 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAaron Steinfeld
TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data
Sep 29, 2023

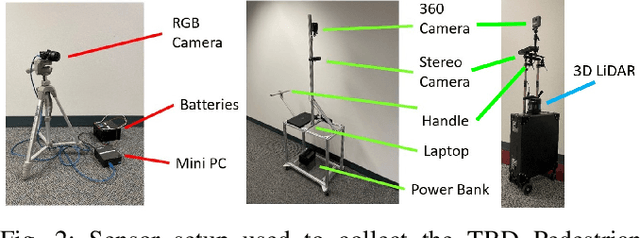


Social navigation and pedestrian behavior research has shifted towards machine learning-based methods and converged on the topic of modeling inter-pedestrian interactions and pedestrian-robot interactions. For this, large-scale datasets that contain rich information are needed. We describe a portable data collection system, coupled with a semi-autonomous labeling pipeline. As part of the pipeline, we designed a label correction web app that facilitates human verification of automated pedestrian tracking outcomes. Our system enables large-scale data collection in diverse environments and fast trajectory label production. Compared with existing pedestrian data collection methods, our system contains three components: a combination of top-down and ego-centric views, natural human behavior in the presence of a socially appropriate "robot", and human-verified labels grounded in the metric space. To the best of our knowledge, no prior data collection system has a combination of all three components. We further introduce our ever-expanding dataset from the ongoing data collection effort -- the TBD Pedestrian Dataset and show that our collected data is larger in scale, contains richer information when compared to prior datasets with human-verified labels, and supports new research opportunities.
Synergistic Integration of Large Language Models and Cognitive Architectures for Robust AI: An Exploratory Analysis
Sep 05, 2023
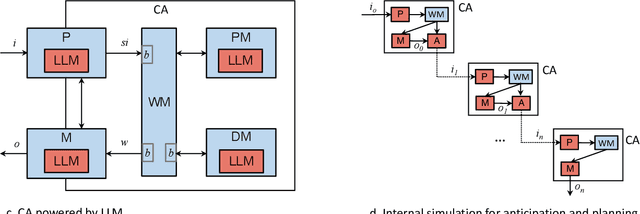
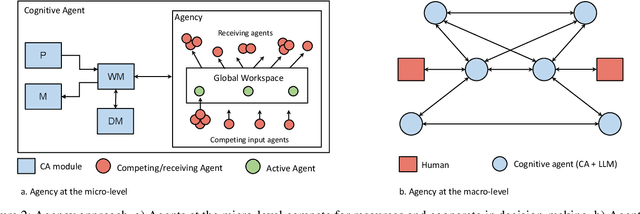
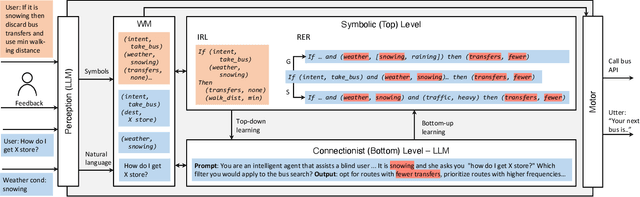
This paper explores the integration of two AI subdisciplines employed in the development of artificial agents that exhibit intelligent behavior: Large Language Models (LLMs) and Cognitive Architectures (CAs). We present three integration approaches, each grounded in theoretical models and supported by preliminary empirical evidence. The modular approach, which introduces four models with varying degrees of integration, makes use of chain-of-thought prompting, and draws inspiration from augmented LLMs, the Common Model of Cognition, and the simulation theory of cognition. The agency approach, motivated by the Society of Mind theory and the LIDA cognitive architecture, proposes the formation of agent collections that interact at micro and macro cognitive levels, driven by either LLMs or symbolic components. The neuro-symbolic approach, which takes inspiration from the CLARION cognitive architecture, proposes a model where bottom-up learning extracts symbolic representations from an LLM layer and top-down guidance utilizes symbolic representations to direct prompt engineering in the LLM layer. These approaches aim to harness the strengths of both LLMs and CAs, while mitigating their weaknesses, thereby advancing the development of more robust AI systems. We discuss the tradeoffs and challenges associated with each approach.
Optimizing Algorithms From Pairwise User Preferences
Aug 08, 2023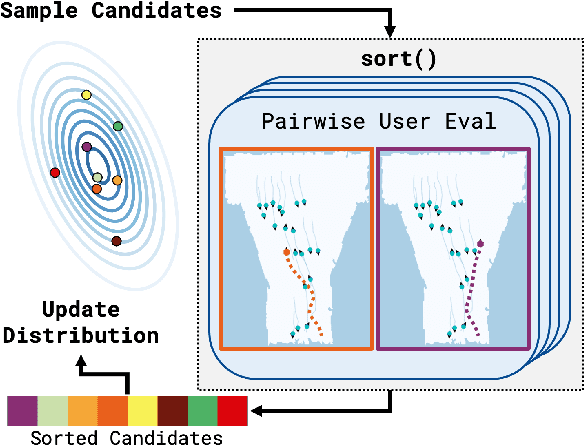


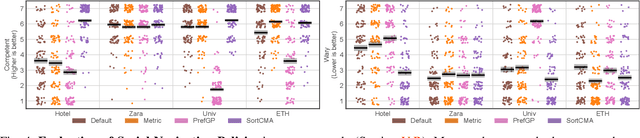
Typical black-box optimization approaches in robotics focus on learning from metric scores. However, that is not always possible, as not all developers have ground truth available. Learning appropriate robot behavior in human-centric contexts often requires querying users, who typically cannot provide precise metric scores. Existing approaches leverage human feedback in an attempt to model an implicit reward function; however, this reward may be difficult or impossible to effectively capture. In this work, we introduce SortCMA to optimize algorithm parameter configurations in high dimensions based on pairwise user preferences. SortCMA efficiently and robustly leverages user input to find parameter sets without directly modeling a reward. We apply this method to tuning a commercial depth sensor without ground truth, and to robot social navigation, which involves highly complex preferences over robot behavior. We show that our method succeeds in optimizing for the user's goals and perform a user study to evaluate social navigation results.
AAAI SSS-22 Symposium on Closing the Assessment Loop: Communicating Proficiency and Intent in Human-Robot Teaming
Apr 05, 2022The proposed symposium focuses understanding, modeling, and improving the efficacy of (a) communicating proficiency from human to robot and (b) communicating intent from a human to a robot. For example, how should a robot convey predicted ability on a new task? How should it report performance on a task that was just completed? How should a robot adapt its proficiency criteria based on human intentions and values? Communities in AI, robotics, HRI, and cognitive science have addressed related questions, but there are no agreed upon standards for evaluating proficiency and intent-based interactions. This is a pressing challenge for human-robot interaction for a variety of reasons. Prior work has shown that a robot that can assess its performance can alter human perception of the robot and decisions on control allocation. There is also significant evidence in robotics that accurately setting human expectations is critical, especially when proficiency is below human expectations. Moreover, proficiency assessment depends on context and intent, and a human teammate might increase or decrease performance standards, adapt tolerance for risk and uncertainty, demand predictive assessments that affect attention allocation, or otherwise reassess or adapt intent.
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022


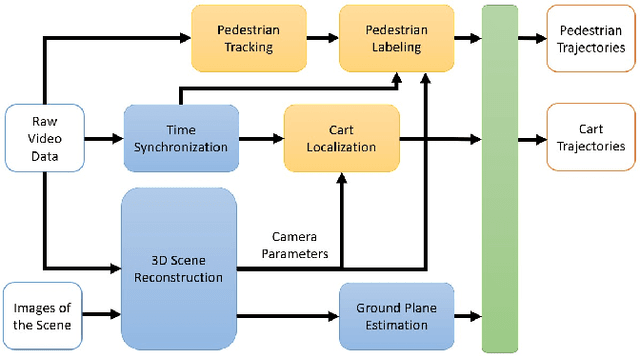
Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
Group-based Motion Prediction for Navigation in Crowded Environments
Aug 19, 2021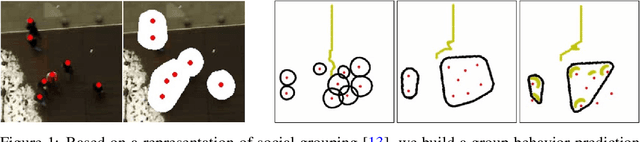
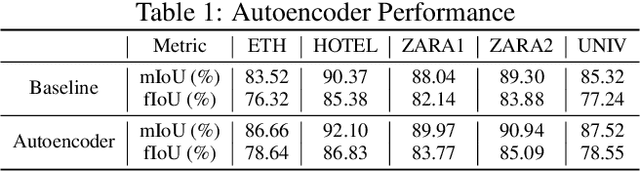
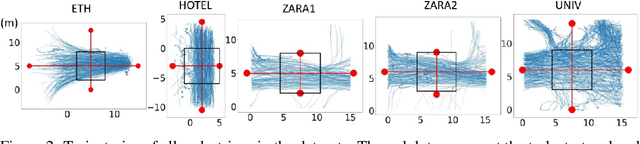
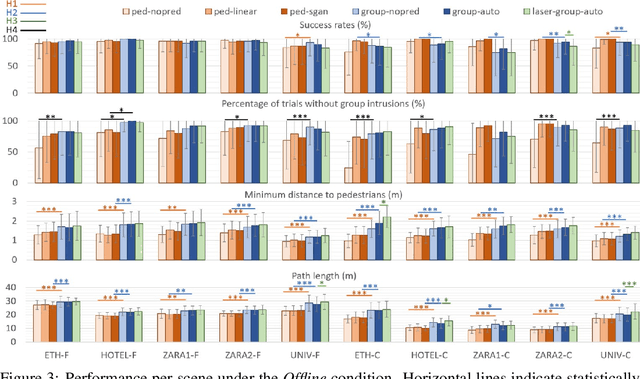
We focus on the problem of planning the motion of a robot in a dynamic multiagent environment such as a pedestrian scene. Enabling the robot to navigate safely and in a socially compliant fashion in such scenes requires a representation that accounts for the unfolding multiagent dynamics. Existing approaches to this problem tend to employ microscopic models of motion prediction that reason about the individual behavior of other agents. While such models may achieve high tracking accuracy in trajectory prediction benchmarks, they often lack an understanding of the group structures unfolding in crowded scenes. Inspired by the Gestalt theory from psychology, we build a Model Predictive Control framework (G-MPC) that leverages group-based prediction for robot motion planning. We conduct an extensive simulation study involving a series of challenging navigation tasks in scenes extracted from two real-world pedestrian datasets. We illustrate that G-MPC enables a robot to achieve statistically significantly higher safety and lower number of group intrusions than a series of baselines featuring individual pedestrian motion prediction models. Finally, we show that G-MPC can handle noisy lidar-scan estimates without significant performance losses.
Core Challenges of Social Robot Navigation: A Survey
Mar 17, 2021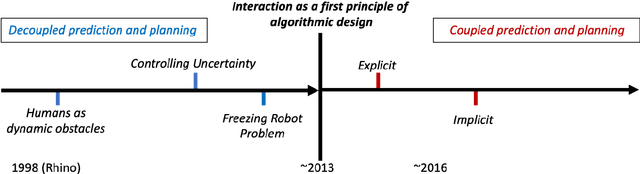
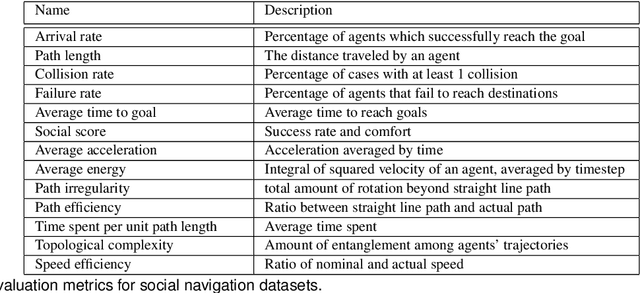
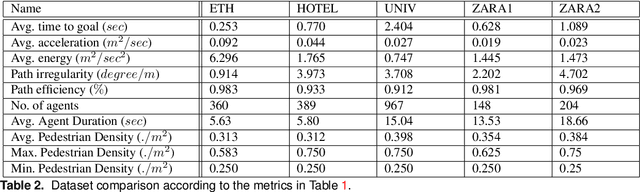
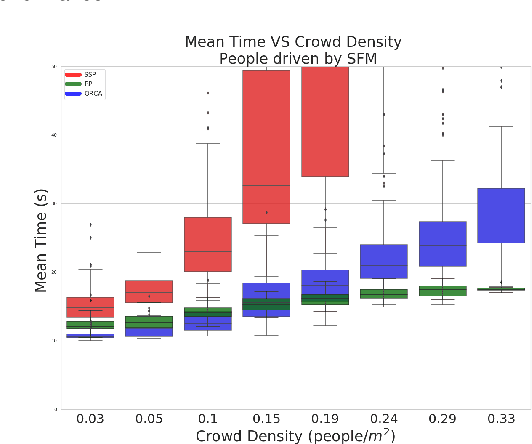
Robot navigation in crowded public spaces is a complex task that requires addressing a variety of engineering and human factors challenges. These challenges have motivated a great amount of research resulting in important developments for the fields of robotics and human-robot interaction over the past three decades. Despite the significant progress and the massive recent interest, we observe a number of significant remaining challenges that prohibit the seamless deployment of autonomous robots in public pedestrian environments. In this survey article, we organize existing challenges into a set of categories related to broader open problems in motion planning, behavior design, and evaluation methodologies. Within these categories, we review past work, and offer directions for future research. Our work builds upon and extends earlier survey efforts by a) taking a critical perspective and diagnosing fundamental limitations of adopted practices in the field and b) offering constructive feedback and ideas that we aspire will drive research in the field over the coming decade.
SocNavBench: A Grounded Simulation Testing Framework for Evaluating Social Navigation
Feb 26, 2021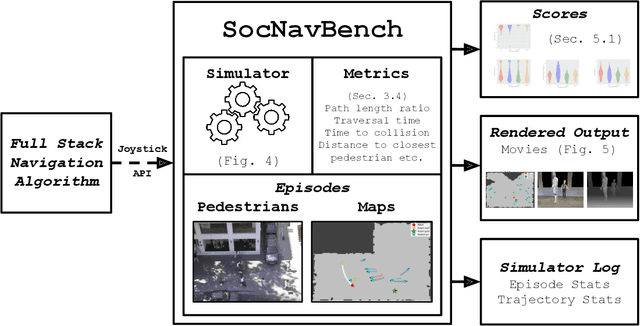
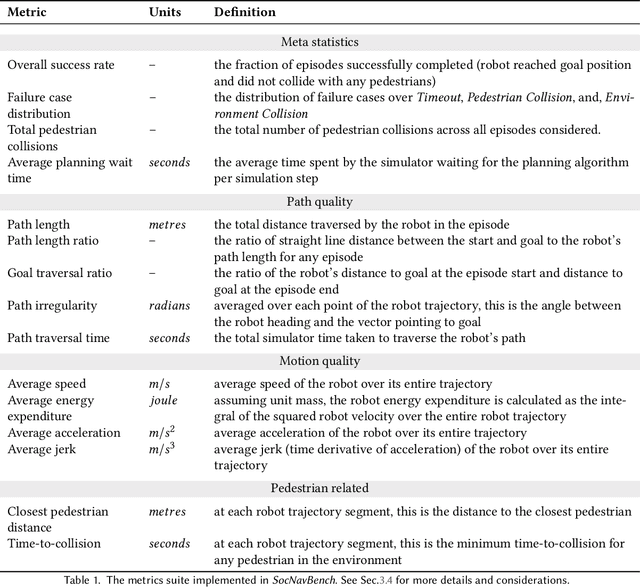

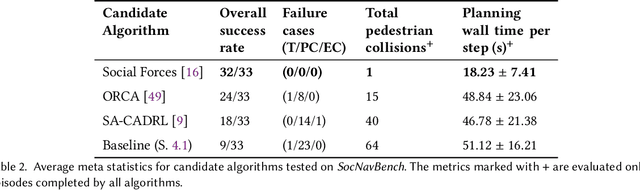
The human-robot interaction (HRI) community has developed many methods for robots to navigate safely and socially alongside humans. However, experimental procedures to evaluate these works are usually constructed on a per-method basis. Such disparate evaluations make it difficult to compare the performance of such methods across the literature. To bridge this gap, we introduce SocNavBench, a simulation framework for evaluating social navigation algorithms. SocNavBench comprises a simulator with photo-realistic capabilities and curated social navigation scenarios grounded in real-world pedestrian data. We also provide an implementation of a suite of metrics to quantify the performance of navigation algorithms on these scenarios. Altogether, SocNavBench provides a test framework for evaluating disparate social navigation methods in a consistent and interpretable manner. To illustrate its use, we demonstrate testing three existing social navigation methods and a baseline method on SocNavBench, showing how the suite of metrics helps infer their performance trade-offs. Our code is open-source, allowing the addition of new scenarios and metrics by the community to help evolve SocNavBench to reflect advancements in our understanding of social navigation.
Facilitating Connected Autonomous Vehicle Operations Using Space-weighted Information Fusion and Deep Reinforcement Learning Based Control
Sep 30, 2020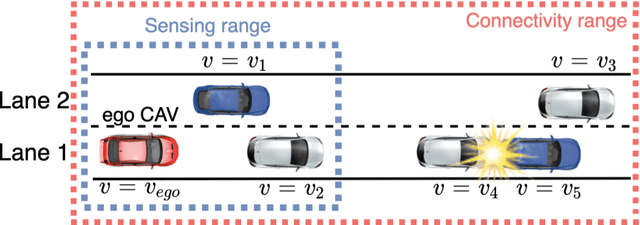
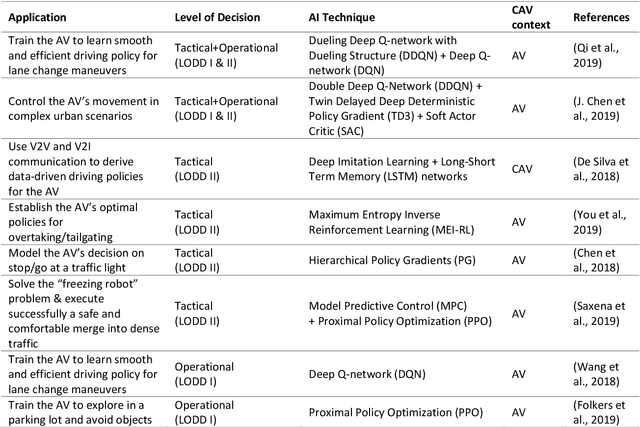
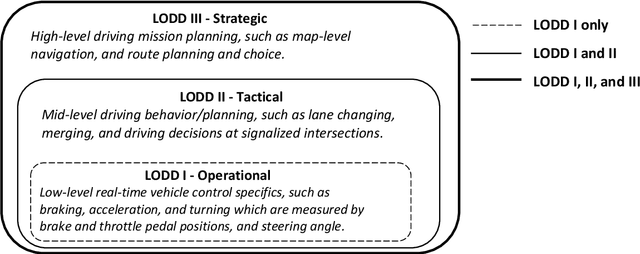
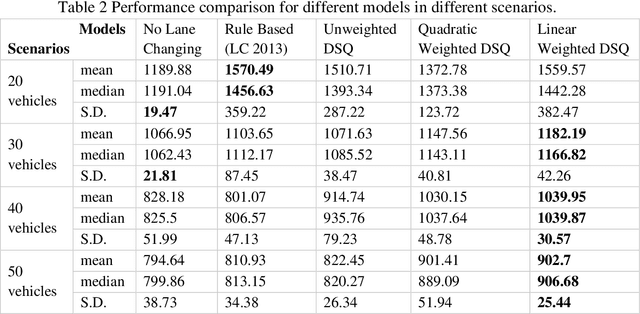
The connectivity aspect of connected autonomous vehicles (CAV) is beneficial because it facilitates dissemination of traffic-related information to vehicles through Vehicle-to-External (V2X) communication. Onboard sensing equipment including LiDAR and camera can reasonably characterize the traffic environment in the immediate locality of the CAV. However, their performance is limited by their sensor range (SR). On the other hand, longer-range information is helpful for characterizing imminent conditions downstream. By contemporaneously coalescing the short- and long-range information, the CAV can construct comprehensively its surrounding environment and thereby facilitate informed, safe, and effective movement planning in the short-term (local decisions including lane change) and long-term (route choice). In this paper, we describe a Deep Reinforcement Learning based approach that integrates the data collected through sensing and connectivity capabilities from other vehicles located in the proximity of the CAV and from those located further downstream, and we use the fused data to guide lane changing, a specific context of CAV operations. In addition, recognizing the importance of the connectivity range (CR) to the performance of not only the algorithm but also of the vehicle in the actual driving environment, the paper carried out a case study. The case study demonstrates the application of the proposed algorithm and duly identifies the appropriate CR for each level of prevailing traffic density. It is expected that implementation of the algorithm in CAVs can enhance the safety and mobility associated with CAV driving operations. From a general perspective, its implementation can provide guidance to connectivity equipment manufacturers and CAV operators, regarding the default CR settings for CAVs or the recommended CR setting in a given traffic environment.
Proceedings of the 2020 Workshop on Assessing, Explaining, and Conveying Robot Proficiency for Human-Robot Teaming
May 12, 2020This record contains the proceedings of the 2020 Workshop on Assessing, Explaining, and Conveying Robot Proficiency for Human-Robot Teaming, which was held in conjunction with the 2020 ACM/IEEE International Conference on Human-Robot Interaction (HRI). This workshop was originally scheduled to occur in Cambridge, UK on March 23, but was moved to a set of online talks due to the COVID-19 pandemic.