual speed-of-sound reconstruction, and (3) segmentation of finger blood vessels. Through these demonstrations, we have concluded that deep learning can be directly applied in PA imaging without the requirement for network design and training. This potentially allows for a hands-on, convenient approach to achieving efficient and accurate segmentation of PA images. This letter serves as a comprehensive tutorial, facilitating the mastery of the technique through the provision of code and sample datasets.
FairCLIP: Harnessing Fairness in Vision-Language Learning
Apr 05, 2024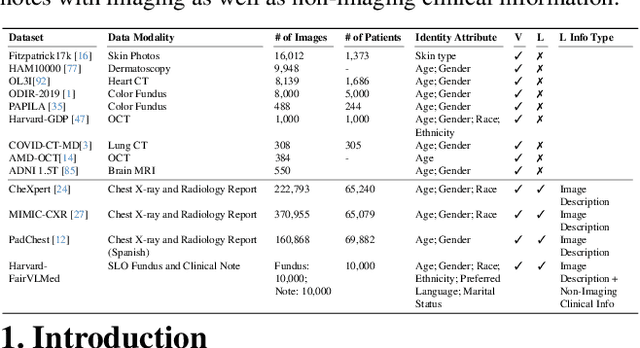
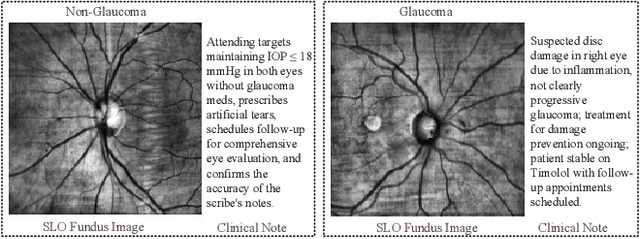
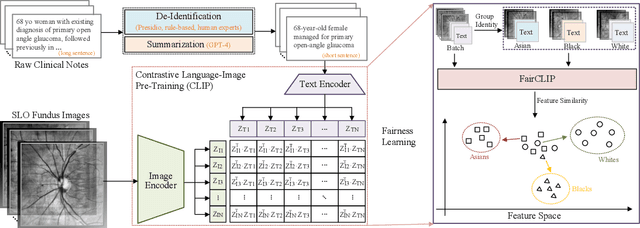
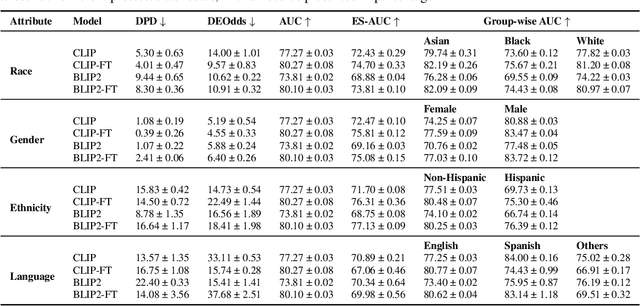
Fairness is a critical concern in deep learning, especially in healthcare, where these models influence diagnoses and treatment decisions. Although fairness has been investigated in the vision-only domain, the fairness of medical vision-language (VL) models remains unexplored due to the scarcity of medical VL datasets for studying fairness. To bridge this research gap, we introduce the first fair vision-language medical dataset Harvard-FairVLMed that provides detailed demographic attributes, ground-truth labels, and clinical notes to facilitate an in-depth examination of fairness within VL foundation models. Using Harvard-FairVLMed, we conduct a comprehensive fairness analysis of two widely-used VL models (CLIP and BLIP2), pre-trained on both natural and medical domains, across four different protected attributes. Our results highlight significant biases in all VL models, with Asian, Male, Non-Hispanic, and Spanish being the preferred subgroups across the protected attributes of race, gender, ethnicity, and language, respectively. In order to alleviate these biases, we propose FairCLIP, an optimal-transport-based approach that achieves a favorable trade-off between performance and fairness by reducing the Sinkhorn distance between the overall sample distribution and the distributions corresponding to each demographic group. As the first VL dataset of its kind, Harvard-FairVLMed holds the potential to catalyze advancements in the development of machine learning models that are both ethically aware and clinically effective. Our dataset and code are available at https://ophai.hms.harvard.edu/datasets/harvard-fairvlmed10k.
MedFLIP: Medical Vision-and-Language Self-supervised Fast Pre-Training with Masked Autoencoder
Mar 07, 2024



Within the domain of medical analysis, extensive research has explored the potential of mutual learning between Masked Autoencoders(MAEs) and multimodal data. However, the impact of MAEs on intermodality remains a key challenge. We introduce MedFLIP, a Fast Language-Image Pre-training method for Medical analysis. We explore MAEs for zero-shot learning with crossed domains, which enhances the model ability to learn from limited data, a common scenario in medical diagnostics. We verify that masking an image does not affect intermodal learning. Furthermore, we propose the SVD loss to enhance the representation learning for characteristics of medical images, aiming to improve classification accuracy by leveraging the structural intricacies of such data. Lastly, we validate using language will improve the zero-shot performance for the medical image analysis. MedFLIP scaling of the masking process marks an advancement in the field, offering a pathway to rapid and precise medical image analysis without the traditional computational bottlenecks. Through experiments and validation, MedFLIP demonstrates efficient performance improvements, setting an explored standard for future research and application in medical diagnostics.
TransFlower: An Explainable Transformer-Based Model with Flow-to-Flow Attention for Commuting Flow Prediction
Feb 23, 2024Understanding the link between urban planning and commuting flows is crucial for guiding urban development and policymaking. This research, bridging computer science and urban studies, addresses the challenge of integrating these fields with their distinct focuses. Traditional urban studies methods, like the gravity and radiation models, often underperform in complex scenarios due to their limited handling of multiple variables and reliance on overly simplistic and unrealistic assumptions, such as spatial isotropy. While deep learning models offer improved accuracy, their black-box nature poses a trade-off between performance and explainability -- both vital for analyzing complex societal phenomena like commuting flows. To address this, we introduce TransFlower, an explainable, transformer-based model employing flow-to-flow attention to predict urban commuting patterns. It features a geospatial encoder with an anisotropy-aware relative location encoder for nuanced flow representation. Following this, the transformer-based flow predictor enhances this by leveraging attention mechanisms to efficiently capture flow interactions. Our model outperforms existing methods by up to 30.8% Common Part of Commuters, offering insights into mobility dynamics crucial for urban planning and policy decisions.
Prismatic: Interactive Multi-View Cluster Analysis of Concept Stocks
Feb 14, 2024Financial cluster analysis allows investors to discover investment alternatives and avoid undertaking excessive risks. However, this analytical task faces substantial challenges arising from many pairwise comparisons, the dynamic correlations across time spans, and the ambiguity in deriving implications from business relational knowledge. We propose Prismatic, a visual analytics system that integrates quantitative analysis of historical performance and qualitative analysis of business relational knowledge to cluster correlated businesses interactively. Prismatic features three clustering processes: dynamic cluster generation, knowledge-based cluster exploration, and correlation-based cluster validation. Utilizing a multi-view clustering approach, it enriches data-driven clusters with knowledge-driven similarity, providing a nuanced understanding of business correlations. Through well-coordinated visual views, Prismatic facilitates a comprehensive interpretation of intertwined quantitative and qualitative features, demonstrating its usefulness and effectiveness via case studies on formulating concept stocks and extensive interviews with domain experts.
Cut-and-Paste: Subject-Driven Video Editing with Attention Control
Nov 20, 2023
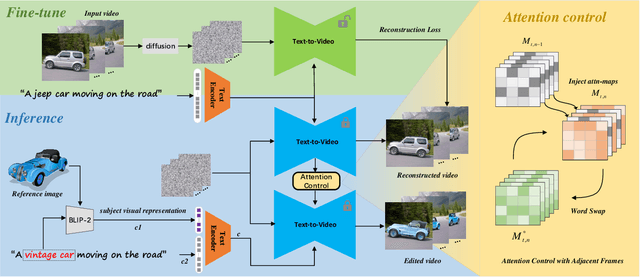


This paper presents a novel framework termed Cut-and-Paste for real-word semantic video editing under the guidance of text prompt and additional reference image. While the text-driven video editing has demonstrated remarkable ability to generate highly diverse videos following given text prompts, the fine-grained semantic edits are hard to control by plain textual prompt only in terms of object details and edited region, and cumbersome long text descriptions are usually needed for the task. We therefore investigate subject-driven video editing for more precise control of both edited regions and background preservation, and fine-grained semantic generation. We achieve this goal by introducing an reference image as supplementary input to the text-driven video editing, which avoids racking your brain to come up with a cumbersome text prompt describing the detailed appearance of the object. To limit the editing area, we refer to a method of cross attention control in image editing and successfully extend it to video editing by fusing the attention map of adjacent frames, which strikes a balance between maintaining video background and spatio-temporal consistency. Compared with current methods, the whole process of our method is like ``cut" the source object to be edited and then ``paste" the target object provided by reference image. We demonstrate that our method performs favorably over prior arts for video editing under the guidance of text prompt and extra reference image, as measured by both quantitative and subjective evaluations.
FairSeg: A Large-scale Medical Image Segmentation Dataset for Fairness Learning with Fair Error-Bound Scaling
Nov 03, 2023Fairness in artificial intelligence models has gained significantly more attention in recent years, especially in the area of medicine, as fairness in medical models is critical to people's well-being and lives. High-quality medical fairness datasets are needed to promote fairness learning research. Existing medical fairness datasets are all for classification tasks, and no fairness datasets are available for medical segmentation, while medical segmentation is an equally important clinical task as classifications, which can provide detailed spatial information on organ abnormalities ready to be assessed by clinicians. In this paper, we propose the first fairness dataset for medical segmentation named FairSeg with 10,000 subject samples. In addition, we propose a fair error-bound scaling approach to reweight the loss function with the upper error-bound in each identity group. We anticipate that the segmentation performance equity can be improved by explicitly tackling the hard cases with high training errors in each identity group. To facilitate fair comparisons, we propose new equity-scaled segmentation performance metrics, such as the equity-scaled Dice coefficient, which is calculated as the overall Dice coefficient divided by one plus the standard deviation of group Dice coefficients. Through comprehensive experiments, we demonstrate that our fair error-bound scaling approach either has superior or comparable fairness performance to the state-of-the-art fairness learning models. The dataset and code are publicly accessible via \url{https://github.com/Harvard-Ophthalmology-AI-Lab/FairSeg}.