 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Spatial-Temporal Modeling and Contrastive Learning for Self-supervised Heart Rate Measurement
Jun 07, 2024This paper briefly introduces the solutions developed by our team, HFUT-VUT, for Track 1 of self-supervised heart rate measurement in the 3rd Vision-based Remote Physiological Signal Sensing (RePSS) Challenge hosted at IJCAI 2024. The goal is to develop a self-supervised learning algorithm for heart rate (HR) estimation using unlabeled facial videos. To tackle this task, we present two self-supervised HR estimation solutions that integrate spatial-temporal modeling and contrastive learning, respectively. Specifically, we first propose a non-end-to-end self-supervised HR measurement framework based on spatial-temporal modeling, which can effectively capture subtle rPPG clues and leverage the inherent bandwidth and periodicity characteristics of rPPG to constrain the model. Meanwhile, we employ an excellent end-to-end solution based on contrastive learning, aiming to generalize across different scenarios from complementary perspectives. Finally, we combine the strengths of the above solutions through an ensemble strategy to generate the final predictions, leading to a more accurate HR estimation. As a result, our solutions achieved a remarkable RMSE score of 8.85277 on the test dataset, securing \textbf{2nd place} in Track 1 of the challenge.
Advancing Weakly-Supervised Audio-Visual Video Parsing via Segment-wise Pseudo Labeling
Jun 03, 2024The Audio-Visual Video Parsing task aims to identify and temporally localize the events that occur in either or both the audio and visual streams of audible videos. It often performs in a weakly-supervised manner, where only video event labels are provided, \ie, the modalities and the timestamps of the labels are unknown. Due to the lack of densely annotated labels, recent work attempts to leverage pseudo labels to enrich the supervision. A commonly used strategy is to generate pseudo labels by categorizing the known video event labels for each modality. However, the labels are still confined to the video level, and the temporal boundaries of events remain unlabeled. In this paper, we propose a new pseudo label generation strategy that can explicitly assign labels to each video segment by utilizing prior knowledge learned from the open world. Specifically, we exploit the large-scale pretrained models, namely CLIP and CLAP, to estimate the events in each video segment and generate segment-level visual and audio pseudo labels, respectively. We then propose a new loss function to exploit these pseudo labels by taking into account their category-richness and segment-richness. A label denoising strategy is also adopted to further improve the visual pseudo labels by flipping them whenever abnormally large forward losses occur. We perform extensive experiments on the LLP dataset and demonstrate the effectiveness of each proposed design and we achieve state-of-the-art video parsing performance on all types of event parsing, \ie, audio event, visual event, and audio-visual event. We also examine the proposed pseudo label generation strategy on a relevant weakly-supervised audio-visual event localization task and the experimental results again verify the benefits and generalization of our method.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Unified Static and Dynamic Network: Efficient Temporal Filtering for Video Grounding
Mar 21, 2024



Inspired by the activity-silent and persistent activity mechanisms in human visual perception biology, we design a Unified Static and Dynamic Network (UniSDNet), to learn the semantic association between the video and text/audio queries in a cross-modal environment for efficient video grounding. For static modeling, we devise a novel residual structure (ResMLP) to boost the global comprehensive interaction between the video segments and queries, achieving more effective semantic enhancement/supplement. For dynamic modeling, we effectively exploit three characteristics of the persistent activity mechanism in our network design for a better video context comprehension. Specifically, we construct a diffusely connected video clip graph on the basis of 2D sparse temporal masking to reflect the "short-term effect" relationship. We innovatively consider the temporal distance and relevance as the joint "auxiliary evidence clues" and design a multi-kernel Temporal Gaussian Filter to expand the context clue into high-dimensional space, simulating the "complex visual perception", and then conduct element level filtering convolution operations on neighbour clip nodes in message passing stage for finally generating and ranking the candidate proposals. Our UniSDNet is applicable to both Natural Language Video Grounding (NLVG) and Spoken Language Video Grounding (SLVG) tasks. Our UniSDNet achieves SOTA performance on three widely used datasets for NLVG, as well as three datasets for SLVG, e.g., reporting new records at 38.88% R@1,IoU@0.7 on ActivityNet Captions and 40.26% R@1,IoU@0.5 on TACoS. To facilitate this field, we collect two new datasets (Charades-STA Speech and TACoS Speech) for SLVG task. Meanwhile, the inference speed of our UniSDNet is 1.56$\times$ faster than the strong multi-query benchmark. Code is available at: https://github.com/xian-sh/UniSDNet.
Training A Small Emotional Vision Language Model for Visual Art Comprehension
Mar 17, 2024



This paper develops small vision language models to understand visual art, which, given an art work, aims to identify its emotion category and explain this prediction with natural language. While small models are computationally efficient, their capacity is much limited compared with large models. To break this trade-off, this paper builds a small emotional vision language model (SEVLM) by emotion modeling and input-output feature alignment. On the one hand, based on valence-arousal-dominance (VAD) knowledge annotated by psychology experts, we introduce and fuse emotional features derived through VAD dictionary and a VAD head to align VAD vectors of predicted emotion explanation and the ground truth. This allows the vision language model to better understand and generate emotional texts, compared with using traditional text embeddings alone. On the other hand, we design a contrastive head to pull close embeddings of the image, its emotion class, and explanation, which aligns model outputs and inputs. On two public affective explanation datasets, we show that the proposed techniques consistently improve the visual art understanding performance of baseline SEVLMs. Importantly, the proposed model can be trained and evaluated on a single RTX 2080 Ti while exhibiting very strong performance: it not only outperforms the state-of-the-art small models but is also competitive compared with LLaVA 7B after fine-tuning and GPT4(V).
Frequency Decoupling for Motion Magnification via Multi-Level Isomorphic Architecture
Mar 12, 2024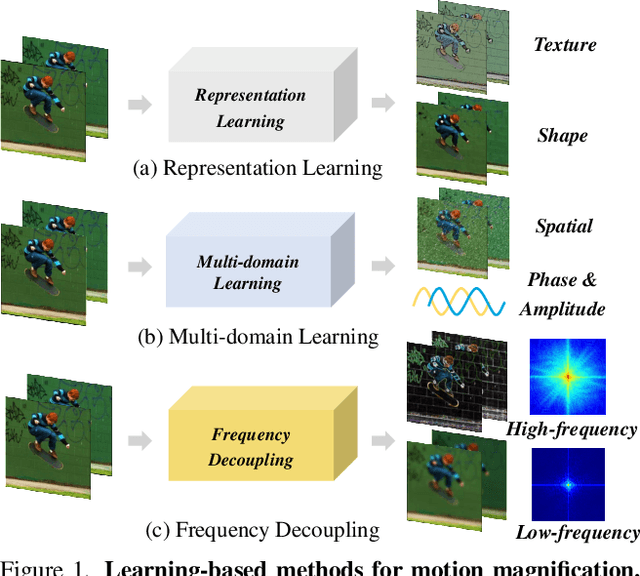
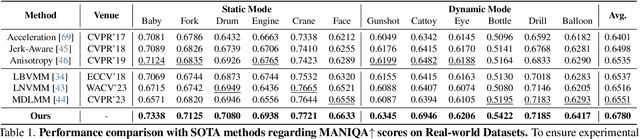
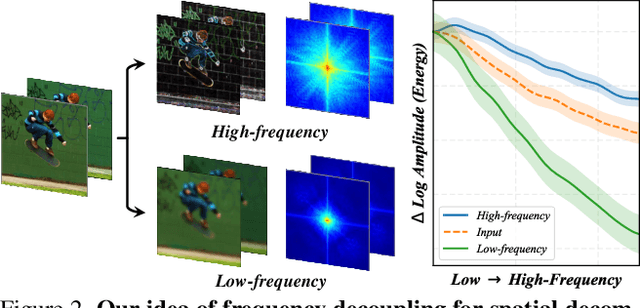
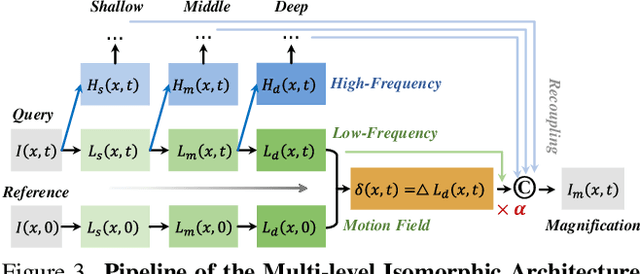
Video Motion Magnification (VMM) aims to reveal subtle and imperceptible motion information of objects in the macroscopic world. Prior methods directly model the motion field from the Eulerian perspective by Representation Learning that separates shape and texture or Multi-domain Learning from phase fluctuations. Inspired by the frequency spectrum, we observe that the low-frequency components with stable energy always possess spatial structure and less noise, making them suitable for modeling the subtle motion field. To this end, we present FD4MM, a new paradigm of Frequency Decoupling for Motion Magnification with a Multi-level Isomorphic Architecture to capture multi-level high-frequency details and a stable low-frequency structure (motion field) in video space. Since high-frequency details and subtle motions are susceptible to information degradation due to their inherent subtlety and unavoidable external interference from noise, we carefully design Sparse High/Low-pass Filters to enhance the integrity of details and motion structures, and a Sparse Frequency Mixer to promote seamless recoupling. Besides, we innovatively design a contrastive regularization for this task to strengthen the model's ability to discriminate irrelevant features, reducing undesired motion magnification. Extensive experiments on both Real-world and Synthetic Datasets show that our FD4MM outperforms SOTA methods. Meanwhile, FD4MM reduces FLOPs by 1.63$\times$ and boosts inference speed by 1.68$\times$ than the latest method. Our code is available at https://github.com/Jiafei127/FD4MM.
Benchmarking Micro-action Recognition: Dataset, Methods, and Applications
Mar 08, 2024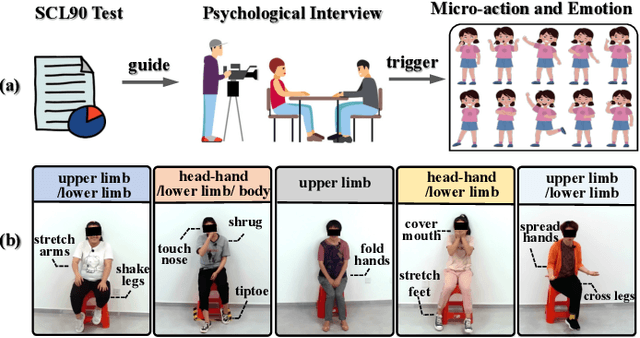
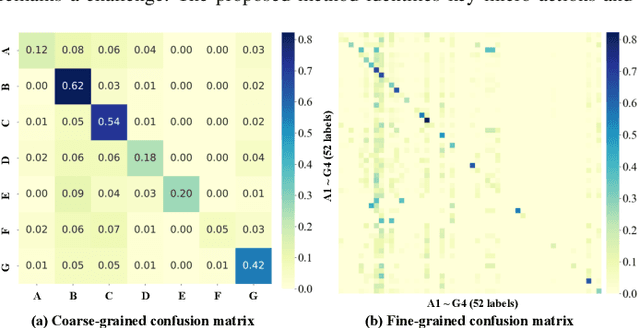
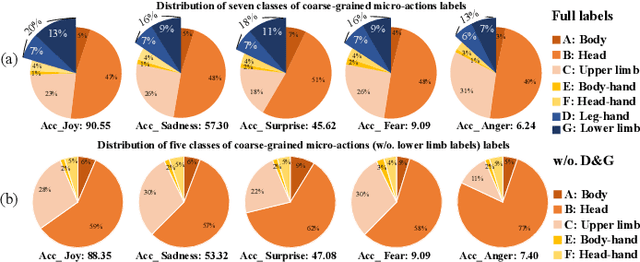
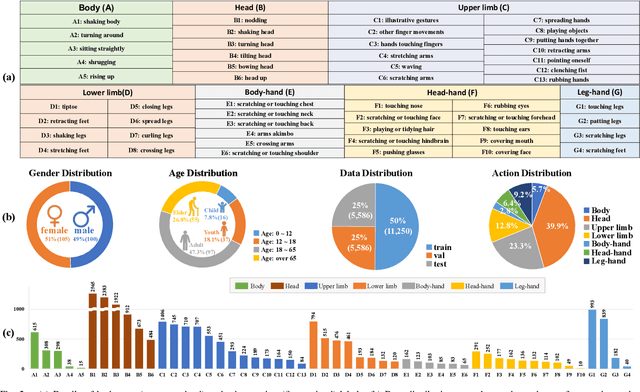
Micro-action is an imperceptible non-verbal behaviour characterised by low-intensity movement. It offers insights into the feelings and intentions of individuals and is important for human-oriented applications such as emotion recognition and psychological assessment. However, the identification, differentiation, and understanding of micro-actions pose challenges due to the imperceptible and inaccessible nature of these subtle human behaviors in everyday life. In this study, we innovatively collect a new micro-action dataset designated as Micro-action-52 (MA-52), and propose a benchmark named micro-action network (MANet) for micro-action recognition (MAR) task. Uniquely, MA-52 provides the whole-body perspective including gestures, upper- and lower-limb movements, attempting to reveal comprehensive micro-action cues. In detail, MA-52 contains 52 micro-action categories along with seven body part labels, and encompasses a full array of realistic and natural micro-actions, accounting for 205 participants and 22,422 video instances collated from the psychological interviews. Based on the proposed dataset, we assess MANet and other nine prevalent action recognition methods. MANet incorporates squeeze-and excitation (SE) and temporal shift module (TSM) into the ResNet architecture for modeling the spatiotemporal characteristics of micro-actions. Then a joint-embedding loss is designed for semantic matching between video and action labels; the loss is used to better distinguish between visually similar yet distinct micro-action categories. The extended application in emotion recognition has demonstrated one of the important values of our proposed dataset and method. In the future, further exploration of human behaviour, emotion, and psychological assessment will be conducted in depth. The dataset and source code are released at https://github.com/VUT-HFUT/Micro-Action.
Object-aware Adaptive-Positivity Learning for Audio-Visual Question Answering
Dec 20, 2023This paper focuses on the Audio-Visual Question Answering (AVQA) task that aims to answer questions derived from untrimmed audible videos. To generate accurate answers, an AVQA model is expected to find the most informative audio-visual clues relevant to the given questions. In this paper, we propose to explicitly consider fine-grained visual objects in video frames (object-level clues) and explore the multi-modal relations(i.e., the object, audio, and question) in terms of feature interaction and model optimization. For the former, we present an end-to-end object-oriented network that adopts a question-conditioned clue discovery module to concentrate audio/visual modalities on respective keywords of the question and designs a modality-conditioned clue collection module to highlight closely associated audio segments or visual objects. For model optimization, we propose an object-aware adaptive-positivity learning strategy that selects the highly semantic-matched multi-modal pair as positivity. Specifically, we design two object-aware contrastive loss functions to identify the highly relevant question-object pairs and audio-object pairs, respectively. These selected pairs are constrained to have larger similarity values than the mismatched pairs. The positivity-selecting process is adaptive as the positivity pairs selected in each video frame may be different. These two object-aware objectives help the model understand which objects are exactly relevant to the question and which are making sounds. Extensive experiments on the MUSIC-AVQA dataset demonstrate the proposed method is effective in finding favorable audio-visual clues and also achieves new state-of-the-art question-answering performance.
EulerMormer: Robust Eulerian Motion Magnification via Dynamic Filtering within Transformer
Dec 07, 2023Video Motion Magnification (VMM) aims to break the resolution limit of human visual perception capability and reveal the imperceptible minor motion that contains valuable information in the macroscopic domain. However, challenges arise in this task due to photon noise inevitably introduced by photographic devices and spatial inconsistency in amplification, leading to flickering artifacts in static fields and motion blur and distortion in dynamic fields in the video. Existing methods focus on explicit motion modeling without emphasizing prioritized denoising during the motion magnification process. This paper proposes a novel dynamic filtering strategy to achieve static-dynamic field adaptive denoising. Specifically, based on Eulerian theory, we separate texture and shape to extract motion representation through inter-frame shape differences, expecting to leverage these subdivided features to solve this task finely. Then, we introduce a novel dynamic filter that eliminates noise cues and preserves critical features in the motion magnification and amplification generation phases. Overall, our unified framework, EulerMormer, is a pioneering effort to first equip with Transformer in learning-based VMM. The core of the dynamic filter lies in a global dynamic sparse cross-covariance attention mechanism that explicitly removes noise while preserving vital information, coupled with a multi-scale dual-path gating mechanism that selectively regulates the dependence on different frequency features to reduce spatial attenuation and complement motion boundaries. We demonstrate extensive experiments that EulerMormer achieves more robust video motion magnification from the Eulerian perspective, significantly outperforming state-of-the-art methods. The source code is available at https://github.com/VUT-HFUT/EulerMormer.
Exploring Sparse Spatial Relation in Graph Inference for Text-Based VQA
Oct 13, 2023



Text-based visual question answering (TextVQA) faces the significant challenge of avoiding redundant relational inference. To be specific, a large number of detected objects and optical character recognition (OCR) tokens result in rich visual relationships. Existing works take all visual relationships into account for answer prediction. However, there are three observations: (1) a single subject in the images can be easily detected as multiple objects with distinct bounding boxes (considered repetitive objects). The associations between these repetitive objects are superfluous for answer reasoning; (2) two spatially distant OCR tokens detected in the image frequently have weak semantic dependencies for answer reasoning; and (3) the co-existence of nearby objects and tokens may be indicative of important visual cues for predicting answers. Rather than utilizing all of them for answer prediction, we make an effort to identify the most important connections or eliminate redundant ones. We propose a sparse spatial graph network (SSGN) that introduces a spatially aware relation pruning technique to this task. As spatial factors for relation measurement, we employ spatial distance, geometric dimension, overlap area, and DIoU for spatially aware pruning. We consider three visual relationships for graph learning: object-object, OCR-OCR tokens, and object-OCR token relationships. SSGN is a progressive graph learning architecture that verifies the pivotal relations in the correlated object-token sparse graph, and then in the respective object-based sparse graph and token-based sparse graph. Experiment results on TextVQA and ST-VQA datasets demonstrate that SSGN achieves promising performances. And some visualization results further demonstrate the interpretability of our method.