 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing User Preferences by Social Networks: A Condition-Guided Social Recommendation Model for Mitigating Popularity Bias
May 27, 2024Social recommendation models weave social interactions into their design to provide uniquely personalized recommendation results for users. However, social networks not only amplify the popularity bias in recommendation models, resulting in more frequent recommendation of hot items and fewer long-tail items, but also include a substantial amount of redundant information that is essentially meaningless for the model's performance. Existing social recommendation models fail to address the issues of popularity bias and the redundancy of social information, as they directly characterize social influence across the entire social network without making targeted adjustments. In this paper, we propose a Condition-Guided Social Recommendation Model (named CGSoRec) to mitigate the model's popularity bias by denoising the social network and adjusting the weights of user's social preferences. More specifically, CGSoRec first includes a Condition-Guided Social Denoising Model (CSD) to remove redundant social relations in the social network for capturing users' social preferences with items more precisely. Then, CGSoRec calculates users' social preferences based on denoised social network and adjusts the weights in users' social preferences to make them can counteract the popularity bias present in the recommendation model. At last, CGSoRec includes a Condition-Guided Diffusion Recommendation Model (CGD) to introduce the adjusted social preferences as conditions to control the recommendation results for a debiased direction. Comprehensive experiments on three real-world datasets demonstrate the effectiveness of our proposed method. The code is in: https://github.com/hexin5515/CGSoRec.
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
May 10, 2024



As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) techniques can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-generated content (AIGC), the powerful capacity of retrieval in RAG in providing additional knowledge enables retrieval-augmented generation to assist existing generative AI in producing high-quality outputs. Recently, large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, retrieval-augmented large language models have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in retrieval-augmented large language models (RA-LLMs), covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we categorize mainstream relevant work by application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research.
Graph Machine Learning in the Era of Large Language Models (LLMs)
Apr 23, 2024Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
Advancing the Robustness of Large Language Models through Self-Denoised Smoothing
Apr 18, 2024Although large language models (LLMs) have achieved significant success, their vulnerability to adversarial perturbations, including recent jailbreak attacks, has raised considerable concerns. However, the increasing size of these models and their limited access make improving their robustness a challenging task. Among various defense strategies, randomized smoothing has shown great potential for LLMs, as it does not require full access to the model's parameters or fine-tuning via adversarial training. However, randomized smoothing involves adding noise to the input before model prediction, and the final model's robustness largely depends on the model's performance on these noise corrupted data. Its effectiveness is often limited by the model's sub-optimal performance on noisy data. To address this issue, we propose to leverage the multitasking nature of LLMs to first denoise the noisy inputs and then to make predictions based on these denoised versions. We call this procedure self-denoised smoothing. Unlike previous denoised smoothing techniques in computer vision, which require training a separate model to enhance the robustness of LLMs, our method offers significantly better efficiency and flexibility. Our experimental results indicate that our method surpasses existing methods in both empirical and certified robustness in defending against adversarial attacks for both downstream tasks and human alignments (i.e., jailbreak attacks). Our code is publicly available at https://github.com/UCSB-NLP-Chang/SelfDenoise
Graph Unlearning with Efficient Partial Retraining
Mar 13, 2024



Graph Neural Networks (GNNs) have achieved remarkable success in various real-world applications. However, GNNs may be trained on undesirable graph data, which can degrade their performance and reliability. To enable trained GNNs to efficiently unlearn unwanted data, a desirable solution is retraining-based graph unlearning, which partitions the training graph into subgraphs and trains sub-models on them, allowing fast unlearning through partial retraining. However, the graph partition process causes information loss in the training graph, resulting in the low model utility of sub-GNN models. In this paper, we propose GraphRevoker, a novel graph unlearning framework that better maintains the model utility of unlearnable GNNs. Specifically, we preserve the graph property with graph property-aware sharding and effectively aggregate the sub-GNN models for prediction with graph contrastive sub-model aggregation. We conduct extensive experiments to demonstrate the superiority of our proposed approach.
FashionReGen: LLM-Empowered Fashion Report Generation
Mar 11, 2024

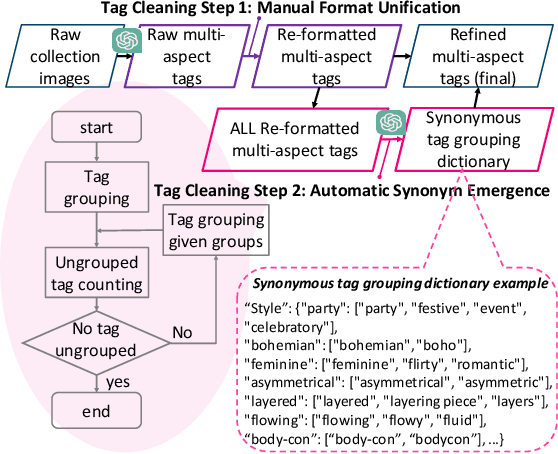
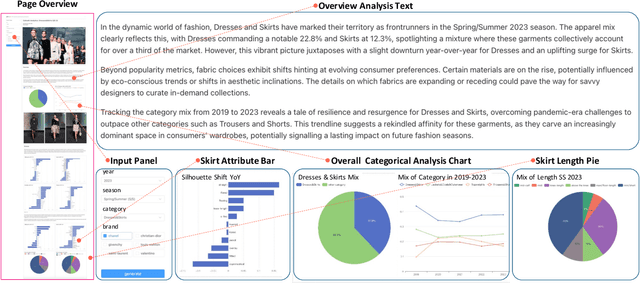
Fashion analysis refers to the process of examining and evaluating trends, styles, and elements within the fashion industry to understand and interpret its current state, generating fashion reports. It is traditionally performed by fashion professionals based on their expertise and experience, which requires high labour cost and may also produce biased results for relying heavily on a small group of people. In this paper, to tackle the Fashion Report Generation (FashionReGen) task, we propose an intelligent Fashion Analyzing and Reporting system based the advanced Large Language Models (LLMs), debbed as GPT-FAR. Specifically, it tries to deliver FashionReGen based on effective catwalk analysis, which is equipped with several key procedures, namely, catwalk understanding, collective organization and analysis, and report generation. By posing and exploring such an open-ended, complex and domain-specific task of FashionReGen, it is able to test the general capability of LLMs in fashion domain. It also inspires the explorations of more high-level tasks with industrial significance in other domains. Video illustration and more materials of GPT-FAR can be found in https://github.com/CompFashion/FashionReGen.
Large Language Models are In-Context Molecule Learners
Mar 07, 2024



Large Language Models (LLMs) have demonstrated exceptional performance in biochemical tasks, especially the molecule caption translation task, which aims to bridge the gap between molecules and natural language texts. However, previous methods in adapting LLMs to the molecule-caption translation task required extra domain-specific pre-training stages, suffered weak alignment between molecular and textual spaces, or imposed stringent demands on the scale of LLMs. To resolve the challenges, we propose In-Context Molecule Adaptation (ICMA), as a new paradigm allowing LLMs to learn the molecule-text alignment from context examples via In-Context Molecule Tuning. Specifically, ICMA incorporates the following three stages: Cross-modal Retrieval, Post-retrieval Re-ranking, and In-context Molecule Tuning. Initially, Cross-modal Retrieval utilizes BM25 Caption Retrieval and Molecule Graph Retrieval to retrieve informative context examples. Additionally, we also propose Post-retrieval Re-ranking with Sequence Reversal and Random Walk to further improve the quality of retrieval results. Finally, In-Context Molecule Tuning unlocks the in-context molecule learning capability of LLMs with retrieved examples and adapts the parameters of LLMs for the molecule-caption translation task. Experimental results demonstrate that ICMT can empower LLMs to achieve state-of-the-art or comparable performance without extra training corpora and intricate structures, showing that LLMs are inherently in-context molecule learners.
Linear-Time Graph Neural Networks for Scalable Recommendations
Feb 21, 2024In an era of information explosion, recommender systems are vital tools to deliver personalized recommendations for users. The key of recommender systems is to forecast users' future behaviors based on previous user-item interactions. Due to their strong expressive power of capturing high-order connectivities in user-item interaction data, recent years have witnessed a rising interest in leveraging Graph Neural Networks (GNNs) to boost the prediction performance of recommender systems. Nonetheless, classic Matrix Factorization (MF) and Deep Neural Network (DNN) approaches still play an important role in real-world large-scale recommender systems due to their scalability advantages. Despite the existence of GNN-acceleration solutions, it remains an open question whether GNN-based recommender systems can scale as efficiently as classic MF and DNN methods. In this paper, we propose a Linear-Time Graph Neural Network (LTGNN) to scale up GNN-based recommender systems to achieve comparable scalability as classic MF approaches while maintaining GNNs' powerful expressiveness for superior prediction accuracy. Extensive experiments and ablation studies are presented to validate the effectiveness and scalability of the proposed algorithm. Our implementation based on PyTorch is available.
Rethinking Large Language Model Architectures for Sequential Recommendations
Feb 14, 2024Recently, sequential recommendation has been adapted to the LLM paradigm to enjoy the power of LLMs. LLM-based methods usually formulate recommendation information into natural language and the model is trained to predict the next item in an auto-regressive manner. Despite their notable success, the substantial computational overhead of inference poses a significant obstacle to their real-world applicability. In this work, we endeavor to streamline existing LLM-based recommendation models and propose a simple yet highly effective model Lite-LLM4Rec. The primary goal of Lite-LLM4Rec is to achieve efficient inference for the sequential recommendation task. Lite-LLM4Rec circumvents the beam search decoding by using a straight item projection head for ranking scores generation. This design stems from our empirical observation that beam search decoding is ultimately unnecessary for sequential recommendations. Additionally, Lite-LLM4Rec introduces a hierarchical LLM structure tailored to efficiently handle the extensive contextual information associated with items, thereby reducing computational overhead while enjoying the capabilities of LLMs. Experiments on three publicly available datasets corroborate the effectiveness of Lite-LLM4Rec in both performance and inference efficiency (notably 46.8% performance improvement and 97.28% efficiency improvement on ML-1m) over existing LLM-based methods. Our implementations will be open sourced.
A Comprehensive Survey on Graph Reduction: Sparsification, Coarsening, and Condensation
Feb 07, 2024Many real-world datasets can be naturally represented as graphs, spanning a wide range of domains. However, the increasing complexity and size of graph datasets present significant challenges for analysis and computation. In response, graph reduction techniques have gained prominence for simplifying large graphs while preserving essential properties. In this survey, we aim to provide a comprehensive understanding of graph reduction methods, including graph sparsification, graph coarsening, and graph condensation. Specifically, we establish a unified definition for these methods and introduce a hierarchical taxonomy to categorize the challenges they address. Our survey then systematically reviews the technical details of these methods and emphasizes their practical applications across diverse scenarios. Furthermore, we outline critical research directions to ensure the continued effectiveness of graph reduction techniques, as well as provide a comprehensive paper list at https://github.com/ChandlerBang/awesome-graph-reduction. We hope this survey will bridge literature gaps and propel the advancement of this promising field.