 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Learning with Missing Modality in Predicting Axillary Lymph Node Metastasis
Jan 03, 2024Multi-modal Learning has attracted widespread attention in medical image analysis. Using multi-modal data, whole slide images (WSIs) and clinical information, can improve the performance of deep learning models in the diagnosis of axillary lymph node metastasis. However, clinical information is not easy to collect in clinical practice due to privacy concerns, limited resources, lack of interoperability, etc. Although patient selection can ensure the training set to have multi-modal data for model development, missing modality of clinical information can appear during test. This normally leads to performance degradation, which limits the use of multi-modal models in the clinic. To alleviate this problem, we propose a bidirectional distillation framework consisting of a multi-modal branch and a single-modal branch. The single-modal branch acquires the complete multi-modal knowledge from the multi-modal branch, while the multi-modal learns the robust features of WSI from the single-modal. We conduct experiments on a public dataset of Lymph Node Metastasis in Early Breast Cancer to validate the method. Our approach not only achieves state-of-the-art performance with an AUC of 0.861 on the test set without missing data, but also yields an AUC of 0.842 when the rate of missing modality is 80\%. This shows the effectiveness of the approach in dealing with multi-modal data and missing modality. Such a model has the potential to improve treatment decision-making for early breast cancer patients who have axillary lymph node metastatic status.
SegRap2023: A Benchmark of Organs-at-Risk and Gross Tumor Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Dec 15, 2023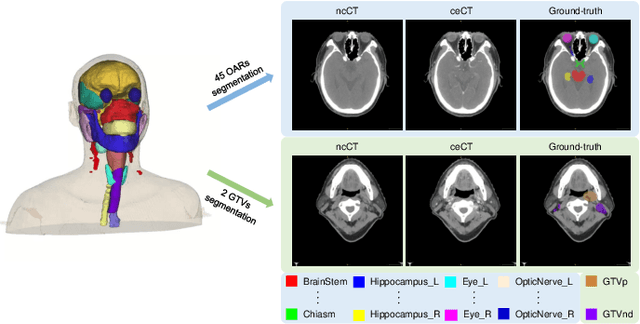

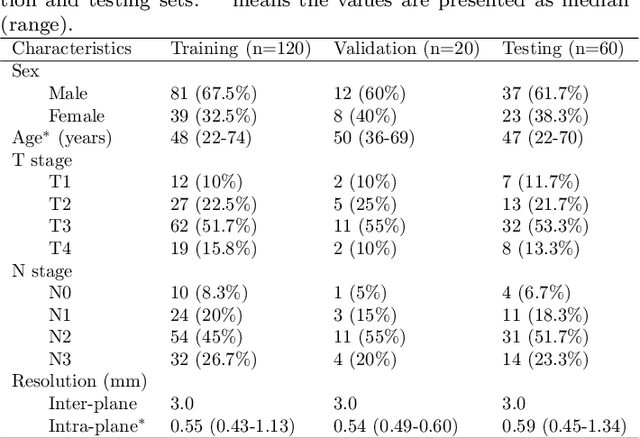
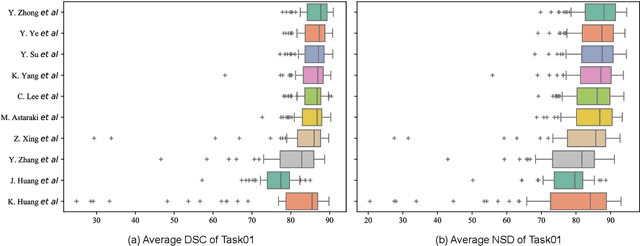
Radiation therapy is a primary and effective NasoPharyngeal Carcinoma (NPC) treatment strategy. The precise delineation of Gross Tumor Volumes (GTVs) and Organs-At-Risk (OARs) is crucial in radiation treatment, directly impacting patient prognosis. Previously, the delineation of GTVs and OARs was performed by experienced radiation oncologists. Recently, deep learning has achieved promising results in many medical image segmentation tasks. However, for NPC OARs and GTVs segmentation, few public datasets are available for model development and evaluation. To alleviate this problem, the SegRap2023 challenge was organized in conjunction with MICCAI2023 and presented a large-scale benchmark for OAR and GTV segmentation with 400 Computed Tomography (CT) scans from 200 NPC patients, each with a pair of pre-aligned non-contrast and contrast-enhanced CT scans. The challenge's goal was to segment 45 OARs and 2 GTVs from the paired CT scans. In this paper, we detail the challenge and analyze the solutions of all participants. The average Dice similarity coefficient scores for all submissions ranged from 76.68\% to 86.70\%, and 70.42\% to 73.44\% for OARs and GTVs, respectively. We conclude that the segmentation of large-size OARs is well-addressed, and more efforts are needed for GTVs and small-size or thin-structure OARs. The benchmark will remain publicly available here: https://segrap2023.grand-challenge.org
Scribble-based 3D Multiple Abdominal Organ Segmentation via Triple-branch Multi-dilated Network with Pixel- and Class-wise Consistency
Sep 18, 2023


Multi-organ segmentation in abdominal Computed Tomography (CT) images is of great importance for diagnosis of abdominal lesions and subsequent treatment planning. Though deep learning based methods have attained high performance, they rely heavily on large-scale pixel-level annotations that are time-consuming and labor-intensive to obtain. Due to its low dependency on annotation, weakly supervised segmentation has attracted great attention. However, there is still a large performance gap between current weakly-supervised methods and fully supervised learning, leaving room for exploration. In this work, we propose a novel 3D framework with two consistency constraints for scribble-supervised multiple abdominal organ segmentation from CT. Specifically, we employ a Triple-branch multi-Dilated network (TDNet) with one encoder and three decoders using different dilation rates to capture features from different receptive fields that are complementary to each other to generate high-quality soft pseudo labels. For more stable unsupervised learning, we use voxel-wise uncertainty to rectify the soft pseudo labels and then supervise the outputs of each decoder. To further regularize the network, class relationship information is exploited by encouraging the generated class affinity matrices to be consistent across different decoders under multi-view projection. Experiments on the public WORD dataset show that our method outperforms five existing scribble-supervised methods.
Exploring Unsupervised Cell Recognition with Prior Self-activation Maps
Aug 22, 2023



The success of supervised deep learning models on cell recognition tasks relies on detailed annotations. Many previous works have managed to reduce the dependency on labels. However, considering the large number of cells contained in a patch, costly and inefficient labeling is still inevitable. To this end, we explored label-free methods for cell recognition. Prior self-activation maps (PSM) are proposed to generate pseudo masks as training targets. To be specific, an activation network is trained with self-supervised learning. The gradient information in the shallow layers of the network is aggregated to generate prior self-activation maps. Afterward, a semantic clustering module is then introduced as a pipeline to transform PSMs to pixel-level semantic pseudo masks for downstream tasks. We evaluated our method on two histological datasets: MoNuSeg (cell segmentation) and BCData (multi-class cell detection). Compared with other fully-supervised and weakly-supervised methods, our method can achieve competitive performance without any manual annotations. Our simple but effective framework can also achieve multi-class cell detection which can not be done by existing unsupervised methods. The results show the potential of PSMs that might inspire other research to deal with the hunger for labels in medical area.
Masked conditional variational autoencoders for chromosome straightening
Jun 25, 2023



Karyotyping is of importance for detecting chromosomal aberrations in human disease. However, chromosomes easily appear curved in microscopic images, which prevents cytogeneticists from analyzing chromosome types. To address this issue, we propose a framework for chromosome straightening, which comprises a preliminary processing algorithm and a generative model called masked conditional variational autoencoders (MC-VAE). The processing method utilizes patch rearrangement to address the difficulty in erasing low degrees of curvature, providing reasonable preliminary results for the MC-VAE. The MC-VAE further straightens the results by leveraging chromosome patches conditioned on their curvatures to learn the mapping between banding patterns and conditions. During model training, we apply a masking strategy with a high masking ratio to train the MC-VAE with eliminated redundancy. This yields a non-trivial reconstruction task, allowing the model to effectively preserve chromosome banding patterns and structure details in the reconstructed results. Extensive experiments on three public datasets with two stain styles show that our framework surpasses the performance of state-of-the-art methods in retaining banding patterns and structure details. Compared to using real-world bent chromosomes, the use of high-quality straightened chromosomes generated by our proposed method can improve the performance of various deep learning models for chromosome classification by a large margin. Such a straightening approach has the potential to be combined with other karyotyping systems to assist cytogeneticists in chromosome analysis.
Semi-supervised Cell Recognition under Point Supervision
Jun 14, 2023Cell recognition is a fundamental task in digital histopathology image analysis. Point-based cell recognition (PCR) methods normally require a vast number of annotations, which is extremely costly, time-consuming and labor-intensive. Semi-supervised learning (SSL) can provide a shortcut to make full use of cell information in gigapixel whole slide images without exhaustive labeling. However, research into semi-supervised point-based cell recognition (SSPCR) remains largely overlooked. Previous SSPCR works are all built on density map-based PCR models, which suffer from unsatisfactory accuracy, slow inference speed and high sensitivity to hyper-parameters. To address these issues, end-to-end PCR models are proposed recently. In this paper, we develop a SSPCR framework suitable for the end-to-end PCR models for the first time. Overall, we use the current models to generate pseudo labels for unlabeled images, which are in turn utilized to supervise the models training. Besides, we introduce a co-teaching strategy to overcome the confirmation bias problem that generally exists in self-training. A distribution alignment technique is also incorporated to produce high-quality, unbiased pseudo labels for unlabeled data. Experimental results on four histopathology datasets concerning different types of staining styles show the effectiveness and versatility of the proposed framework. Code is available at \textcolor{magenta}{\url{https://github.com/windygooo/SSPCR}
Deformable Proposal-Aware P2PNet: A Universal Network for Cell Recognition under Point Supervision
Mar 05, 2023



Point-based cell recognition, which aims to localize and classify cells present in a pathology image, is a fundamental task in digital pathology image analysis. The recently developed point-to-point network (P2PNet) has achieved unprecedented cell recognition accuracy and efficiency compared to methods that rely on intermediate density map representations. However, P2PNet could not leverage multi-scale information since it can only decode a single feature map. Moreover, the distribution of predefined point proposals, which is determined by data properties, restricts the resolution of the feature map to decode, i.e., the encoder design. To lift these limitations, we propose a variant of P2PNet named deformable proposal-aware P2PNet (DPA-P2PNet) in this study. The proposed method uses coordinates of point proposals to directly extract multi-scale region-of-interest (ROI) features for feature enhancement. Such a design also opens up possibilities to exploit dynamic distributions of proposals. We further devise a deformation module to improve the proposal quality. Extensive experiments on four datasets with various staining styles demonstrate that DPA-P2PNet outperforms the state-of-the-art methods on point-based cell recognition, which reveals the high potentiality in assisting pathologist assessments.
CDDSA: Contrastive Domain Disentanglement and Style Augmentation for Generalizable Medical Image Segmentation
Nov 22, 2022



Generalization to previously unseen images with potential domain shifts and different styles is essential for clinically applicable medical image segmentation, and the ability to disentangle domain-specific and domain-invariant features is key for achieving Domain Generalization (DG). However, existing DG methods can hardly achieve effective disentanglement to get high generalizability. To deal with this problem, we propose an efficient Contrastive Domain Disentanglement and Style Augmentation (CDDSA) framework for generalizable medical image segmentation. First, a disentangle network is proposed to decompose an image into a domain-invariant anatomical representation and a domain-specific style code, where the former is sent to a segmentation model that is not affected by the domain shift, and the disentangle network is regularized by a decoder that combines the anatomical and style codes to reconstruct the input image. Second, to achieve better disentanglement, a contrastive loss is proposed to encourage the style codes from the same domain and different domains to be compact and divergent, respectively. Thirdly, to further improve generalizability, we propose a style augmentation method based on the disentanglement representation to synthesize images in various unseen styles with shared anatomical structures. Our method was validated on a public multi-site fundus image dataset for optic cup and disc segmentation and an in-house multi-site Nasopharyngeal Carcinoma Magnetic Resonance Image (NPC-MRI) dataset for nasopharynx Gross Tumor Volume (GTVnx) segmentation. Experimental results showed that the proposed CDDSA achieved remarkable generalizability across different domains, and it outperformed several state-of-the-art methods in domain-generalizable segmentation.
Unsupervised Dense Nuclei Detection and Segmentation with Prior Self-activation Map For Histology Images
Oct 14, 2022



The success of supervised deep learning models in medical image segmentation relies on detailed annotations. However, labor-intensive manual labeling is costly and inefficient, especially in dense object segmentation. To this end, we propose a self-supervised learning based approach with a Prior Self-activation Module (PSM) that generates self-activation maps from the input images to avoid labeling costs and further produce pseudo masks for the downstream task. To be specific, we firstly train a neural network using self-supervised learning and utilize the gradient information in the shallow layers of the network to generate self-activation maps. Afterwards, a semantic-guided generator is then introduced as a pipeline to transform visual representations from PSM to pixel-level semantic pseudo masks for downstream tasks. Furthermore, a two-stage training module, consisting of a nuclei detection network and a nuclei segmentation network, is adopted to achieve the final segmentation. Experimental results show the effectiveness on two public pathological datasets. Compared with other fully-supervised and weakly-supervised methods, our method can achieve competitive performance without any manual annotations.
End-to-end cell recognition by point annotation
Jul 01, 2022



Reliable quantitative analysis of immunohistochemical staining images requires accurate and robust cell detection and classification. Recent weakly-supervised methods usually estimate probability density maps for cell recognition. However, in dense cell scenarios, their performance can be limited by pre- and post-processing as it is impossible to find a universal parameter setting. In this paper, we introduce an end-to-end framework that applies direct regression and classification for preset anchor points. Specifically, we propose a pyramidal feature aggregation strategy to combine low-level features and high-level semantics simultaneously, which provides accurate cell recognition for our purely point-based model. In addition, an optimized cost function is designed to adapt our multi-task learning framework by matching ground truth and predicted points. The experimental results demonstrate the superior accuracy and efficiency of the proposed method, which reveals the high potentiality in assisting pathologist assessments.