 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning: A Comprehensive Survey
May 13, 2024As the right to be forgotten has been legislated worldwide, many studies attempt to design unlearning mechanisms to protect users' privacy when they want to leave machine learning service platforms. Specifically, machine unlearning is to make a trained model to remove the contribution of an erased subset of the training dataset. This survey aims to systematically classify a wide range of machine unlearning and discuss their differences, connections and open problems. We categorize current unlearning methods into four scenarios: centralized unlearning, distributed and irregular data unlearning, unlearning verification, and privacy and security issues in unlearning. Since centralized unlearning is the primary domain, we use two parts to introduce: firstly, we classify centralized unlearning into exact unlearning and approximate unlearning; secondly, we offer a detailed introduction to the techniques of these methods. Besides the centralized unlearning, we notice some studies about distributed and irregular data unlearning and introduce federated unlearning and graph unlearning as the two representative directions. After introducing unlearning methods, we review studies about unlearning verification. Moreover, we consider the privacy and security issues essential in machine unlearning and organize the latest related literature. Finally, we discuss the challenges of various unlearning scenarios and address the potential research directions.
Towards Subgraph Isomorphism Counting with Graph Kernels
May 13, 2024Subgraph isomorphism counting is known as #P-complete and requires exponential time to find the accurate solution. Utilizing representation learning has been shown as a promising direction to represent substructures and approximate the solution. Graph kernels that implicitly capture the correlations among substructures in diverse graphs have exhibited great discriminative power in graph classification, so we pioneeringly investigate their potential in counting subgraph isomorphisms and further explore the augmentation of kernel capability through various variants, including polynomial and Gaussian kernels. Through comprehensive analysis, we enhance the graph kernels by incorporating neighborhood information. Finally, we present the results of extensive experiments to demonstrate the effectiveness of the enhanced graph kernels and discuss promising directions for future research.
Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction
Apr 22, 2024The task of condensing large chunks of textual information into concise and structured tables has gained attention recently due to the emergence of Large Language Models (LLMs) and their potential benefit for downstream tasks, such as text summarization and text mining. Previous approaches often generate tables that directly replicate information from the text, limiting their applicability in broader contexts, as text-to-table generation in real-life scenarios necessitates information extraction, reasoning, and integration. However, there is a lack of both datasets and methodologies towards this task. In this paper, we introduce LiveSum, a new benchmark dataset created for generating summary tables of competitions based on real-time commentary texts. We evaluate the performances of state-of-the-art LLMs on this task in both fine-tuning and zero-shot settings, and additionally propose a novel pipeline called $T^3$(Text-Tuple-Table) to improve their performances. Extensive experimental results demonstrate that LLMs still struggle with this task even after fine-tuning, while our approach can offer substantial performance gains without explicit training. Further analyses demonstrate that our method exhibits strong generalization abilities, surpassing previous approaches on several other text-to-table datasets. Our code and data can be found at https://github.com/HKUST-KnowComp/LiveSum-TTT.
NegotiationToM: A Benchmark for Stress-testing Machine Theory of Mind on Negotiation Surrounding
Apr 21, 2024Large Language Models (LLMs) have sparked substantial interest and debate concerning their potential emergence of Theory of Mind (ToM) ability. Theory of mind evaluations currently focuses on testing models using machine-generated data or game settings prone to shortcuts and spurious correlations, which lacks evaluation of machine ToM ability in real-world human interaction scenarios. This poses a pressing demand to develop new real-world scenario benchmarks. We introduce NegotiationToM, a new benchmark designed to stress-test machine ToM in real-world negotiation surrounding covered multi-dimensional mental states (i.e., desires, beliefs, and intentions). Our benchmark builds upon the Belief-Desire-Intention (BDI) agent modeling theory and conducts the necessary empirical experiments to evaluate large language models. Our findings demonstrate that NegotiationToM is challenging for state-of-the-art LLMs, as they consistently perform significantly worse than humans, even when employing the chain-of-thought (CoT) method.
Common 7B Language Models Already Possess Strong Math Capabilities
Mar 07, 2024



Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current base model is the difficulty in consistently eliciting its inherent mathematical capabilities. Notably, the accuracy for the first answer drops to 49.5% and 7.9% on the GSM8K and MATH benchmarks, respectively. We find that simply scaling up the SFT data can significantly enhance the reliability of generating correct answers. However, the potential for extensive scaling is constrained by the scarcity of publicly available math questions. To overcome this limitation, we employ synthetic data, which proves to be nearly as effective as real data and shows no clear saturation when scaled up to approximately one million samples. This straightforward approach achieves an accuracy of 82.6% on GSM8K and 40.6% on MATH using LLaMA-2 7B models, surpassing previous models by 14.2% and 20.8%, respectively. We also provide insights into scaling behaviors across different reasoning complexities and error types.
MIKO: Multimodal Intention Knowledge Distillation from Large Language Models for Social-Media Commonsense Discovery
Feb 29, 2024



Social media has become a ubiquitous tool for connecting with others, staying updated with news, expressing opinions, and finding entertainment. However, understanding the intention behind social media posts remains challenging due to the implicitness of intentions in social media posts, the need for cross-modality understanding of both text and images, and the presence of noisy information such as hashtags, misspelled words, and complicated abbreviations. To address these challenges, we present MIKO, a Multimodal Intention Kowledge DistillatiOn framework that collaboratively leverages a Large Language Model (LLM) and a Multimodal Large Language Model (MLLM) to uncover users' intentions. Specifically, we use an MLLM to interpret the image and an LLM to extract key information from the text and finally instruct the LLM again to generate intentions. By applying MIKO to publicly available social media datasets, we construct an intention knowledge base featuring 1,372K intentions rooted in 137,287 posts. We conduct a two-stage annotation to verify the quality of the generated knowledge and benchmark the performance of widely used LLMs for intention generation. We further apply MIKO to a sarcasm detection dataset and distill a student model to demonstrate the downstream benefits of applying intention knowledge.
EntailE: Introducing Textual Entailment in Commonsense Knowledge Graph Completion
Feb 15, 2024Commonsense knowledge graph completion is a new challenge for commonsense knowledge graph construction and application. In contrast to factual knowledge graphs such as Freebase and YAGO, commonsense knowledge graphs (CSKGs; e.g., ConceptNet) utilize free-form text to represent named entities, short phrases, and events as their nodes. Such a loose structure results in large and sparse CSKGs, which makes the semantic understanding of these nodes more critical for learning rich commonsense knowledge graph embedding. While current methods leverage semantic similarities to increase the graph density, the semantic plausibility of the nodes and their relations are under-explored. Previous works adopt conceptual abstraction to improve the consistency of modeling (event) plausibility, but they are not scalable enough and still suffer from data sparsity. In this paper, we propose to adopt textual entailment to find implicit entailment relations between CSKG nodes, to effectively densify the subgraph connecting nodes within the same conceptual class, which indicates a similar level of plausibility. Each node in CSKG finds its top entailed nodes using a finetuned transformer over natural language inference (NLI) tasks, which sufficiently capture textual entailment signals. The entailment relation between these nodes are further utilized to: 1) build new connections between source triplets and entailed nodes to densify the sparse CSKGs; 2) enrich the generalization ability of node representations by comparing the node embeddings with a contrastive loss. Experiments on two standard CSKGs demonstrate that our proposed framework EntailE can improve the performance of CSKG completion tasks under both transductive and inductive settings.
CANDLE: Iterative Conceptualization and Instantiation Distillation from Large Language Models for Commonsense Reasoning
Jan 14, 2024The sequential process of conceptualization and instantiation is essential to generalizable commonsense reasoning as it allows the application of existing knowledge to unfamiliar scenarios. However, existing works tend to undervalue the step of instantiation and heavily rely on pre-built concept taxonomies and human annotations to collect both types of knowledge, resulting in a lack of instantiated knowledge to complete reasoning, high cost, and limited scalability. To tackle these challenges, we introduce CANDLE, a distillation framework that iteratively performs contextualized conceptualization and instantiation over commonsense knowledge bases by instructing large language models to generate both types of knowledge with critic filtering. By applying CANDLE to ATOMIC, we construct a comprehensive knowledge base comprising six million conceptualizations and instantiated commonsense knowledge triples. Both types of knowledge are firmly rooted in the original ATOMIC dataset, and intrinsic evaluations demonstrate their exceptional quality and diversity. Empirical results indicate that distilling CANDLE on student models provides benefits across four downstream tasks. Our code, data, and models are publicly available at https://github.com/HKUST-KnowComp/CANDLE.
AbsPyramid: Benchmarking the Abstraction Ability of Language Models with a Unified Entailment Graph
Nov 16, 2023Cognitive research indicates that abstraction ability is essential in human intelligence, which remains under-explored in language models. In this paper, we present AbsPyramid, a unified entailment graph of 221K textual descriptions of abstraction knowledge. While existing resources only touch nouns or verbs within simplified events or specific domains, AbsPyramid collects abstract knowledge for three components of diverse events to comprehensively evaluate the abstraction ability of language models in the open domain. Experimental results demonstrate that current LLMs face challenges comprehending abstraction knowledge in zero-shot and few-shot settings. By training on our rich abstraction knowledge, we find LLMs can acquire basic abstraction abilities and generalize to unseen events. In the meantime, we empirically show that our benchmark is comprehensive to enhance LLMs across two previous abstraction tasks.
Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Oct 27, 2023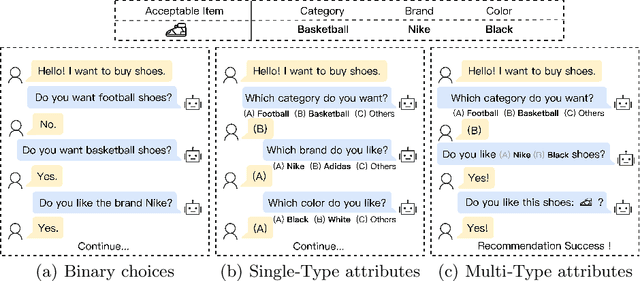
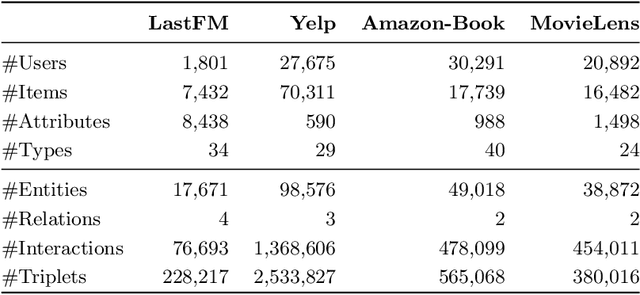
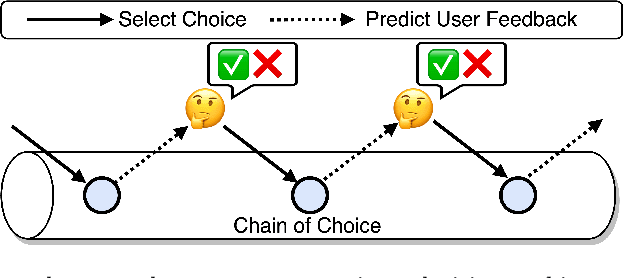
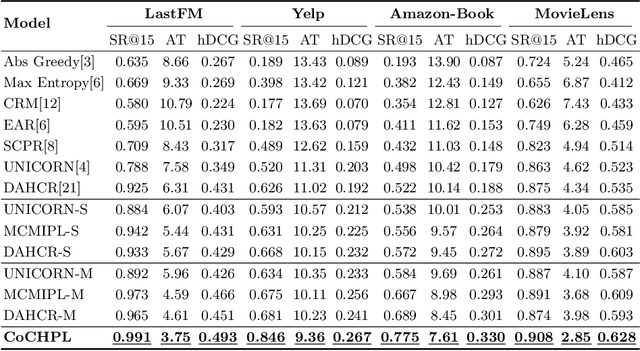
Conversational Recommender Systems (CRS) illuminate user preferences via multi-round interactive dialogues, ultimately navigating towards precise and satisfactory recommendations. However, contemporary CRS are limited to inquiring binary or multi-choice questions based on a single attribute type (e.g., color) per round, which causes excessive rounds of interaction and diminishes the user's experience. To address this, we propose a more realistic and efficient conversational recommendation problem setting, called Multi-Type-Attribute Multi-round Conversational Recommendation (MTAMCR), which enables CRS to inquire about multi-choice questions covering multiple types of attributes in each round, thereby improving interactive efficiency. Moreover, by formulating MTAMCR as a hierarchical reinforcement learning task, we propose a Chain-of-Choice Hierarchical Policy Learning (CoCHPL) framework to enhance both the questioning efficiency and recommendation effectiveness in MTAMCR. Specifically, a long-term policy over options (i.e., ask or recommend) determines the action type, while two short-term intra-option policies sequentially generate the chain of attributes or items through multi-step reasoning and selection, optimizing the diversity and interdependence of questioning attributes. Finally, extensive experiments on four benchmarks demonstrate the superior performance of CoCHPL over prevailing state-of-the-art methods.