 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAaron Q Li
Fast Latent Variable Models for Inference and Visualization on Mobile Devices
Oct 23, 2015
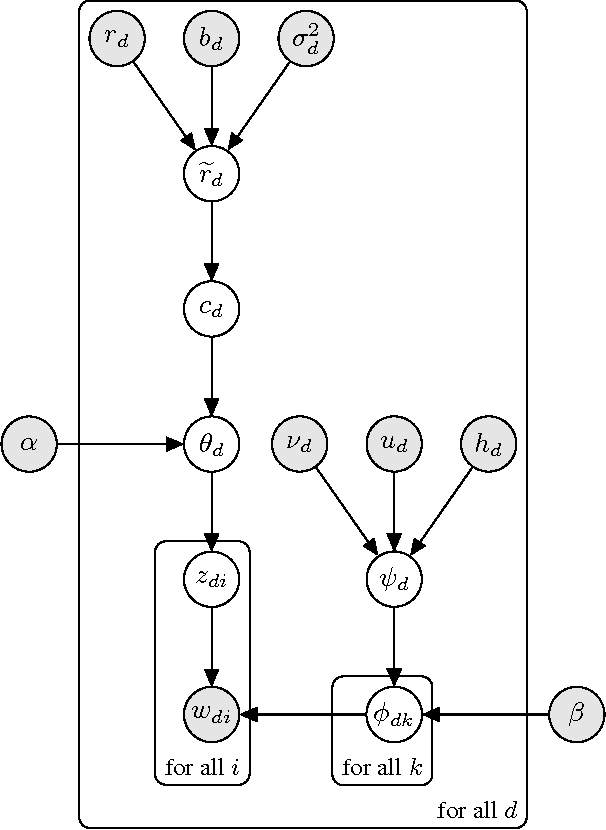
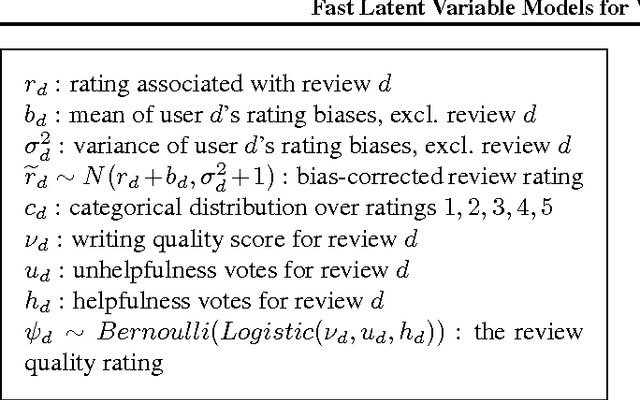

In this project we outline Vedalia, a high performance distributed network for performing inference on latent variable models in the context of Amazon review visualization. We introduce a new model, RLDA, which extends Latent Dirichlet Allocation (LDA) [Blei et al., 2003] for the review space by incorporating auxiliary data available in online reviews to improve modeling while simultaneously remaining compatible with pre-existing fast sampling techniques such as [Yao et al., 2009; Li et al., 2014a] to achieve high performance. The network is designed such that computation is efficiently offloaded to the client devices using the Chital system [Robinson & Li, 2015], improving response times and reducing server costs. The resulting system is able to rapidly compute a large number of specialized latent variable models while requiring minimal server resources.
Multi-GPU Distributed Parallel Bayesian Differential Topic Modelling
Oct 22, 2015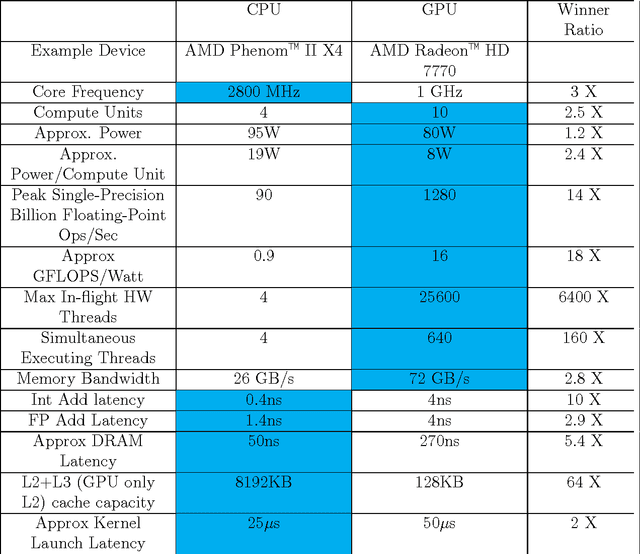
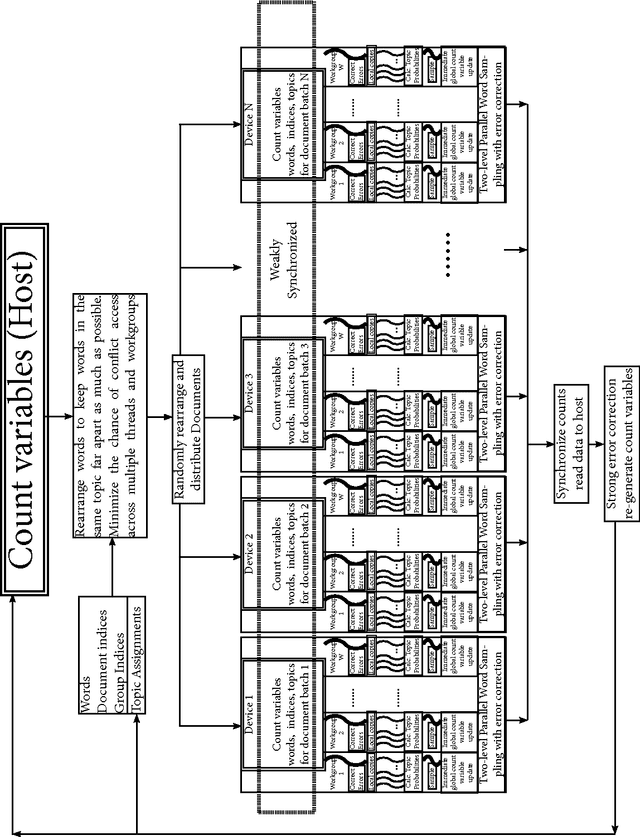

There is an explosion of data, documents, and other content, and people require tools to analyze and interpret these, tools to turn the content into information and knowledge. Topic modeling have been developed to solve these problems. Topic models such as LDA [Blei et. al. 2003] allow salient patterns in data to be extracted automatically. When analyzing texts, these patterns are called topics. Among numerous extensions of LDA, few of them can reliably analyze multiple groups of documents and extract topic similarities. Recently, the introduction of differential topic modeling (SPDP) [Chen et. al. 2012] performs uniformly better than many topic models in a discriminative setting. There is also a need to improve the sampling speed for topic models. While some effort has been made for distributed algorithms, there is no work currently done using graphical processing units (GPU). Note the GPU framework has already become the most cost-efficient platform for many problems. In this thesis, I propose and implement a scalable multi-GPU distributed parallel framework which approximates SPDP. Through experiments, I have shown my algorithms have a gain in speed of about 50 times while being almost as accurate, with only one single cheap laptop GPU. Furthermore, I have shown the speed improvement is sublinearly scalable when multiple GPUs are used, while fairly maintaining the accuracy. Therefore on a medium-sized GPU cluster, the speed improvement could potentially reach a factor of a thousand. Note SPDP is just a representative of other extensions of LDA. Although my algorithm is implemented to work with SPDP, it is designed to be a general enough to work with other topic models. The speed-up on smaller collections (i.e., 1000s of documents), means that these more complex LDA extensions could now be done in real-time, thus opening up a new way of using these LDA models in industry.
Creating Scalable and Interactive Web Applications Using High Performance Latent Variable Models
Oct 21, 2015

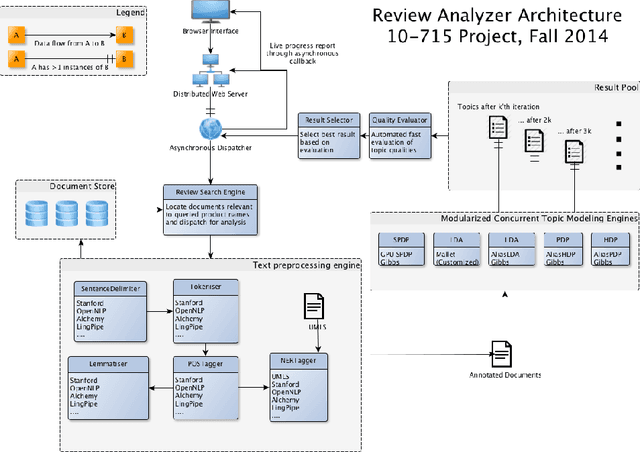
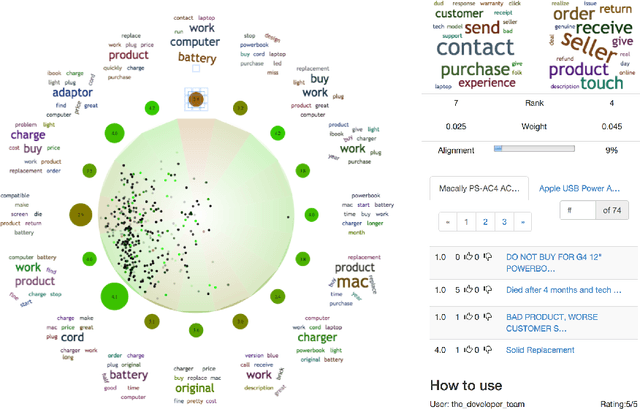
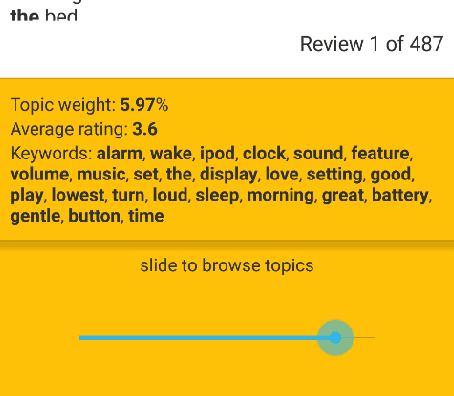
In this project we outline a modularized, scalable system for comparing Amazon products in an interactive and informative way using efficient latent variable models and dynamic visualization. We demonstrate how our system can build on the structure and rich review information of Amazon products in order to provide a fast, multifaceted, and intuitive comparison. By providing a condensed per-topic comparison visualization to the user, we are able to display aggregate information from the entire set of reviews while providing an interface that is at least as compact as the "most helpful reviews" currently displayed by Amazon, yet far more informative.