 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbdullatif Köksal
MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Apr 17, 2024




While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $\unicode{x2013}$ though non-parametric $\unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
Hybrid Human-LLM Corpus Construction and LLM Evaluation for Rare Linguistic Phenomena
Mar 11, 2024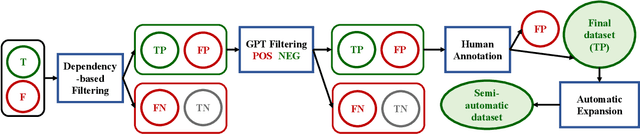
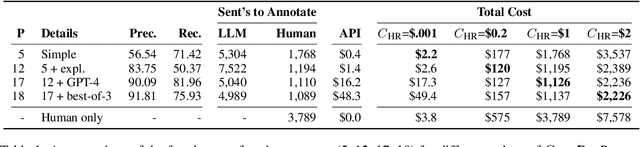

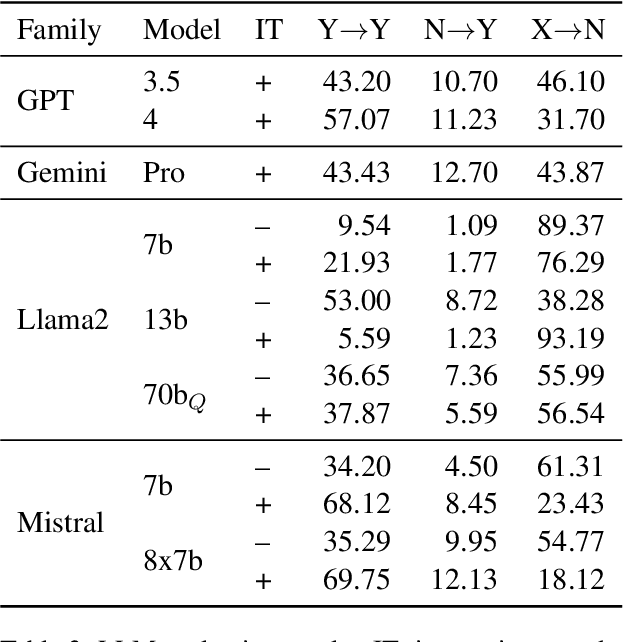
Argument Structure Constructions (ASCs) are one of the most well-studied construction groups, providing a unique opportunity to demonstrate the usefulness of Construction Grammar (CxG). For example, the caused-motion construction (CMC, ``She sneezed the foam off her cappuccino'') demonstrates that constructions must carry meaning, otherwise the fact that ``sneeze'' in this context causes movement cannot be explained. We form the hypothesis that this remains challenging even for state-of-the-art Large Language Models (LLMs), for which we devise a test based on substituting the verb with a prototypical motion verb. To be able to perform this test at statistically significant scale, in the absence of adequate CxG corpora, we develop a novel pipeline of NLP-assisted collection of linguistically annotated text. We show how dependency parsing and GPT-3.5 can be used to significantly reduce annotation cost and thus enable the annotation of rare phenomena at scale. We then evaluate GPT, Gemini, Llama2 and Mistral models for their understanding of the CMC using the newly collected corpus. We find that all models struggle with understanding the motion component that the CMC adds to a sentence.
Hallucination Augmented Recitations for Language Models
Nov 13, 2023Attribution is a key concept in large language models (LLMs) as it enables control over information sources and enhances the factuality of LLMs. While existing approaches utilize open book question answering to improve attribution, factual datasets may reward language models to recall facts that they already know from their pretraining data, not attribution. In contrast, counterfactual open book QA datasets would further improve attribution because the answer could only be grounded in the given text. We propose Hallucination Augmented Recitations (HAR) for creating counterfactual datasets by utilizing hallucination in LLMs to improve attribution. For open book QA as a case study, we demonstrate that models finetuned with our counterfactual datasets improve text grounding, leading to better open book QA performance, with up to an 8.0% increase in F1 score. Our counterfactual dataset leads to significantly better performance than using humanannotated factual datasets, even with 4x smaller datasets and 4x smaller models. We observe that improvements are consistent across various model sizes and datasets, including multi-hop, biomedical, and adversarial QA datasets.
Language-Agnostic Bias Detection in Language Models
May 22, 2023



Pretrained language models (PLMs) are key components in NLP, but they contain strong social biases. Quantifying these biases is challenging because current methods focusing on fill-the-mask objectives are sensitive to slight changes in input. To address this, we propose LABDet, a robust language-agnostic method for evaluating bias in PLMs. For nationality as a case study, we show that LABDet "surfaces" nationality bias by training a classifier on top of a frozen PLM on non-nationality sentiment detection. Collaborating with political scientists, we find consistent patterns of nationality bias across monolingual PLMs in six languages that align with historical and political context. We also show for English BERT that bias surfaced by LABDet correlates well with bias in the pretraining data; thus, our work is one of the few studies that directly links pretraining data to PLM behavior. Finally, we verify LABDet's reliability and applicability to different templates and languages through an extensive set of robustness checks.
LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction
Apr 17, 2023
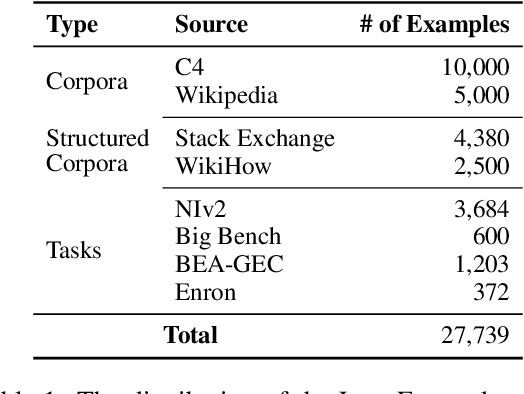

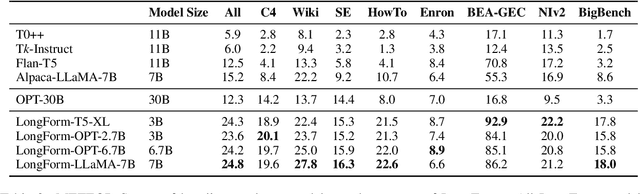
Instruction tuning enables language models to generalize more effectively and better follow user intent. However, obtaining instruction data can be costly and challenging. Prior works employ methods such as expensive human annotation, crowd-sourced datasets with alignment issues, or generating noisy examples via LLMs. We introduce the LongForm dataset, which is created by leveraging English corpus examples with augmented instructions. We select a diverse set of human-written documents from existing corpora such as C4 and Wikipedia and generate instructions for the given documents via LLMs. This approach provides a cheaper and cleaner instruction-tuning dataset and one suitable for long text generation. We finetune T5, OPT, and LLaMA models on our dataset and show that even smaller LongForm models have good generalization capabilities for text generation. Our models outperform 10x larger language models without instruction tuning on various tasks such as story/recipe generation and long-form question answering. Moreover, LongForm models outperform prior instruction-tuned models such as FLAN-T5 and Alpaca by a large margin. Finally, our models can effectively follow and answer multilingual instructions; we demonstrate this for news generation. We publicly release our data and models: https://github.com/akoksal/LongForm.
Sociocultural knowledge is needed for selection of shots in hate speech detection tasks
Apr 11, 2023



We introduce HATELEXICON, a lexicon of slurs and targets of hate speech for the countries of Brazil, Germany, India and Kenya, to aid training and interpretability of models. We demonstrate how our lexicon can be used to interpret model predictions, showing that models developed to classify extreme speech rely heavily on target words when making predictions. Further, we propose a method to aid shot selection for training in low-resource settings via HATELEXICON. In few-shot learning, the selection of shots is of paramount importance to model performance. In our work, we simulate a few-shot setting for German and Hindi, using HASOC data for training and the Multilingual HateCheck (MHC) as a benchmark. We show that selecting shots based on our lexicon leads to models performing better on MHC than models trained on shots sampled randomly. Thus, when given only a few training examples, using our lexicon to select shots containing more sociocultural information leads to better few-shot performance.
MEAL: Stable and Active Learning for Few-Shot Prompting
Nov 15, 2022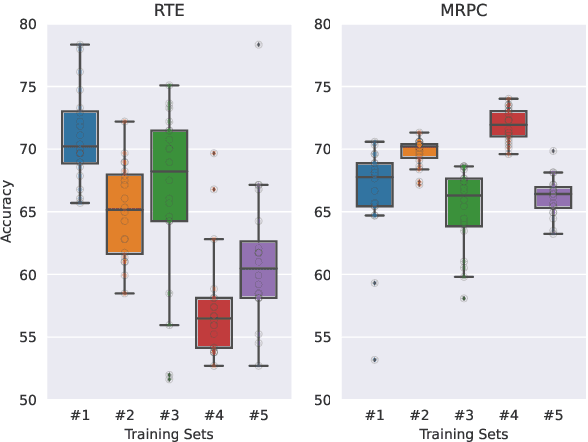
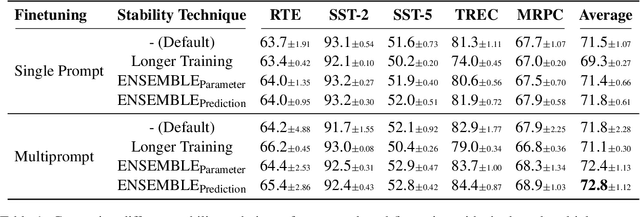
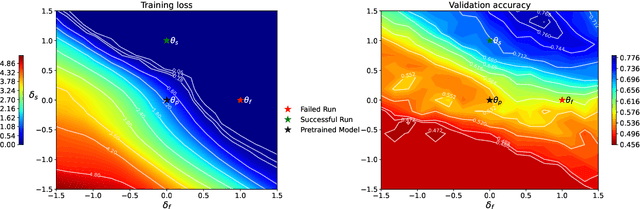
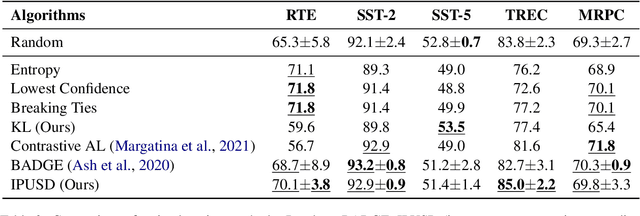
Few-shot classification in NLP has recently made great strides due to the availability of large foundation models that, through priming and prompting, are highly effective few-shot learners. However, this approach has high variance across different sets of few shots and across different finetuning runs. For example, we find that validation accuracy on RTE can vary by as much as 27 points. In this context, we make two contributions for more effective few-shot learning. First, we propose novel ensembling methods and show that they substantially reduce variance. Second, since performance depends a lot on the set of few shots selected, active learning is promising for few-shot classification. Based on our stable ensembling method, we build on existing work on active learning and introduce a new criterion: inter-prompt uncertainty sampling with diversity. We present the first active learning based approach to select training examples for prompt-based learning and show that it outperforms prior work on active learning. Finally, we show that our combined method, MEAL (Multiprompt finetuning and prediction Ensembling with Active Learning), improves overall performance of prompt-based finetuning by 2.3 absolute points on five different tasks.
The Better Your Syntax, the Better Your Semantics? Probing Pretrained Language Models for the English Comparative Correlative
Oct 24, 2022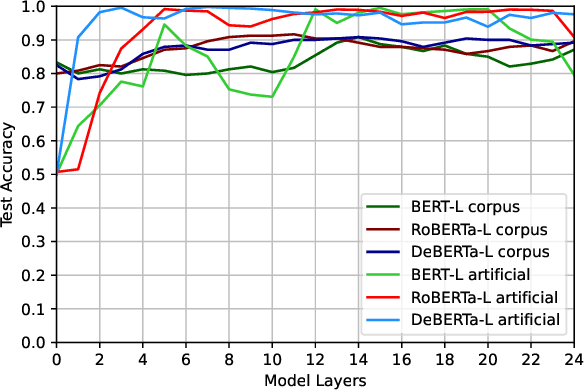

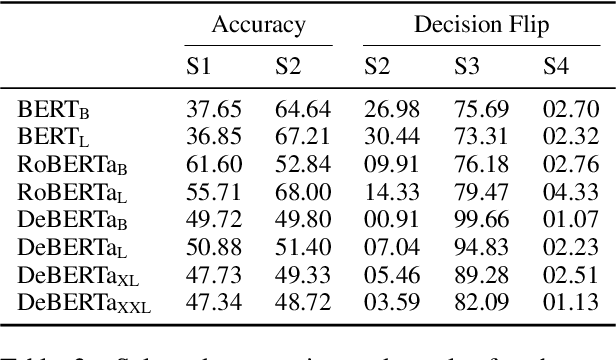
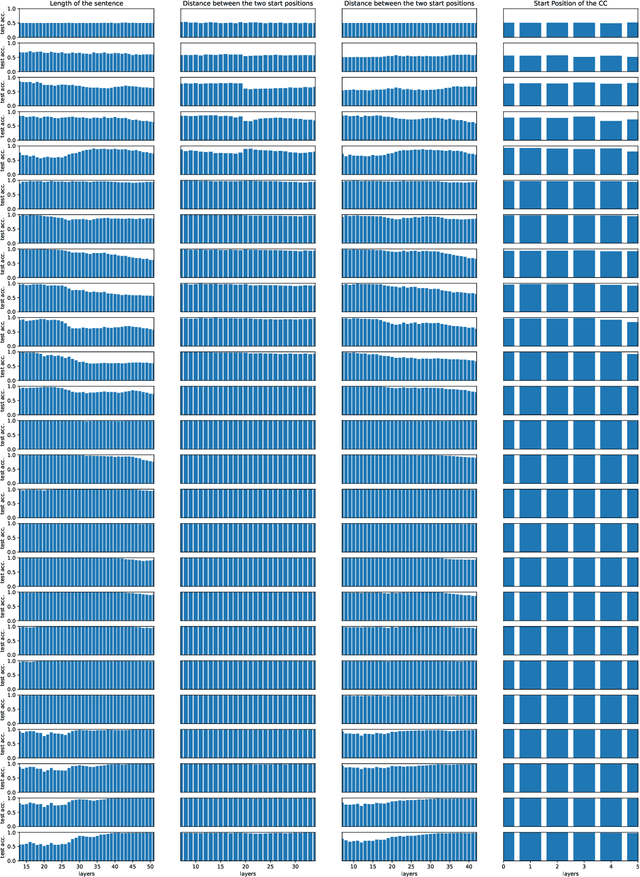
Construction Grammar (CxG) is a paradigm from cognitive linguistics emphasising the connection between syntax and semantics. Rather than rules that operate on lexical items, it posits constructions as the central building blocks of language, i.e., linguistic units of different granularity that combine syntax and semantics. As a first step towards assessing the compatibility of CxG with the syntactic and semantic knowledge demonstrated by state-of-the-art pretrained language models (PLMs), we present an investigation of their capability to classify and understand one of the most commonly studied constructions, the English comparative correlative (CC). We conduct experiments examining the classification accuracy of a syntactic probe on the one hand and the models' behaviour in a semantic application task on the other, with BERT, RoBERTa, and DeBERTa as the example PLMs. Our results show that all three investigated PLMs are able to recognise the structure of the CC but fail to use its meaning. While human-like performance of PLMs on many NLP tasks has been alleged, this indicates that PLMs still suffer from substantial shortcomings in central domains of linguistic knowledge.
SilverAlign: MT-Based Silver Data Algorithm For Evaluating Word Alignment
Oct 12, 2022



Word alignments are essential for a variety of NLP tasks. Therefore, choosing the best approaches for their creation is crucial. However, the scarce availability of gold evaluation data makes the choice difficult. We propose SilverAlign, a new method to automatically create silver data for the evaluation of word aligners by exploiting machine translation and minimal pairs. We show that performance on our silver data correlates well with gold benchmarks for 9 language pairs, making our approach a valid resource for evaluation of different domains and languages when gold data are not available. This addresses the important scenario of missing gold data alignments for low-resource languages.
Balancing Methods for Multi-label Text Classification with Long-Tailed Class Distribution
Sep 10, 2021



Multi-label text classification is a challenging task because it requires capturing label dependencies. It becomes even more challenging when class distribution is long-tailed. Resampling and re-weighting are common approaches used for addressing the class imbalance problem, however, they are not effective when there is label dependency besides class imbalance because they result in oversampling of common labels. Here, we introduce the application of balancing loss functions for multi-label text classification. We perform experiments on a general domain dataset with 90 labels (Reuters-21578) and a domain-specific dataset from PubMed with 18211 labels. We find that a distribution-balanced loss function, which inherently addresses both the class imbalance and label linkage problems, outperforms commonly used loss functions. Distribution balancing methods have been successfully used in the image recognition field. Here, we show their effectiveness in natural language processing. Source code is available at https://github.com/blessu/BalancedLossNLP.