 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency for Free: Ideal Data Are Transportable Representations
May 23, 2024Data, the seminal opportunity and challenge in modern machine learning, currently constrains the scalability of representation learning and impedes the pace of model evolution. Existing paradigms tackle the issue of learning efficiency over massive datasets from the perspective of self-supervised learning and dataset distillation independently, while neglecting the untapped potential of accelerating representation learning from an intermediate standpoint. In this work, we delve into defining the ideal data properties from both optimization and generalization perspectives. We propose that model-generated representations, despite being trained on diverse tasks and architectures, converge to a shared linear space, facilitating effective linear transport between models. Furthermore, we demonstrate that these representations exhibit properties conducive to the formation of ideal data. The theoretical/empirical insights therein inspire us to propose a Representation Learning Accelerator (ReLA), which leverages a task- and architecture-agnostic, yet publicly available, free model to form a dynamic data subset and thus accelerate (self-)supervised learning. For instance, employing a CLIP ViT B/16 as a prior model for dynamic data generation, ReLA-aided BYOL can train a ResNet-50 from scratch with 50% of ImageNet-1K, yielding performance surpassing that of training on the full dataset. Additionally, employing a ResNet-18 pre-trained on CIFAR-10 can enhance ResNet-50 training on 10% of ImageNet-1K, resulting in a 7.7% increase in accuracy.
GIFT: Unlocking Full Potential of Labels in Distilled Dataset at Near-zero Cost
May 23, 2024Recent advancements in dataset distillation have demonstrated the significant benefits of employing soft labels generated by pre-trained teacher models. In this paper, we introduce a novel perspective by emphasizing the full utilization of labels. We first conduct a comprehensive comparison of various loss functions for soft label utilization in dataset distillation, revealing that the model trained on the synthetic dataset exhibits high sensitivity to the choice of loss function for soft label utilization. This finding highlights the necessity of a universal loss function for training models on synthetic datasets. Building on these insights, we introduce an extremely simple yet surprisingly effective plug-and-play approach, GIFT, which encompasses soft label refinement and a cosine similarity-based loss function to efficiently leverage full label information. Extensive experiments demonstrate that GIFT consistently enhances the state-of-the-art dataset distillation methods across various scales datasets without incurring additional computational costs. For instance, on ImageNet-1K with IPC = 10, GIFT improves the SOTA method RDED by 3.9% and 1.8% on ConvNet and ResNet-18, respectively. Code: https://github.com/LINs-lab/GIFT.
Networking Systems for Video Anomaly Detection: A Tutorial and Survey
May 16, 2024The increasing prevalence of surveillance cameras in smart cities, coupled with the surge of online video applications, has heightened concerns regarding public security and privacy protection, which propelled automated Video Anomaly Detection (VAD) into a fundamental research task within the Artificial Intelligence (AI) community. With the advancements in deep learning and edge computing, VAD has made significant progress and advances synergized with emerging applications in smart cities and video internet, which has moved beyond the conventional research scope of algorithm engineering to deployable Networking Systems for VAD (NSVAD), a practical hotspot for intersection exploration in the AI, IoVT, and computing fields. In this article, we delineate the foundational assumptions, learning frameworks, and applicable scenarios of various deep learning-driven VAD routes, offering an exhaustive tutorial for novices in NSVAD. This article elucidates core concepts by reviewing recent advances and typical solutions, and aggregating available research resources (e.g., literatures, code, tools, and workshops) accessible at https://github.com/fdjingliu/NSVAD. Additionally, we showcase our latest NSVAD research in industrial IoT and smart cities, along with an end-cloud collaborative architecture for deployable NSVAD to further elucidate its potential scope of research and application. Lastly, this article projects future development trends and discusses how the integration of AI and computing technologies can address existing research challenges and promote open opportunities, serving as an insightful guide for prospective researchers and engineers.
Large Language Models for Mobility in Transportation Systems: A Survey on Forecasting Tasks
May 03, 2024Mobility analysis is a crucial element in the research area of transportation systems. Forecasting traffic information offers a viable solution to address the conflict between increasing transportation demands and the limitations of transportation infrastructure. Predicting human travel is significant in aiding various transportation and urban management tasks, such as taxi dispatch and urban planning. Machine learning and deep learning methods are favored for their flexibility and accuracy. Nowadays, with the advent of large language models (LLMs), many researchers have combined these models with previous techniques or applied LLMs to directly predict future traffic information and human travel behaviors. However, there is a lack of comprehensive studies on how LLMs can contribute to this field. This survey explores existing approaches using LLMs for mobility forecasting problems. We provide a literature review concerning the forecasting applications within transportation systems, elucidating how researchers utilize LLMs, showcasing recent state-of-the-art advancements, and identifying the challenges that must be overcome to fully leverage LLMs in this domain.
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Apr 15, 2024The context window of large language models (LLMs) is rapidly increasing, leading to a huge variance in resource usage between different requests as well as between different phases of the same request. Restricted by static parallelism strategies, existing LLM serving systems cannot efficiently utilize the underlying resources to serve variable-length requests in different phases. To address this problem, we propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances. Our evaluation under diverse real-world datasets shows that LoongServe improves the maximum throughput by up to 3.85$\times$ compared to the chunked prefill and 5.81$\times$ compared to the prefill-decoding disaggregation.
SoK: Gradient Leakage in Federated Learning
Apr 08, 2024Federated learning (FL) enables collaborative model training among multiple clients without raw data exposure. However, recent studies have shown that clients' private training data can be reconstructed from the gradients they share in FL, known as gradient inversion attacks (GIAs). While GIAs have demonstrated effectiveness under \emph{ideal settings and auxiliary assumptions}, their actual efficacy against \emph{practical FL systems} remains under-explored. To address this gap, we conduct a comprehensive study on GIAs in this work. We start with a survey of GIAs that establishes a milestone to trace their evolution and develops a systematization to uncover their inherent threats. Specifically, we categorize the auxiliary assumptions used by existing GIAs based on their practical accessibility to potential adversaries. To facilitate deeper analysis, we highlight the challenges that GIAs face in practical FL systems from three perspectives: \textit{local training}, \textit{model}, and \textit{post-processing}. We then perform extensive theoretical and empirical evaluations of state-of-the-art GIAs across diverse settings, utilizing eight datasets and thirteen models. Our findings indicate that GIAs have inherent limitations when reconstructing data under practical local training settings. Furthermore, their efficacy is sensitive to the trained model, and even simple post-processing measures applied to gradients can be effective defenses. Overall, our work provides crucial insights into the limited effectiveness of GIAs in practical FL systems. By rectifying prior misconceptions, we hope to inspire more accurate and realistic investigations on this topic.
InternLM2 Technical Report
Mar 26, 2024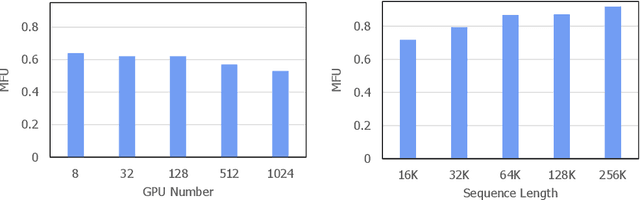
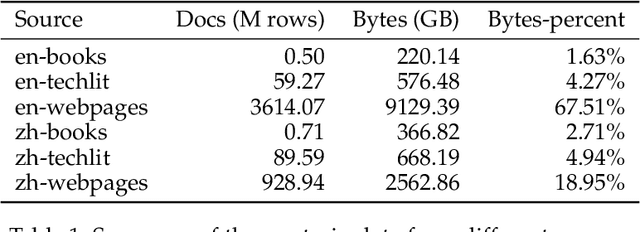


The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Characterization of Large Language Model Development in the Datacenter
Mar 12, 2024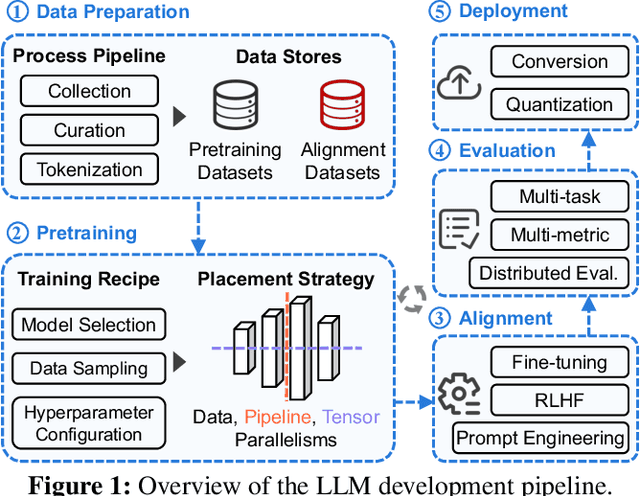

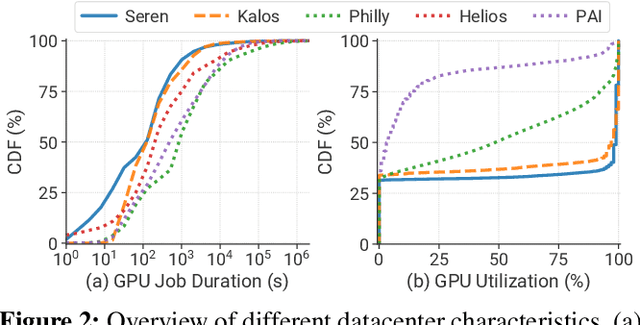
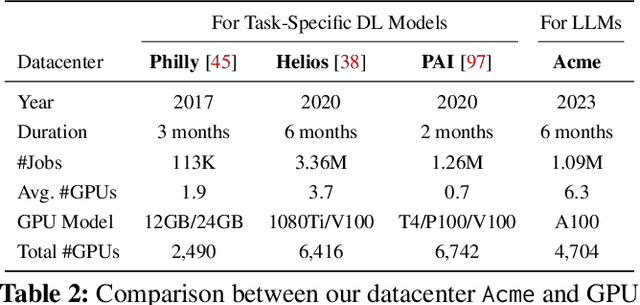
Large Language Models (LLMs) have presented impressive performance across several transformative tasks. However, it is non-trivial to efficiently utilize large-scale cluster resources to develop LLMs, often riddled with numerous challenges such as frequent hardware failures, intricate parallelization strategies, and imbalanced resource utilization. In this paper, we present an in-depth characterization study of a six-month LLM development workload trace collected from our GPU datacenter Acme. Specifically, we investigate discrepancies between LLMs and prior task-specific Deep Learning (DL) workloads, explore resource utilization patterns, and identify the impact of various job failures. Our analysis summarizes hurdles we encountered and uncovers potential opportunities to optimize systems tailored for LLMs. Furthermore, we introduce our system efforts: (1) fault-tolerant pretraining, which enhances fault tolerance through LLM-involved failure diagnosis and automatic recovery. (2) decoupled scheduling for evaluation, which achieves timely performance feedback via trial decomposition and scheduling optimization.
RobWE: Robust Watermark Embedding for Personalized Federated Learning Model Ownership Protection
Feb 29, 2024Embedding watermarks into models has been widely used to protect model ownership in federated learning (FL). However, existing methods are inadequate for protecting the ownership of personalized models acquired by clients in personalized FL (PFL). This is due to the aggregation of the global model in PFL, resulting in conflicts over clients' private watermarks. Moreover, malicious clients may tamper with embedded watermarks to facilitate model leakage and evade accountability. This paper presents a robust watermark embedding scheme, named RobWE, to protect the ownership of personalized models in PFL. We first decouple the watermark embedding of personalized models into two parts: head layer embedding and representation layer embedding. The head layer belongs to clients' private part without participating in model aggregation, while the representation layer is the shared part for aggregation. For representation layer embedding, we employ a watermark slice embedding operation, which avoids watermark embedding conflicts. Furthermore, we design a malicious watermark detection scheme enabling the server to verify the correctness of watermarks before aggregating local models. We conduct an exhaustive experimental evaluation of RobWE. The results demonstrate that RobWE significantly outperforms the state-of-the-art watermark embedding schemes in FL in terms of fidelity, reliability, and robustness.
Large Language Models as Agents in Two-Player Games
Feb 12, 2024By formally defining the training processes of large language models (LLMs), which usually encompasses pre-training, supervised fine-tuning, and reinforcement learning with human feedback, within a single and unified machine learning paradigm, we can glean pivotal insights for advancing LLM technologies. This position paper delineates the parallels between the training methods of LLMs and the strategies employed for the development of agents in two-player games, as studied in game theory, reinforcement learning, and multi-agent systems. We propose a re-conceptualization of LLM learning processes in terms of agent learning in language-based games. This framework unveils innovative perspectives on the successes and challenges in LLM development, offering a fresh understanding of addressing alignment issues among other strategic considerations. Furthermore, our two-player game approach sheds light on novel data preparation and machine learning techniques for training LLMs.