 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeÉloi Zablocki
UniTraj: A Unified Framework for Scalable Vehicle Trajectory Prediction
Mar 27, 2024
Vehicle trajectory prediction has increasingly relied on data-driven solutions, but their ability to scale to different data domains and the impact of larger dataset sizes on their generalization remain under-explored. While these questions can be studied by employing multiple datasets, it is challenging due to several discrepancies, e.g., in data formats, map resolution, and semantic annotation types. To address these challenges, we introduce UniTraj, a comprehensive framework that unifies various datasets, models, and evaluation criteria, presenting new opportunities for the vehicle trajectory prediction field. In particular, using UniTraj, we conduct extensive experiments and find that model performance significantly drops when transferred to other datasets. However, enlarging data size and diversity can substantially improve performance, leading to a new state-of-the-art result for the nuScenes dataset. We provide insights into dataset characteristics to explain these findings. The code can be found here: https://github.com/vita-epfl/UniTraj
Unsupervised Object Localization in the Era of Self-Supervised ViTs: A Survey
Oct 19, 2023The recent enthusiasm for open-world vision systems show the high interest of the community to perform perception tasks outside of the closed-vocabulary benchmark setups which have been so popular until now. Being able to discover objects in images/videos without knowing in advance what objects populate the dataset is an exciting prospect. But how to find objects without knowing anything about them? Recent works show that it is possible to perform class-agnostic unsupervised object localization by exploiting self-supervised pre-trained features. We propose here a survey of unsupervised object localization methods that discover objects in images without requiring any manual annotation in the era of self-supervised ViTs. We gather links of discussed methods in the repository https://github.com/valeoai/Awesome-Unsupervised-Object-Localization.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Jun 15, 2023
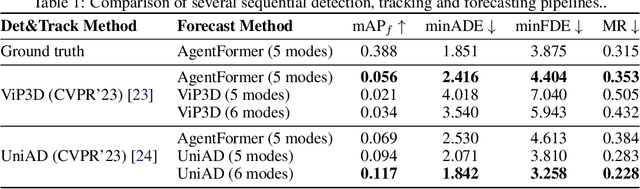

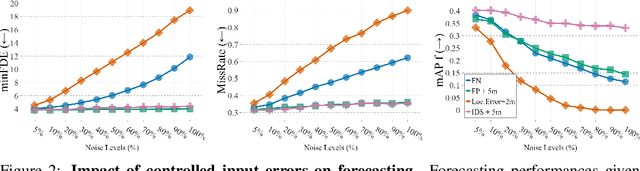
Motion forecasting plays a critical role in enabling robots to anticipate future trajectories of surrounding agents and plan accordingly. However, existing forecasting methods often rely on curated datasets that are not faithful to what real-world perception pipelines can provide. In reality, upstream modules that are responsible for detecting and tracking agents, and those that gather road information to build the map, can introduce various errors, including misdetections, tracking errors, and difficulties in being accurate for distant agents and road elements. This paper aims to uncover the challenges of bringing motion forecasting models to this more realistic setting where inputs are provided by perception modules. In particular, we quantify the impacts of the domain gap through extensive evaluation. Furthermore, we design synthetic perturbations to better characterize their consequences, thus providing insights into areas that require improvement in upstream perception modules and guidance toward the development of more robust forecasting methods.
Unsupervised Object Localization: Observing the Background to Discover Objects
Dec 15, 2022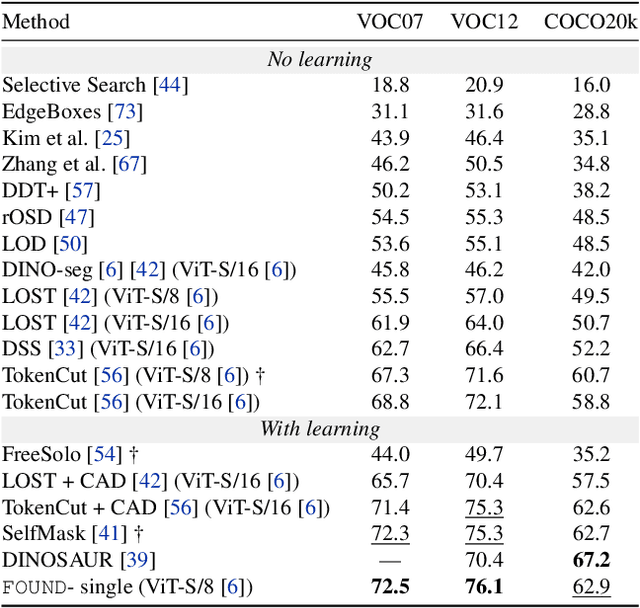
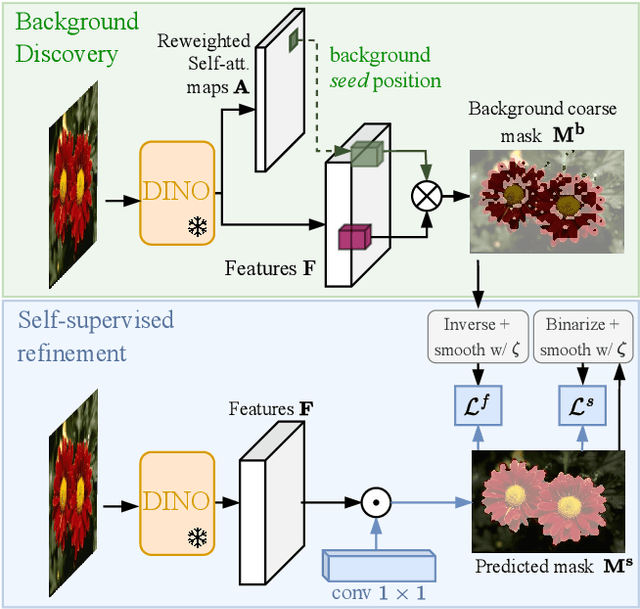
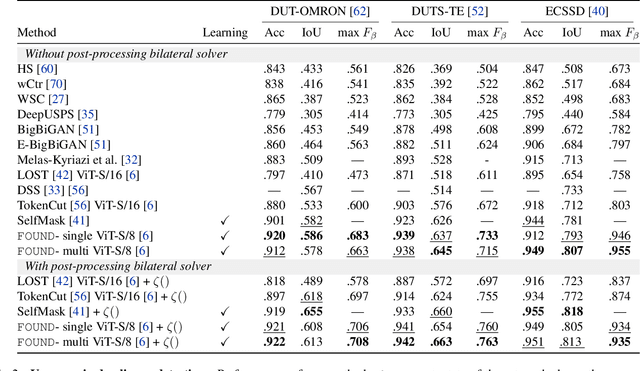

Recent advances in self-supervised visual representation learning have paved the way for unsupervised methods tackling tasks such as object discovery and instance segmentation. However, discovering objects in an image with no supervision is a very hard task; what are the desired objects, when to separate them into parts, how many are there, and of what classes? The answers to these questions depend on the tasks and datasets of evaluation. In this work, we take a different approach and propose to look for the background instead. This way, the salient objects emerge as a by-product without any strong assumption on what an object should be. We propose FOUND, a simple model made of a single $conv1\times1$ initialized with coarse background masks extracted from self-supervised patch-based representations. After fast training and refining these seed masks, the model reaches state-of-the-art results on unsupervised saliency detection and object discovery benchmarks. Moreover, we show that our approach yields good results in the unsupervised semantic segmentation retrieval task. The code to reproduce our results is available at https://github.com/valeoai/FOUND.
OCTET: Object-aware Counterfactual Explanations
Nov 22, 2022

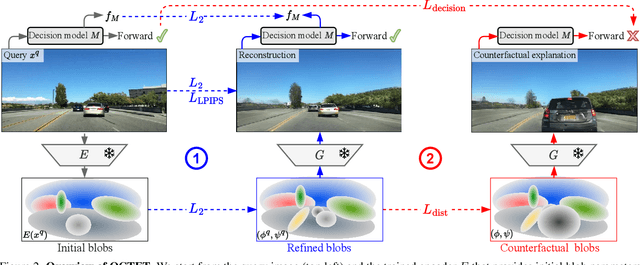
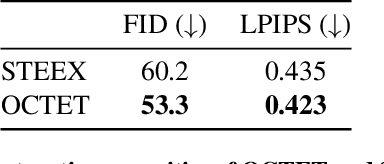
Nowadays, deep vision models are being widely deployed in safety-critical applications, e.g., autonomous driving, and explainability of such models is becoming a pressing concern. Among explanation methods, counterfactual explanations aim to find minimal and interpretable changes to the input image that would also change the output of the model to be explained. Such explanations point end-users at the main factors that impact the decision of the model. However, previous methods struggle to explain decision models trained on images with many objects, e.g., urban scenes, which are more difficult to work with but also arguably more critical to explain. In this work, we propose to tackle this issue with an object-centric framework for counterfactual explanation generation. Our method, inspired by recent generative modeling works, encodes the query image into a latent space that is structured in a way to ease object-level manipulations. Doing so, it provides the end-user with control over which search directions (e.g., spatial displacement of objects, style modification, etc.) are to be explored during the counterfactual generation. We conduct a set of experiments on counterfactual explanation benchmarks for driving scenes, and we show that our method can be adapted beyond classification, e.g., to explain semantic segmentation models. To complete our analysis, we design and run a user study that measures the usefulness of counterfactual explanations in understanding a decision model. Code is available at https://github.com/valeoai/OCTET.
LaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation
Jun 27, 2022


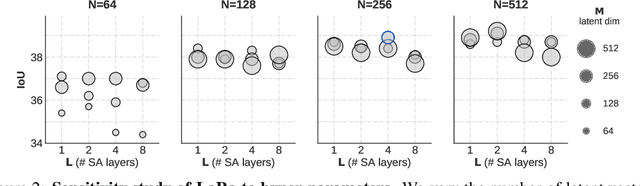
Recent works in autonomous driving have widely adopted the bird's-eye-view (BEV) semantic map as an intermediate representation of the world. Online prediction of these BEV maps involves non-trivial operations such as multi-camera data extraction as well as fusion and projection into a common top-view grid. This is usually done with error-prone geometric operations (e.g., homography or back-projection from monocular depth estimation) or expensive direct dense mapping between image pixels and pixels in BEV (e.g., with MLP or attention). In this work, we present 'LaRa', an efficient encoder-decoder, transformer-based model for vehicle semantic segmentation from multiple cameras. Our approach uses a system of cross-attention to aggregate information over multiple sensors into a compact, yet rich, collection of latent representations. These latent representations, after being processed by a series of self-attention blocks, are then reprojected with a second cross-attention in the BEV space. We demonstrate that our model outperforms on nuScenes the best previous works using transformers.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 26, 2021


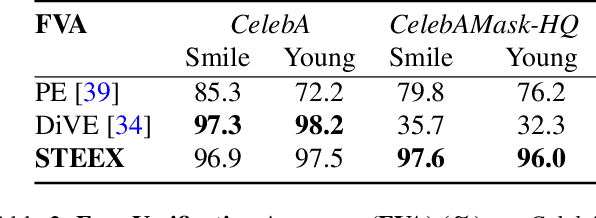
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).
Raising context awareness in motion forecasting
Sep 16, 2021
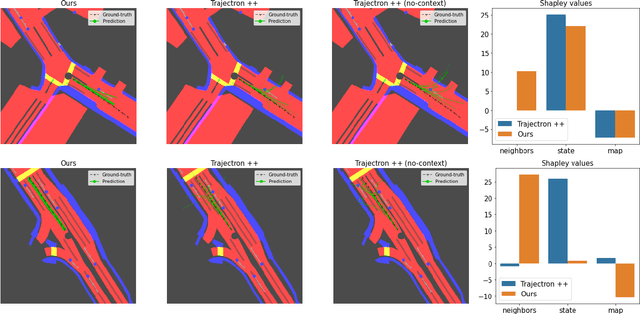


Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.
LiDARTouch: Monocular metric depth estimation with a few-beam LiDAR
Sep 08, 2021
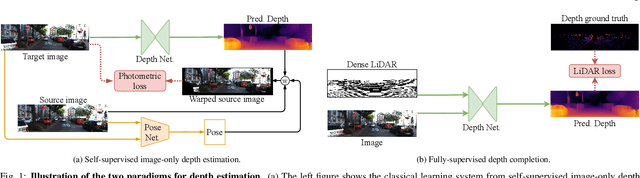
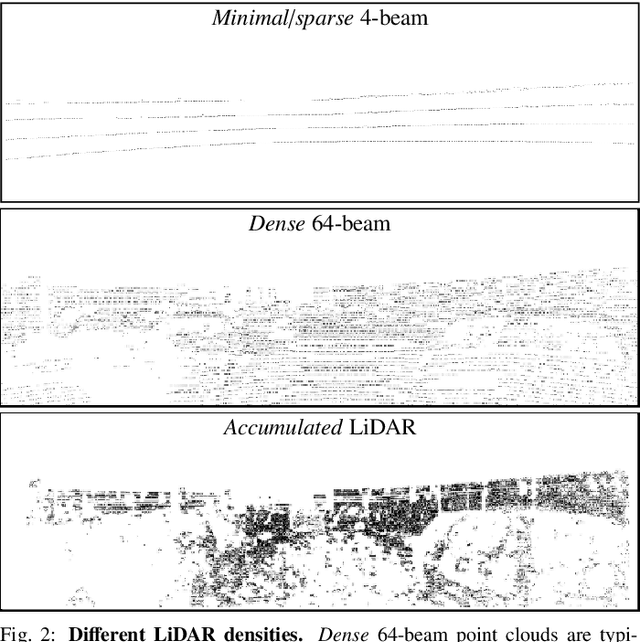
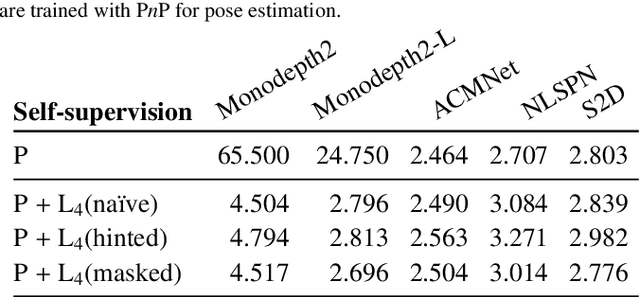
Vision-based depth estimation is a key feature in autonomous systems, which often relies on a single camera or several independent ones. In such a monocular setup, dense depth is obtained with either additional input from one or several expensive LiDARs, e.g., with 64 beams, or camera-only methods, which suffer from scale-ambiguity and infinite-depth problems. In this paper, we propose a new alternative of densely estimating metric depth by combining a monocular camera with a light-weight LiDAR, e.g., with 4 beams, typical of today's automotive-grade mass-produced laser scanners. Inspired by recent self-supervised methods, we introduce a novel framework, called LiDARTouch, to estimate dense depth maps from monocular images with the help of ``touches'' of LiDAR, i.e., without the need for dense ground-truth depth. In our setup, the minimal LiDAR input contributes on three different levels: as an additional model's input, in a self-supervised LiDAR reconstruction objective function, and to estimate changes of pose (a key component of self-supervised depth estimation architectures). Our LiDARTouch framework achieves new state of the art in self-supervised depth estimation on the KITTI dataset, thus supporting our choices of integrating the very sparse LiDAR signal with other visual features. Moreover, we show that the use of a few-beam LiDAR alleviates scale ambiguity and infinite-depth issues that camera-only methods suffer from. We also demonstrate that methods from the fully-supervised depth-completion literature can be adapted to a self-supervised regime with a minimal LiDAR signal.
Explainability of vision-based autonomous driving systems: Review and challenges
Jan 13, 2021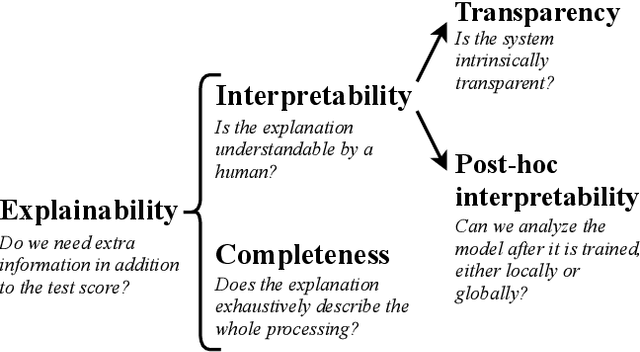


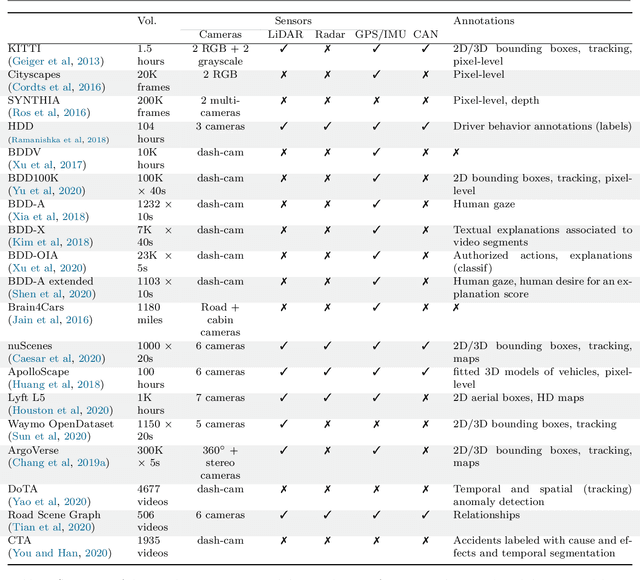
This survey reviews explainability methods for vision-based self-driving systems. The concept of explainability has several facets and the need for explainability is strong in driving, a safety-critical application. Gathering contributions from several research fields, namely computer vision, deep learning, autonomous driving, explainable AI (X-AI), this survey tackles several points. First, it discusses definitions, context, and motivation for gaining more interpretability and explainability from self-driving systems. Second, major recent state-of-the-art approaches to develop self-driving systems are quickly presented. Third, methods providing explanations to a black-box self-driving system in a post-hoc fashion are comprehensively organized and detailed. Fourth, approaches from the literature that aim at building more interpretable self-driving systems by design are presented and discussed in detail. Finally, remaining open-challenges and potential future research directions are identified and examined.