 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbe Bohan Hou
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks
Feb 18, 2024
The widespread use of large language models (LLMs) is increasing the demand for methods that detect machine-generated text to prevent misuse. The goal of our study is to stress test the detectors' robustness to malicious attacks under realistic scenarios. We comprehensively study the robustness of popular machine-generated text detectors under attacks from diverse categories: editing, paraphrasing, prompting, and co-generating. Our attacks assume limited access to the generator LLMs, and we compare the performance of detectors on different attacks under different budget levels. Our experiments reveal that almost none of the existing detectors remain robust under all the attacks, and all detectors exhibit different loopholes. Averaging all detectors, the performance drops by 35% across all attacks. Further, we investigate the reasons behind these defects and propose initial out-of-the-box patches to improve robustness.
k-SemStamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text
Feb 17, 2024Recent watermarked generation algorithms inject detectable signatures during language generation to facilitate post-hoc detection. While token-level watermarks are vulnerable to paraphrase attacks, SemStamp (Hou et al., 2023) applies watermark on the semantic representation of sentences and demonstrates promising robustness. SemStamp employs locality-sensitive hashing (LSH) to partition the semantic space with arbitrary hyperplanes, which results in a suboptimal tradeoff between robustness and speed. We propose k-SemStamp, a simple yet effective enhancement of SemStamp, utilizing k-means clustering as an alternative of LSH to partition the embedding space with awareness of inherent semantic structure. Experimental results indicate that k-SemStamp saliently improves its robustness and sampling efficiency while preserving the generation quality, advancing a more effective tool for machine-generated text detection.
SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
Oct 06, 2023
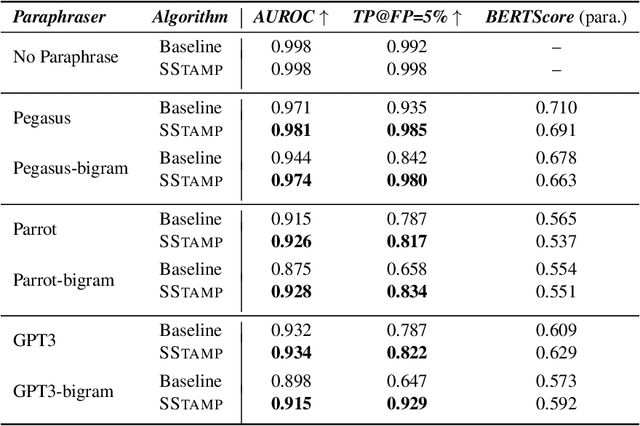
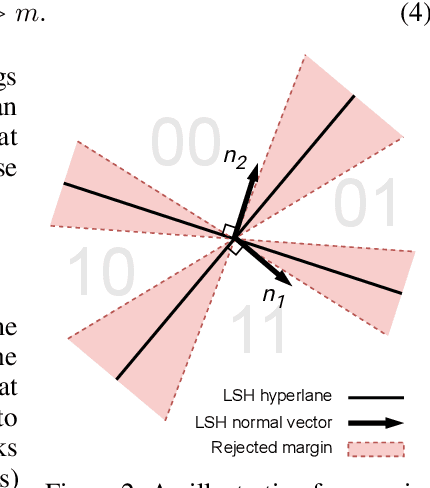
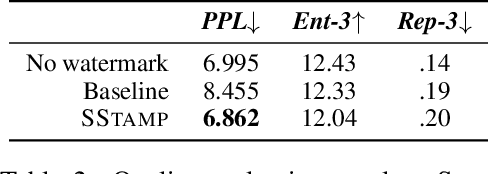
Existing watermarking algorithms are vulnerable to paraphrase attacks because of their token-level design. To address this issue, we propose SemStamp, a robust sentence-level semantic watermarking algorithm based on locality-sensitive hashing (LSH), which partitions the semantic space of sentences. The algorithm encodes and LSH-hashes a candidate sentence generated by an LLM, and conducts sentence-level rejection sampling until the sampled sentence falls in watermarked partitions in the semantic embedding space. A margin-based constraint is used to enhance its robustness. To show the advantages of our algorithm, we propose a "bigram" paraphrase attack using the paraphrase that has the fewest bigram overlaps with the original sentence. This attack is shown to be effective against the existing token-level watermarking method. Experimental results show that our novel semantic watermark algorithm is not only more robust than the previous state-of-the-art method on both common and bigram paraphrase attacks, but also is better at preserving the quality of generation.