 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIB-AdCSCNet:Adaptive Convolutional Sparse Coding Network Driven by Information Bottleneck
May 23, 2024In the realm of neural network models, the perpetual challenge remains in retaining task-relevant information while effectively discarding redundant data during propagation. In this paper, we introduce IB-AdCSCNet, a deep learning model grounded in information bottleneck theory. IB-AdCSCNet seamlessly integrates the information bottleneck trade-off strategy into deep networks by dynamically adjusting the trade-off hyperparameter $\lambda$ through gradient descent, updating it within the FISTA(Fast Iterative Shrinkage-Thresholding Algorithm ) framework. By optimizing the compressive excitation loss function induced by the information bottleneck principle, IB-AdCSCNet achieves an optimal balance between compression and fitting at a global level, approximating the globally optimal representation feature. This information bottleneck trade-off strategy driven by downstream tasks not only helps to learn effective features of the data, but also improves the generalization of the model. This study's contribution lies in presenting a model with consistent performance and offering a fresh perspective on merging deep learning with sparse representation theory, grounded in the information bottleneck concept. Experimental results on CIFAR-10 and CIFAR-100 datasets demonstrate that IB-AdCSCNet not only matches the performance of deep residual convolutional networks but also outperforms them when handling corrupted data. Through the inference of the IB trade-off, the model's robustness is notably enhanced.
A Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
May 17, 2024The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
Densely Distilling Cumulative Knowledge for Continual Learning
May 16, 2024Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.
An Image Quality Evaluation and Masking Algorithm Based On Pre-trained Deep Neural Networks
May 06, 2024With the growing amount of astronomical data, there is an increasing need for automated data processing pipelines, which can extract scientific information from observation data without human interventions. A critical aspect of these pipelines is the image quality evaluation and masking algorithm, which evaluates image qualities based on various factors such as cloud coverage, sky brightness, scattering light from the optical system, point spread function size and shape, and read-out noise. Occasionally, the algorithm requires masking of areas severely affected by noise. However, the algorithm often necessitates significant human interventions, reducing data processing efficiency. In this study, we present a deep learning based image quality evaluation algorithm that uses an autoencoder to learn features of high quality astronomical images. The trained autoencoder enables automatic evaluation of image quality and masking of noise affected areas. We have evaluated the performance of our algorithm using two test cases: images with point spread functions of varying full width half magnitude, and images with complex backgrounds. In the first scenario, our algorithm could effectively identify variations of the point spread functions, which can provide valuable reference information for photometry. In the second scenario, our method could successfully mask regions affected by complex regions, which could significantly increase the photometry accuracy. Our algorithm can be employed to automatically evaluate image quality obtained by different sky surveying projects, further increasing the speed and robustness of data processing pipelines.
Graph Machine Learning in the Era of Large Language Models (LLMs)
Apr 23, 2024Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
MEDPNet: Achieving High-Precision Adaptive Registration for Complex Die Castings
Mar 15, 2024
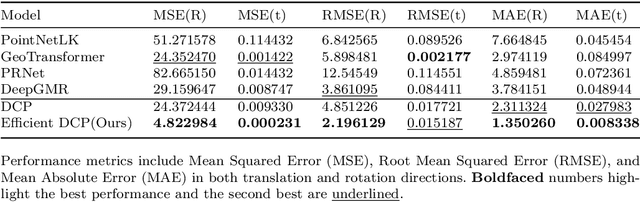
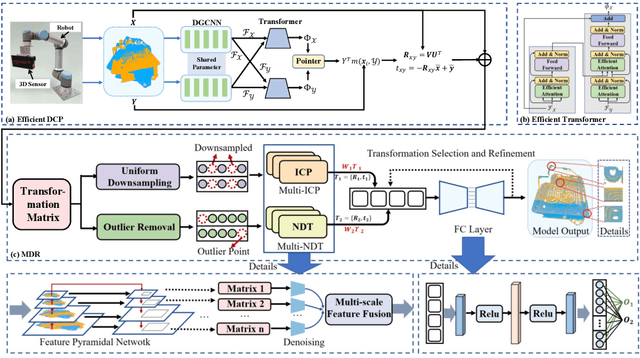
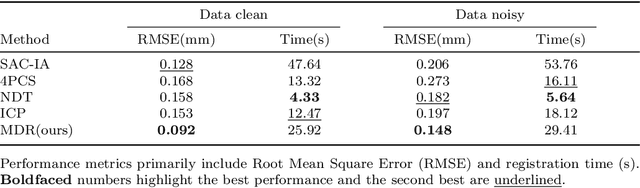
Due to their complex spatial structure and diverse geometric features, achieving high-precision and robust point cloud registration for complex Die Castings has been a significant challenge in the die-casting industry. Existing point cloud registration methods primarily optimize network models using well-established high-quality datasets, often neglecting practical application in real scenarios. To address this gap, this paper proposes a high-precision adaptive registration method called Multiscale Efficient Deep Closest Point (MEDPNet) and introduces a die-casting point cloud dataset, DieCastCloud, specifically designed to tackle the challenges of point cloud registration in the die-casting industry. The MEDPNet method performs coarse die-casting point cloud data registration using the Efficient-DCP method, followed by precision registration using the Multiscale feature fusion dual-channel registration (MDR) method. We enhance the modeling capability and computational efficiency of the model by replacing the attention mechanism of the Transformer in DCP with Efficient Attention and implementing a collaborative scale mechanism through the combination of serial and parallel blocks. Additionally, we propose the MDR method, which utilizes multilayer perceptrons (MLP), Normal Distributions Transform (NDT), and Iterative Closest Point (ICP) to achieve learnable adaptive fusion, enabling high-precision, scalable, and noise-resistant global point cloud registration. Our proposed method demonstrates excellent performance compared to state-of-the-art geometric and learning-based registration methods when applied to complex die-casting point cloud data.
Image Restoration with Point Spread Function Regularization and Active Learning
Oct 31, 2023Large-scale astronomical surveys can capture numerous images of celestial objects, including galaxies and nebulae. Analysing and processing these images can reveal intricate internal structures of these objects, allowing researchers to conduct comprehensive studies on their morphology, evolution, and physical properties. However, varying noise levels and point spread functions can hamper the accuracy and efficiency of information extraction from these images. To mitigate these effects, we propose a novel image restoration algorithm that connects a deep learning-based restoration algorithm with a high-fidelity telescope simulator. During the training stage, the simulator generates images with different levels of blur and noise to train the neural network based on the quality of restored images. After training, the neural network can directly restore images obtained by the telescope, as represented by the simulator. We have tested the algorithm using real and simulated observation data and have found that it effectively enhances fine structures in blurry images and increases the quality of observation images. This algorithm can be applied to large-scale sky survey data, such as data obtained by LSST, Euclid, and CSST, to further improve the accuracy and efficiency of information extraction, promoting advances in the field of astronomical research.
HoneyBee: Progressive Instruction Finetuning of Large Language Models for Materials Science
Oct 12, 2023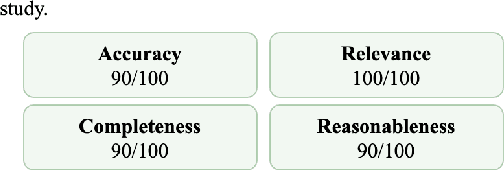

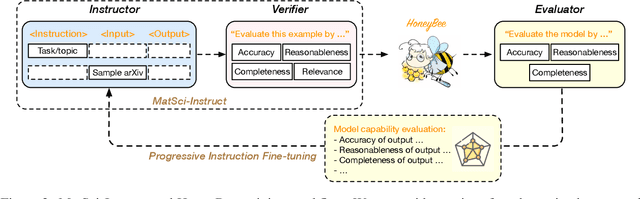
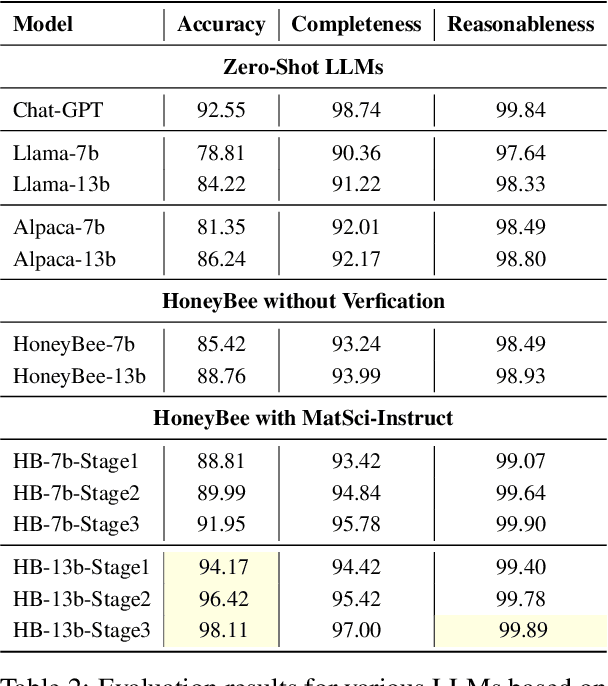
We propose an instruction-based process for trustworthy data curation in materials science (MatSci-Instruct), which we then apply to finetune a LLaMa-based language model targeted for materials science (HoneyBee). MatSci-Instruct helps alleviate the scarcity of relevant, high-quality materials science textual data available in the open literature, and HoneyBee is the first billion-parameter language model specialized to materials science. In MatSci-Instruct we improve the trustworthiness of generated data by prompting multiple commercially available large language models for generation with an Instructor module (e.g. Chat-GPT) and verification from an independent Verifier module (e.g. Claude). Using MatSci-Instruct, we construct a dataset of multiple tasks and measure the quality of our dataset along multiple dimensions, including accuracy against known facts, relevance to materials science, as well as completeness and reasonableness of the data. Moreover, we iteratively generate more targeted instructions and instruction-data in a finetuning-evaluation-feedback loop leading to progressively better performance for our finetuned HoneyBee models. Our evaluation on the MatSci-NLP benchmark shows HoneyBee's outperformance of existing language models on materials science tasks and iterative improvement in successive stages of instruction-data refinement. We study the quality of HoneyBee's language modeling through automatic evaluation and analyze case studies to further understand the model's capabilities and limitations. Our code and relevant datasets are publicly available at \url{https://github.com/BangLab-UdeM-Mila/NLP4MatSci-HoneyBee}.
Learning on Graphs with Out-of-Distribution Nodes
Aug 13, 2023Graph Neural Networks (GNNs) are state-of-the-art models for performing prediction tasks on graphs. While existing GNNs have shown great performance on various tasks related to graphs, little attention has been paid to the scenario where out-of-distribution (OOD) nodes exist in the graph during training and inference. Borrowing the concept from CV and NLP, we define OOD nodes as nodes with labels unseen from the training set. Since a lot of networks are automatically constructed by programs, real-world graphs are often noisy and may contain nodes from unknown distributions. In this work, we define the problem of graph learning with out-of-distribution nodes. Specifically, we aim to accomplish two tasks: 1) detect nodes which do not belong to the known distribution and 2) classify the remaining nodes to be one of the known classes. We demonstrate that the connection patterns in graphs are informative for outlier detection, and propose Out-of-Distribution Graph Attention Network (OODGAT), a novel GNN model which explicitly models the interaction between different kinds of nodes and separate inliers from outliers during feature propagation. Extensive experiments show that OODGAT outperforms existing outlier detection methods by a large margin, while being better or comparable in terms of in-distribution classification.
4D Feet: Registering Walking Foot Shapes Using Attention Enhanced Dynamic-Synchronized Graph Convolutional LSTM Network
Jul 23, 2023
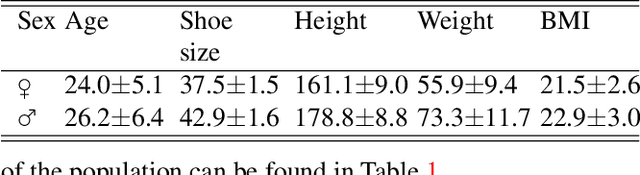
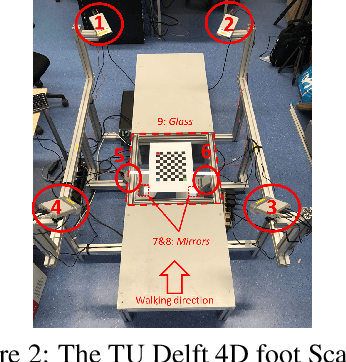

4D scans of dynamic deformable human body parts help researchers have a better understanding of spatiotemporal features. However, reconstructing 4D scans based on multiple asynchronous cameras encounters two main challenges: 1) finding the dynamic correspondences among different frames captured by each camera at the timestamps of the camera in terms of dynamic feature recognition, and 2) reconstructing 3D shapes from the combined point clouds captured by different cameras at asynchronous timestamps in terms of multi-view fusion. In this paper, we introduce a generic framework that is able to 1) find and align dynamic features in the 3D scans captured by each camera using the nonrigid iterative closest-farthest points algorithm; 2) synchronize scans captured by asynchronous cameras through a novel ADGC-LSTM-based network, which is capable of aligning 3D scans captured by different cameras to the timeline of a specific camera; and 3) register a high-quality template to synchronized scans at each timestamp to form a high-quality 3D mesh model using a non-rigid registration method. With a newly developed 4D foot scanner, we validate the framework and create the first open-access data-set, namely the 4D feet. It includes 4D shapes (15 fps) of the right and left feet of 58 participants (116 feet in total, including 5147 3D frames), covering significant phases of the gait cycle. The results demonstrate the effectiveness of the proposed framework, especially in synchronizing asynchronous 4D scans using the proposed ADGC-LSTM network.