 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIG: Efficient Self-Interpretable Graph Neural Network for Continuous-time Dynamic Graphs
May 29, 2024While dynamic graph neural networks have shown promise in various applications, explaining their predictions on continuous-time dynamic graphs (CTDGs) is difficult. This paper investigates a new research task: self-interpretable GNNs for CTDGs. We aim to predict future links within the dynamic graph while simultaneously providing causal explanations for these predictions. There are two key challenges: (1) capturing the underlying structural and temporal information that remains consistent across both independent and identically distributed (IID) and out-of-distribution (OOD) data, and (2) efficiently generating high-quality link prediction results and explanations. To tackle these challenges, we propose a novel causal inference model, namely the Independent and Confounded Causal Model (ICCM). ICCM is then integrated into a deep learning architecture that considers both effectiveness and efficiency. Extensive experiments demonstrate that our proposed model significantly outperforms existing methods across link prediction accuracy, explanation quality, and robustness to shortcut features. Our code and datasets are anonymously released at https://github.com/2024SIG/SIG.
Learning Mixture-of-Experts for General-Purpose Black-Box Discrete Optimization
May 29, 2024Real-world applications involve various discrete optimization problems. Designing a specialized optimizer for each of these problems is challenging, typically requiring significant domain knowledge and human efforts. Hence, developing general-purpose optimizers as an off-the-shelf tool for a wide range of problems has been a long-standing research target. This article introduces MEGO, a novel general-purpose neural optimizer trained through a fully data-driven learning-to-optimize (L2O) approach. MEGO consists of a mixture-of-experts trained on experiences from solving training problems and can be viewed as a foundation model for optimization problems with binary decision variables. When presented with a problem to solve, MEGO actively selects relevant expert models to generate high-quality solutions. MEGO can be used as a standalone sample-efficient optimizer or in conjunction with existing search methods as an initial solution generator. The generality of MEGO is validated across six problem classes, including three classic problem classes and three problem classes arising from real-world applications in compilers, network analysis, and 3D reconstruction. Trained solely on classic problem classes, MEGO performs very well on all six problem classes, significantly surpassing widely used general-purpose optimizers in both solution quality and efficiency. In some cases, MEGO even surpasses specialized state-of-the-art optimizers. Additionally, MEGO provides a similarity measure between problems, yielding a new perspective for problem classification. In the pursuit of general-purpose optimizers through L2O, MEGO represents an initial yet significant step forward.
Bridging the Gap Between Theory and Practice: Benchmarking Transfer Evolutionary Optimization
Apr 20, 2024In recent years, the field of Transfer Evolutionary Optimization (TrEO) has witnessed substantial growth, fueled by the realization of its profound impact on solving complex problems. Numerous algorithms have emerged to address the challenges posed by transferring knowledge between tasks. However, the recently highlighted ``no free lunch theorem'' in transfer optimization clarifies that no single algorithm reigns supreme across diverse problem types. This paper addresses this conundrum by adopting a benchmarking approach to evaluate the performance of various TrEO algorithms in realistic scenarios. Despite the growing methodological focus on transfer optimization, existing benchmark problems often fall short due to inadequate design, predominantly featuring synthetic problems that lack real-world relevance. This paper pioneers a practical TrEO benchmark suite, integrating problems from the literature categorized based on the three essential aspects of Big Source Task-Instances: volume, variety, and velocity. Our primary objective is to provide a comprehensive analysis of existing TrEO algorithms and pave the way for the development of new approaches to tackle practical challenges. By introducing realistic benchmarks that embody the three dimensions of volume, variety, and velocity, we aim to foster a deeper understanding of algorithmic performance in the face of diverse and complex transfer scenarios. This benchmark suite is poised to serve as a valuable resource for researchers, facilitating the refinement and advancement of TrEO algorithms in the pursuit of solving real-world problems.
Where to Move Next: Zero-shot Generalization of LLMs for Next POI Recommendation
Apr 02, 2024Next Point-of-interest (POI) recommendation provides valuable suggestions for users to explore their surrounding environment. Existing studies rely on building recommendation models from large-scale users' check-in data, which is task-specific and needs extensive computational resources. Recently, the pretrained large language models (LLMs) have achieved significant advancements in various NLP tasks and have also been investigated for recommendation scenarios. However, the generalization abilities of LLMs still are unexplored to address the next POI recommendations, where users' geographical movement patterns should be extracted. Although there are studies that leverage LLMs for next-item recommendations, they fail to consider the geographical influence and sequential transitions. Hence, they cannot effectively solve the next POI recommendation task. To this end, we design novel prompting strategies and conduct empirical studies to assess the capability of LLMs, e.g., ChatGPT, for predicting a user's next check-in. Specifically, we consider several essential factors in human movement behaviors, including user geographical preference, spatial distance, and sequential transitions, and formulate the recommendation task as a ranking problem. Through extensive experiments on two widely used real-world datasets, we derive several key findings. Empirical evaluations demonstrate that LLMs have promising zero-shot recommendation abilities and can provide accurate and reasonable predictions. We also reveal that LLMs cannot accurately comprehend geographical context information and are sensitive to the order of presentation of candidate POIs, which shows the limitations of LLMs and necessitates further research on robust human mobility reasoning mechanisms.
A Simple Yet Effective Approach for Diversified Session-Based Recommendation
Mar 30, 2024Session-based recommender systems (SBRSs) have become extremely popular in view of the core capability of capturing short-term and dynamic user preferences. However, most SBRSs primarily maximize recommendation accuracy but ignore user minor preferences, thus leading to filter bubbles in the long run. Only a handful of works, being devoted to improving diversity, depend on unique model designs and calibrated loss functions, which cannot be easily adapted to existing accuracy-oriented SBRSs. It is thus worthwhile to come up with a simple yet effective design that can be used as a plugin to facilitate existing SBRSs on generating a more diversified list in the meantime preserving the recommendation accuracy. In this case, we propose an end-to-end framework applied for every existing representative (accuracy-oriented) SBRS, called diversified category-aware attentive SBRS (DCA-SBRS), to boost the performance on recommendation diversity. It consists of two novel designs: a model-agnostic diversity-oriented loss function, and a non-invasive category-aware attention mechanism. Extensive experiments on three datasets showcase that our framework helps existing SBRSs achieve extraordinary performance in terms of recommendation diversity and comprehensive performance, without significantly deteriorating recommendation accuracy compared to state-of-the-art accuracy-oriented SBRSs.
Multi-Task Learning with Multi-Task Optimization
Mar 24, 2024



Multi-task learning solves multiple correlated tasks. However, conflicts may exist between them. In such circumstances, a single solution can rarely optimize all the tasks, leading to performance trade-offs. To arrive at a set of optimized yet well-distributed models that collectively embody different trade-offs in one algorithmic pass, this paper proposes to view Pareto multi-task learning through the lens of multi-task optimization. Multi-task learning is first cast as a multi-objective optimization problem, which is then decomposed into a diverse set of unconstrained scalar-valued subproblems. These subproblems are solved jointly using a novel multi-task gradient descent method, whose uniqueness lies in the iterative transfer of model parameters among the subproblems during the course of optimization. A theorem proving faster convergence through the inclusion of such transfers is presented. We investigate the proposed multi-task learning with multi-task optimization for solving various problem settings including image classification, scene understanding, and multi-target regression. Comprehensive experiments confirm that the proposed method significantly advances the state-of-the-art in discovering sets of Pareto-optimized models. Notably, on the large image dataset we tested on, namely NYUv2, the hypervolume convergence achieved by our method was found to be nearly two times faster than the next-best among the state-of-the-art.
Precise-Physics Driven Text-to-3D Generation
Mar 19, 2024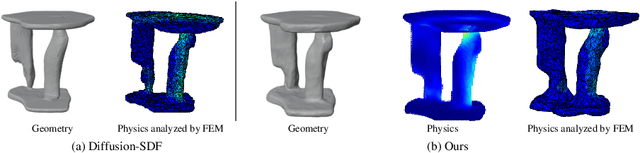
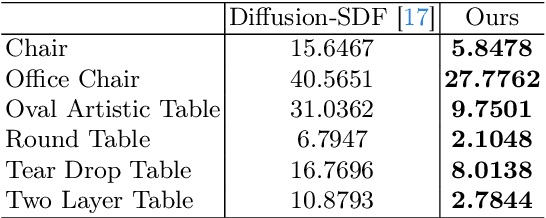


Text-to-3D generation has shown great promise in generating novel 3D content based on given text prompts. However, existing generative methods mostly focus on geometric or visual plausibility while ignoring precise physics perception for the generated 3D shapes. This greatly hinders the practicality of generated 3D shapes in real-world applications. In this work, we propose Phy3DGen, a precise-physics-driven text-to-3D generation method. By analyzing the solid mechanics of generated 3D shapes, we reveal that the 3D shapes generated by existing text-to-3D generation methods are impractical for real-world applications as the generated 3D shapes do not conform to the laws of physics. To this end, we leverage 3D diffusion models to provide 3D shape priors and design a data-driven differentiable physics layer to optimize 3D shape priors with solid mechanics. This allows us to optimize geometry efficiently and learn precise physics information about 3D shapes at the same time. Experimental results demonstrate that our method can consider both geometric plausibility and precise physics perception, further bridging 3D virtual modeling and precise physical worlds.
Inverse Transfer Multiobjective Optimization
Dec 26, 2023Transfer optimization enables data-efficient optimization of a target task by leveraging experiential priors from related source tasks. This is especially useful in multiobjective optimization settings where a set of trade-off solutions is sought under tight evaluation budgets. In this paper, we introduce a novel concept of inverse transfer in multiobjective optimization. Inverse transfer stands out by employing probabilistic inverse models to map performance vectors in the objective space to population search distributions in task-specific decision space, facilitating knowledge transfer through objective space unification. Building upon this idea, we introduce the first Inverse Transfer Multiobjective Evolutionary Optimizer (invTrEMO). A key highlight of invTrEMO is its ability to harness the common objective functions prevalent in many application areas, even when decision spaces do not precisely align between tasks. This allows invTrEMO to uniquely and effectively utilize information from heterogeneous source tasks as well. Furthermore, invTrEMO yields high-precision inverse models as a significant byproduct, enabling the generation of tailored solutions on-demand based on user preferences. Empirical studies on multi- and many-objective benchmark problems, as well as a practical case study, showcase the faster convergence rate and modelling accuracy of the invTrEMO relative to state-of-the-art evolutionary and Bayesian optimization algorithms. The source code of the invTrEMO is made available at https://github.com/LiuJ-2023/invTrEMO.
Dynamic In-Context Learning from Nearest Neighbors for Bundle Generation
Dec 26, 2023Product bundling has evolved into a crucial marketing strategy in e-commerce. However, current studies are limited to generating (1) fixed-size or single bundles, and most importantly, (2) bundles that do not reflect consistent user intents, thus being less intelligible or useful to users. This paper explores two interrelated tasks, i.e., personalized bundle generation and the underlying intent inference based on users' interactions in a session, leveraging the logical reasoning capability of large language models. We introduce a dynamic in-context learning paradigm, which enables ChatGPT to seek tailored and dynamic lessons from closely related sessions as demonstrations while performing tasks in the target session. Specifically, it first harnesses retrieval augmented generation to identify nearest neighbor sessions for each target session. Then, proper prompts are designed to guide ChatGPT to perform the two tasks on neighbor sessions. To enhance reliability and mitigate the hallucination issue, we develop (1) a self-correction strategy to foster mutual improvement in both tasks without supervision signals; and (2) an auto-feedback mechanism to recurrently offer dynamic supervision based on the distinct mistakes made by ChatGPT on various neighbor sessions. Thus, the target session can receive customized and dynamic lessons for improved performance by observing the demonstrations of its neighbor sessions. Finally, experimental results on three real-world datasets verify the effectiveness of our methods on both tasks. Additionally, the inferred intents can prove beneficial for other intriguing downstream tasks, such as crafting appealing bundle names.
PR-NeuS: A Prior-based Residual Learning Paradigm for Fast Multi-view Neural Surface Reconstruction
Dec 18, 2023Neural surfaces learning has shown impressive performance in multi-view surface reconstruction. However, most existing methods use large multilayer perceptrons (MLPs) to train their models from scratch, resulting in hours of training for a single scene. Recently, how to accelerate the neural surfaces learning has received a lot of attention and remains an open problem. In this work, we propose a prior-based residual learning paradigm for fast multi-view neural surface reconstruction. This paradigm consists of two optimization stages. In the first stage, we propose to leverage generalization models to generate a basis signed distance function (SDF) field. This initial field can be quickly obtained by fusing multiple local SDF fields produced by generalization models. This provides a coarse global geometry prior. Based on this prior, in the second stage, a fast residual learning strategy based on hash-encoding networks is proposed to encode an offset SDF field for the basis SDF field. Moreover, we introduce a prior-guided sampling scheme to help the residual learning stage converge better, and thus recover finer structures. With our designed paradigm, experimental results show that our method only takes about 3 minutes to reconstruct the surface of a single scene, while achieving competitive surface quality. Our code will be released upon publication.