 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Segment Anything on the Fly: Auxiliary Online Learning and Adaptive Fusion for Medical Image Segmentation
Jun 03, 2024The current variants of the Segment Anything Model (SAM), which include the original SAM and Medical SAM, still lack the capability to produce sufficiently accurate segmentation for medical images. In medical imaging contexts, it is not uncommon for human experts to rectify segmentations of specific test samples after SAM generates its segmentation predictions. These rectifications typically entail manual or semi-manual corrections employing state-of-the-art annotation tools. Motivated by this process, we introduce a novel approach that leverages the advantages of online machine learning to enhance Segment Anything (SA) during test time. We employ rectified annotations to perform online learning, with the aim of improving the segmentation quality of SA on medical images. To improve the effectiveness and efficiency of online learning when integrated with large-scale vision models like SAM, we propose a new method called Auxiliary Online Learning (AuxOL). AuxOL creates and applies a small auxiliary model (specialist) in conjunction with SAM (generalist), entails adaptive online-batch and adaptive segmentation fusion. Experiments conducted on eight datasets covering four medical imaging modalities validate the effectiveness of the proposed method. Our work proposes and validates a new, practical, and effective approach for enhancing SA on downstream segmentation tasks (e.g., medical image segmentation).
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
May 29, 2024Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~\cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
Deform3DGS: Flexible Deformation for Fast Surgical Scene Reconstruction with Gaussian Splatting
May 29, 2024Tissue deformation poses a key challenge for accurate surgical scene reconstruction. Despite yielding high reconstruction quality, existing methods suffer from slow rendering speeds and long training times, limiting their intraoperative applicability. Motivated by recent progress in 3D Gaussian Splatting, an emerging technology in real-time 3D rendering, this work presents a novel fast reconstruction framework, termed Deform3DGS, for deformable tissues during endoscopic surgery. Specifically, we introduce 3D GS into surgical scenes by integrating a point cloud initialization to improve reconstruction. Furthermore, we propose a novel flexible deformation modeling scheme (FDM) to learn tissue deformation dynamics at the level of individual Gaussians. Our FDM can model the surface deformation with efficient representations, allowing for real-time rendering performance. More importantly, FDM significantly accelerates surgical scene reconstruction, demonstrating considerable clinical values, particularly in intraoperative settings where time efficiency is crucial. Experiments on DaVinci robotic surgery videos indicate the efficacy of our approach, showcasing superior reconstruction fidelity PSNR: (37.90) and rendering speed (338.8 FPS) while substantially reducing training time to only 1 minute/scene.
Incorporating Clinical Guidelines through Adapting Multi-modal Large Language Model for Prostate Cancer PI-RADS Scoring
May 14, 2024The Prostate Imaging Reporting and Data System (PI-RADS) is pivotal in the diagnosis of clinically significant prostate cancer through MRI imaging. Current deep learning-based PI-RADS scoring methods often lack the incorporation of essential PI-RADS clinical guidelines~(PICG) utilized by radiologists, potentially compromising scoring accuracy. This paper introduces a novel approach that adapts a multi-modal large language model (MLLM) to incorporate PICG into PI-RADS scoring without additional annotations and network parameters. We present a two-stage fine-tuning process aimed at adapting MLLMs originally trained on natural images to the MRI data domain while effectively integrating the PICG. In the first stage, we develop a domain adapter layer specifically tailored for processing 3D MRI image inputs and design the MLLM instructions to differentiate MRI modalities effectively. In the second stage, we translate PICG into guiding instructions for the model to generate PICG-guided image features. Through feature distillation, we align scoring network features with the PICG-guided image feature, enabling the scoring network to effectively incorporate the PICG information. We develop our model on a public dataset and evaluate it in a real-world challenging in-house dataset. Experimental results demonstrate that our approach improves the performance of current scoring networks.
Efficient Data-driven Scene Simulation using Robotic Surgery Videos via Physics-embedded 3D Gaussians
May 02, 2024Surgical scene simulation plays a crucial role in surgical education and simulator-based robot learning. Traditional approaches for creating these environments with surgical scene involve a labor-intensive process where designers hand-craft tissues models with textures and geometries for soft body simulations. This manual approach is not only time-consuming but also limited in the scalability and realism. In contrast, data-driven simulation offers a compelling alternative. It has the potential to automatically reconstruct 3D surgical scenes from real-world surgical video data, followed by the application of soft body physics. This area, however, is relatively uncharted. In our research, we introduce 3D Gaussian as a learnable representation for surgical scene, which is learned from stereo endoscopic video. To prevent over-fitting and ensure the geometrical correctness of these scenes, we incorporate depth supervision and anisotropy regularization into the Gaussian learning process. Furthermore, we apply the Material Point Method, which is integrated with physical properties, to the 3D Gaussians to achieve realistic scene deformations. Our method was evaluated on our collected in-house and public surgical videos datasets. Results show that it can reconstruct and simulate surgical scenes from endoscopic videos efficiently-taking only a few minutes to reconstruct the surgical scene-and produce both visually and physically plausible deformations at a speed approaching real-time. The results demonstrate great potential of our proposed method to enhance the efficiency and variety of simulations available for surgical education and robot learning.
Simultaneous Estimation of Shape and Force along Highly Deformable Surgical Manipulators Using Sparse FBG Measurement
Apr 25, 2024Recently, fiber optic sensors such as fiber Bragg gratings (FBGs) have been widely investigated for shape reconstruction and force estimation of flexible surgical robots. However, most existing approaches need precise model parameters of FBGs inside the fiber and their alignments with the flexible robots for accurate sensing results. Another challenge lies in online acquiring external forces at arbitrary locations along the flexible robots, which is highly required when with large deflections in robotic surgery. In this paper, we propose a novel data-driven paradigm for simultaneous estimation of shape and force along highly deformable flexible robots by using sparse strain measurement from a single-core FBG fiber. A thin-walled soft sensing tube helically embedded with FBG sensors is designed for a robotic-assisted flexible ureteroscope with large deflection up to 270 degrees and a bend radius under 10 mm. We introduce and study three learning models by incorporating spatial strain encoders, and compare their performances in both free space and constrained environments with contact forces at different locations. The experimental results in terms of dynamic shape-force sensing accuracy demonstrate the effectiveness and superiority of the proposed methods.
Grounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
Structured Gradient-based Interpretations via Norm-Regularized Adversarial Training
Apr 06, 2024



Gradient-based saliency maps have been widely used to explain the decisions of deep neural network classifiers. However, standard gradient-based interpretation maps, including the simple gradient and integrated gradient algorithms, often lack desired structures such as sparsity and connectedness in their application to real-world computer vision models. A frequently used approach to inducing sparsity structures into gradient-based saliency maps is to alter the simple gradient scheme using sparsification or norm-based regularization. A drawback with such post-processing methods is their frequently-observed significant loss in fidelity to the original simple gradient map. In this work, we propose to apply adversarial training as an in-processing scheme to train neural networks with structured simple gradient maps. We show a duality relation between the regularized norms of the adversarial perturbations and gradient-based maps, based on which we design adversarial training loss functions promoting sparsity and group-sparsity properties in simple gradient maps. We present several numerical results to show the influence of our proposed norm-based adversarial training methods on the standard gradient-based maps of standard neural network architectures on benchmark image datasets.
EndoGSLAM: Real-Time Dense Reconstruction and Tracking in Endoscopic Surgeries using Gaussian Splatting
Mar 22, 2024

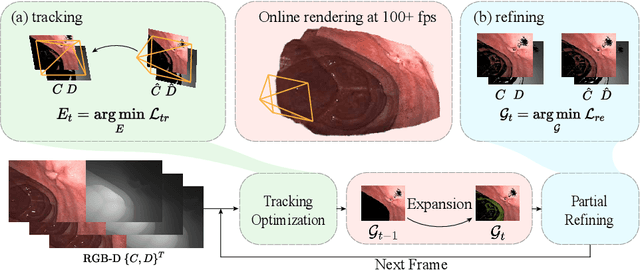

Precise camera tracking, high-fidelity 3D tissue reconstruction, and real-time online visualization are critical for intrabody medical imaging devices such as endoscopes and capsule robots. However, existing SLAM (Simultaneous Localization and Mapping) methods often struggle to achieve both complete high-quality surgical field reconstruction and efficient computation, restricting their intraoperative applications among endoscopic surgeries. In this paper, we introduce EndoGSLAM, an efficient SLAM approach for endoscopic surgeries, which integrates streamlined Gaussian representation and differentiable rasterization to facilitate over 100 fps rendering speed during online camera tracking and tissue reconstructing. Extensive experiments show that EndoGSLAM achieves a better trade-off between intraoperative availability and reconstruction quality than traditional or neural SLAM approaches, showing tremendous potential for endoscopic surgeries. The project page is at https://EndoGSLAM.loping151.com
Open-Vocabulary Object Detection with Meta Prompt Representation and Instance Contrastive Optimization
Mar 14, 2024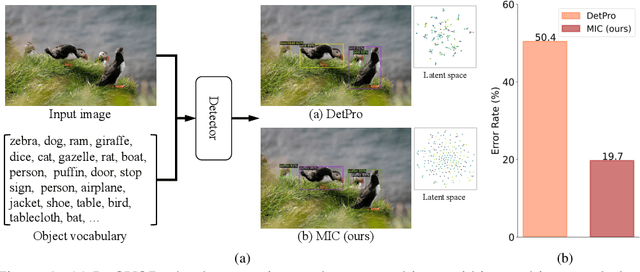
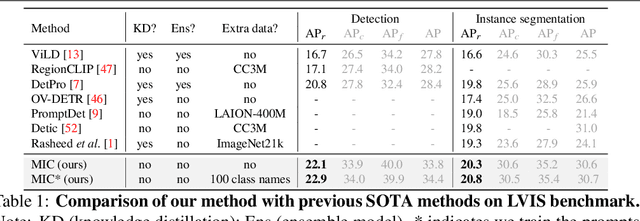
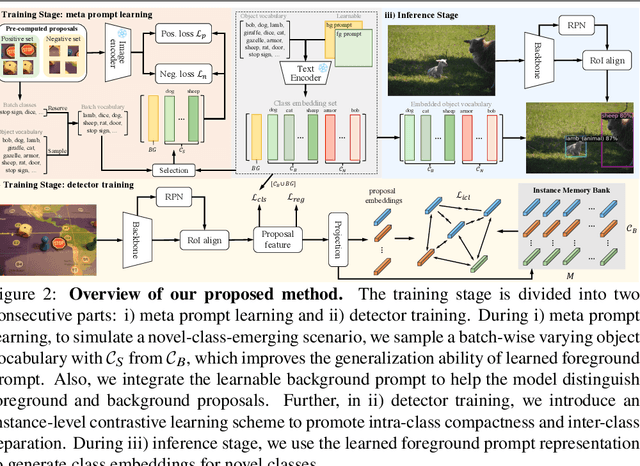
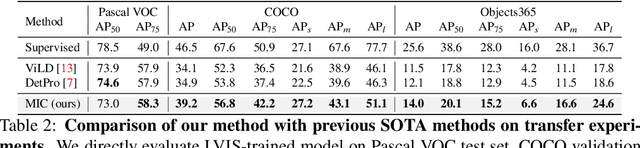
Classical object detectors are incapable of detecting novel class objects that are not encountered before. Regarding this issue, Open-Vocabulary Object Detection (OVOD) is proposed, which aims to detect the objects in the candidate class list. However, current OVOD models are suffering from overfitting on the base classes, heavily relying on the large-scale extra data, and complex training process. To overcome these issues, we propose a novel framework with Meta prompt and Instance Contrastive learning (MIC) schemes. Firstly, we simulate a novel-class-emerging scenario to help the prompt learner that learns class and background prompts generalize to novel classes. Secondly, we design an instance-level contrastive strategy to promote intra-class compactness and inter-class separation, which benefits generalization of the detector to novel class objects. Without using knowledge distillation, ensemble model or extra training data during detector training, our proposed MIC outperforms previous SOTA methods trained with these complex techniques on LVIS. Most importantly, MIC shows great generalization ability on novel classes, e.g., with $+4.3\%$ and $+1.9\% \ \mathrm{AP}$ improvement compared with previous SOTA on COCO and Objects365, respectively.