 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Clinical Guidelines through Adapting Multi-modal Large Language Model for Prostate Cancer PI-RADS Scoring
May 14, 2024The Prostate Imaging Reporting and Data System (PI-RADS) is pivotal in the diagnosis of clinically significant prostate cancer through MRI imaging. Current deep learning-based PI-RADS scoring methods often lack the incorporation of essential PI-RADS clinical guidelines~(PICG) utilized by radiologists, potentially compromising scoring accuracy. This paper introduces a novel approach that adapts a multi-modal large language model (MLLM) to incorporate PICG into PI-RADS scoring without additional annotations and network parameters. We present a two-stage fine-tuning process aimed at adapting MLLMs originally trained on natural images to the MRI data domain while effectively integrating the PICG. In the first stage, we develop a domain adapter layer specifically tailored for processing 3D MRI image inputs and design the MLLM instructions to differentiate MRI modalities effectively. In the second stage, we translate PICG into guiding instructions for the model to generate PICG-guided image features. Through feature distillation, we align scoring network features with the PICG-guided image feature, enabling the scoring network to effectively incorporate the PICG information. We develop our model on a public dataset and evaluate it in a real-world challenging in-house dataset. Experimental results demonstrate that our approach improves the performance of current scoring networks.
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Apr 27, 2024Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new \textit{Distill-Retrieve-Read} framework instead of the previous \textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Grounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
CT Synthesis with Conditional Diffusion Models for Abdominal Lymph Node Segmentation
Mar 26, 2024



Despite the significant success achieved by deep learning methods in medical image segmentation, researchers still struggle in the computer-aided diagnosis of abdominal lymph nodes due to the complex abdominal environment, small and indistinguishable lesions, and limited annotated data. To address these problems, we present a pipeline that integrates the conditional diffusion model for lymph node generation and the nnU-Net model for lymph node segmentation to improve the segmentation performance of abdominal lymph nodes through synthesizing a diversity of realistic abdominal lymph node data. We propose LN-DDPM, a conditional denoising diffusion probabilistic model (DDPM) for lymph node (LN) generation. LN-DDPM utilizes lymph node masks and anatomical structure masks as model conditions. These conditions work in two conditioning mechanisms: global structure conditioning and local detail conditioning, to distinguish between lymph nodes and their surroundings and better capture lymph node characteristics. The obtained paired abdominal lymph node images and masks are used for the downstream segmentation task. Experimental results on the abdominal lymph node datasets demonstrate that LN-DDPM outperforms other generative methods in the abdominal lymph node image synthesis and better assists the downstream abdominal lymph node segmentation task.
PathoTune: Adapting Visual Foundation Model to Pathological Specialists
Mar 25, 2024As natural image understanding moves towards the pretrain-finetune era, research in pathology imaging is concurrently evolving. Despite the predominant focus on pretraining pathological foundation models, how to adapt foundation models to downstream tasks is little explored. For downstream adaptation, we propose the existence of two domain gaps, i.e., the Foundation-Task Gap and the Task-Instance Gap. To mitigate these gaps, we introduce PathoTune, a framework designed to efficiently adapt pathological or even visual foundation models to pathology-specific tasks via multi-modal prompt tuning. The proposed framework leverages Task-specific Visual Prompts and Task-specific Textual Prompts to identify task-relevant features, along with Instance-specific Visual Prompts for encoding single pathological image features. Results across multiple datasets at both patch-level and WSI-level demonstrate its superior performance over single-modality prompt tuning approaches. Significantly, PathoTune facilitates the direct adaptation of natural visual foundation models to pathological tasks, drastically outperforming pathological foundation models with simple linear probing. The code will be available upon acceptance.
VLM-CPL: Consensus Pseudo Labels from Vision-Language Models for Human Annotation-Free Pathological Image Classification
Mar 23, 2024Despite that deep learning methods have achieved remarkable performance in pathology image classification, they heavily rely on labeled data, demanding extensive human annotation efforts. In this study, we present a novel human annotation-free method for pathology image classification by leveraging pre-trained Vision-Language Models (VLMs). Without human annotation, pseudo labels of the training set are obtained by utilizing the zero-shot inference capabilities of VLM, which may contain a lot of noise due to the domain shift between the pre-training data and the target dataset. To address this issue, we introduce VLM-CPL, a novel approach based on consensus pseudo labels that integrates two noisy label filtering techniques with a semi-supervised learning strategy. Specifically, we first obtain prompt-based pseudo labels with uncertainty estimation by zero-shot inference with the VLM using multiple augmented views of an input. Then, by leveraging the feature representation ability of VLM, we obtain feature-based pseudo labels via sample clustering in the feature space. Prompt-feature consensus is introduced to select reliable samples based on the consensus between the two types of pseudo labels. By rejecting low-quality pseudo labels, we further propose High-confidence Cross Supervision (HCS) to learn from samples with reliable pseudo labels and the remaining unlabeled samples. Experimental results showed that our method obtained an accuracy of 87.1% and 95.1% on the HPH and LC25K datasets, respectively, and it largely outperformed existing zero-shot classification and noisy label learning methods. The code is available at https://github.com/lanfz2000/VLM-CPL.
GuideGen: A Text-guided Framework for Joint CT Volume and Anatomical structure Generation
Mar 12, 2024



The annotation burden and extensive labor for gathering a large medical dataset with images and corresponding labels are rarely cost-effective and highly intimidating. This results in a lack of abundant training data that undermines downstream tasks and partially contributes to the challenge image analysis faces in the medical field. As a workaround, given the recent success of generative neural models, it is now possible to synthesize image datasets at a high fidelity guided by external constraints. This paper explores this possibility and presents \textbf{GuideGen}: a pipeline that jointly generates CT images and tissue masks for abdominal organs and colorectal cancer conditioned on a text prompt. Firstly, we introduce Volumetric Mask Sampler to fit the discrete distribution of mask labels and generate low-resolution 3D tissue masks. Secondly, our Conditional Image Generator autoregressively generates CT slices conditioned on a corresponding mask slice to incorporate both style information and anatomical guidance. This pipeline guarantees high fidelity and variability as well as exact alignment between generated CT volumes and tissue masks. Both qualitative and quantitative experiments on 3D abdominal CTs demonstrate a high performance of our proposed pipeline, thereby proving our method can serve as a dataset generator and provide potential benefits to downstream tasks. It is hoped that our work will offer a promising solution on the multimodality generation of CT and its anatomical mask. Our source code is publicly available at https://github.com/OvO1111/JointImageGeneration.
OpenMEDLab: An Open-source Platform for Multi-modality Foundation Models in Medicine
Mar 04, 2024
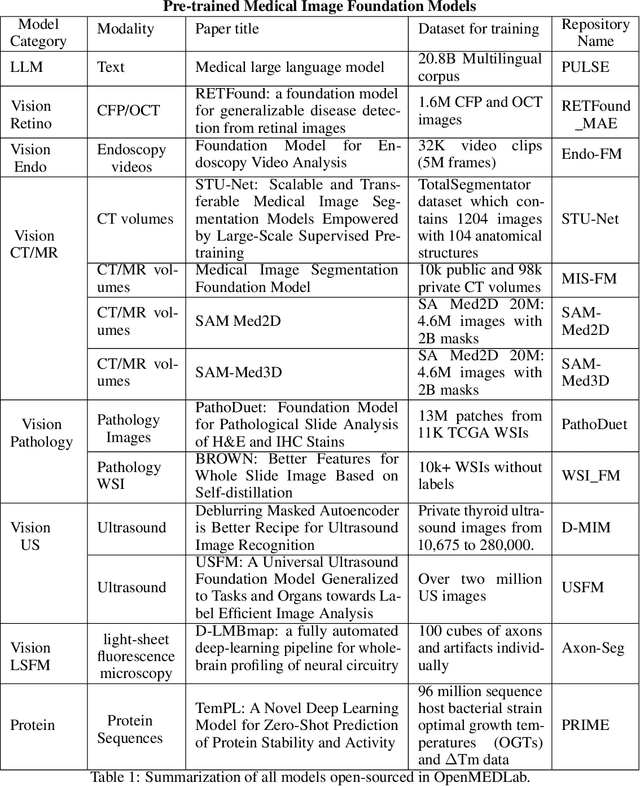
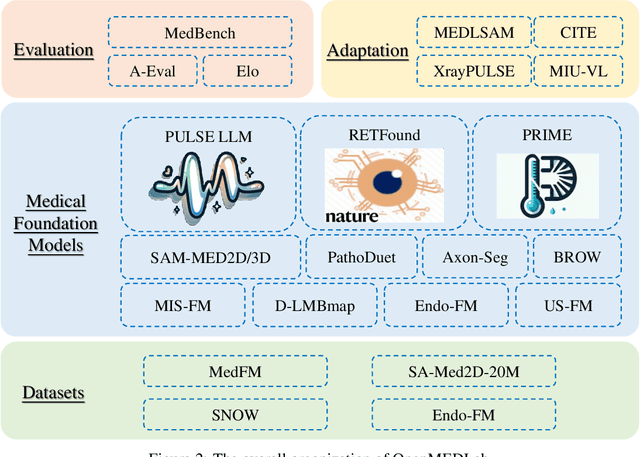
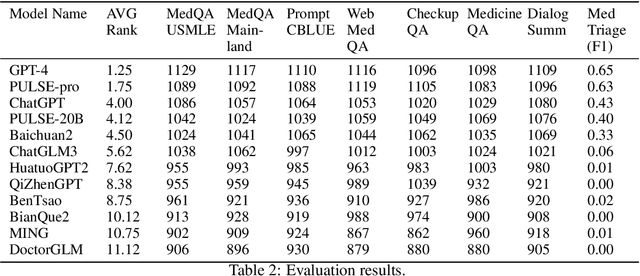
The emerging trend of advancing generalist artificial intelligence, such as GPTv4 and Gemini, has reshaped the landscape of research (academia and industry) in machine learning and many other research areas. However, domain-specific applications of such foundation models (e.g., in medicine) remain untouched or often at their very early stages. It will require an individual set of transfer learning and model adaptation techniques by further expanding and injecting these models with domain knowledge and data. The development of such technologies could be largely accelerated if the bundle of data, algorithms, and pre-trained foundation models were gathered together and open-sourced in an organized manner. In this work, we present OpenMEDLab, an open-source platform for multi-modality foundation models. It encapsulates not only solutions of pioneering attempts in prompting and fine-tuning large language and vision models for frontline clinical and bioinformatic applications but also building domain-specific foundation models with large-scale multi-modal medical data. Importantly, it opens access to a group of pre-trained foundation models for various medical image modalities, clinical text, protein engineering, etc. Inspiring and competitive results are also demonstrated for each collected approach and model in a variety of benchmarks for downstream tasks. We welcome researchers in the field of medical artificial intelligence to continuously contribute cutting-edge methods and models to OpenMEDLab, which can be accessed via https://github.com/openmedlab.
Modality-Aware and Shift Mixer for Multi-modal Brain Tumor Segmentation
Mar 04, 2024
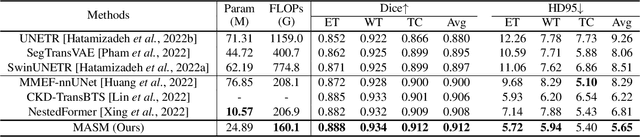
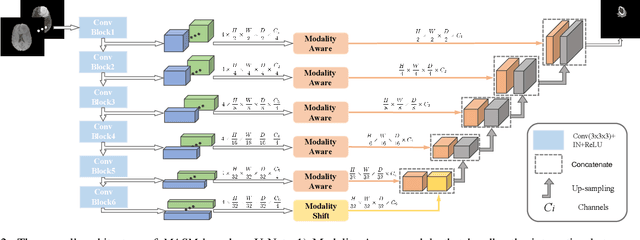
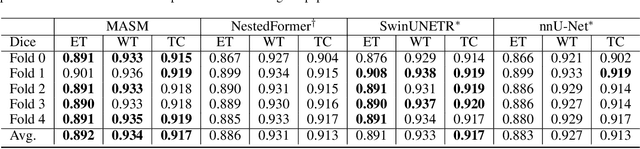
Combining images from multi-modalities is beneficial to explore various information in computer vision, especially in the medical domain. As an essential part of clinical diagnosis, multi-modal brain tumor segmentation aims to delineate the malignant entity involving multiple modalities. Although existing methods have shown remarkable performance in the task, the information exchange for cross-scale and high-level representations fusion in spatial and modality are limited in these methods. In this paper, we present a novel Modality Aware and Shift Mixer that integrates intra-modality and inter-modality dependencies of multi-modal images for effective and robust brain tumor segmentation. Specifically, we introduce a Modality-Aware module according to neuroimaging studies for modeling the specific modality pair relationships at low levels, and a Modality-Shift module with specific mosaic patterns is developed to explore the complex relationships across modalities at high levels via the self-attention. Experimentally, we outperform previous state-of-the-art approaches on the public Brain Tumor Segmentation (BraTS 2021 segmentation) dataset. Further qualitative experiments demonstrate the efficacy and robustness of MASM.
USFM: A Universal Ultrasound Foundation Model Generalized to Tasks and Organs towards Label Efficient Image Analysis
Jan 02, 2024Inadequate generality across different organs and tasks constrains the application of ultrasound (US) image analysis methods in smart healthcare. Building a universal US foundation model holds the potential to address these issues. Nevertheless, the development of such foundational models encounters intrinsic challenges in US analysis, i.e., insufficient databases, low quality, and ineffective features. In this paper, we present a universal US foundation model, named USFM, generalized to diverse tasks and organs towards label efficient US image analysis. First, a large-scale Multi-organ, Multi-center, and Multi-device US database was built, comprehensively containing over two million US images. Organ-balanced sampling was employed for unbiased learning. Then, USFM is self-supervised pre-trained on the sufficient US database. To extract the effective features from low-quality US images, we proposed a spatial-frequency dual masked image modeling method. A productive spatial noise addition-recovery approach was designed to learn meaningful US information robustly, while a novel frequency band-stop masking learning approach was also employed to extract complex, implicit grayscale distribution and textural variations. Extensive experiments were conducted on the various tasks of segmentation, classification, and image enhancement from diverse organs and diseases. Comparisons with representative US image analysis models illustrate the universality and effectiveness of USFM. The label efficiency experiments suggest the USFM obtains robust performance with only 20% annotation, laying the groundwork for the rapid development of US models in clinical practices.