 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbhinav Valada
Imagine2touch: Predictive Tactile Sensing for Robotic Manipulation using Efficient Low-Dimensional Signals
May 02, 2024
Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term Imagine2touch. Imagine2touch aims to predict the expected touch signal based on a visual patch representing the area to be touched. We use ReSkin, an inexpensive and compact touch sensor to collect the required dataset through random touching of five basic geometric shapes, and one tool. We train Imagine2touch on two out of those shapes and validate it on the ood. tool. We demonstrate the efficacy of Imagine2touch through its application to the downstream task of object recognition. In this task, we evaluate Imagine2touch performance in two experiments, together comprising 5 out of training distribution objects. Imagine2touch achieves an object recognition accuracy of 58% after ten touches per object, surpassing a proprioception baseline.
Automatic Target-Less Camera-LiDAR Calibration From Motion and Deep Point Correspondences
Apr 26, 2024Sensor setups of robotic platforms commonly include both camera and LiDAR as they provide complementary information. However, fusing these two modalities typically requires a highly accurate calibration between them. In this paper, we propose MDPCalib which is a novel method for camera-LiDAR calibration that requires neither human supervision nor any specific target objects. Instead, we utilize sensor motion estimates from visual and LiDAR odometry as well as deep learning-based 2D-pixel-to-3D-point correspondences that are obtained without in-domain retraining. We represent the camera-LiDAR calibration as a graph optimization problem and minimize the costs induced by constraints from sensor motion and point correspondences. In extensive experiments, we demonstrate that our approach yields highly accurate extrinsic calibration parameters and is robust to random initialization. Additionally, our approach generalizes to a wide range of sensor setups, which we demonstrate by employing it on various robotic platforms including a self-driving perception car, a quadruped robot, and a UAV. To make our calibration method publicly accessible, we release the code on our project website at http://calibration.cs.uni-freiburg.de.
CenterArt: Joint Shape Reconstruction and 6-DoF Grasp Estimation of Articulated Objects
Apr 23, 2024Precisely grasping and reconstructing articulated objects is key to enabling general robotic manipulation. In this paper, we propose CenterArt, a novel approach for simultaneous 3D shape reconstruction and 6-DoF grasp estimation of articulated objects. CenterArt takes RGB-D images of the scene as input and first predicts the shape and joint codes through an encoder. The decoder then leverages these codes to reconstruct 3D shapes and estimate 6-DoF grasp poses of the objects. We further develop a mechanism for generating a dataset of 6-DoF grasp ground truth poses for articulated objects. CenterArt is trained on realistic scenes containing multiple articulated objects with randomized designs, textures, lighting conditions, and realistic depths. We perform extensive experiments demonstrating that CenterArt outperforms existing methods in accuracy and robustness.
A Point-Based Approach to Efficient LiDAR Multi-Task Perception
Apr 19, 2024Multi-task networks can potentially improve performance and computational efficiency compared to single-task networks, facilitating online deployment. However, current multi-task architectures in point cloud perception combine multiple task-specific point cloud representations, each requiring a separate feature encoder and making the network structures bulky and slow. We propose PAttFormer, an efficient multi-task architecture for joint semantic segmentation and object detection in point clouds that only relies on a point-based representation. The network builds on transformer-based feature encoders using neighborhood attention and grid-pooling and a query-based detection decoder using a novel 3D deformable-attention detection head design. Unlike other LiDAR-based multi-task architectures, our proposed PAttFormer does not require separate feature encoders for multiple task-specific point cloud representations, resulting in a network that is 3x smaller and 1.4x faster while achieving competitive performance on the nuScenes and KITTI benchmarks for autonomous driving perception. Our extensive evaluations show substantial gains from multi-task learning, improving LiDAR semantic segmentation by +1.7% in mIou and 3D object detection by +1.7% in mAP on the nuScenes benchmark compared to the single-task models.
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Mar 26, 2024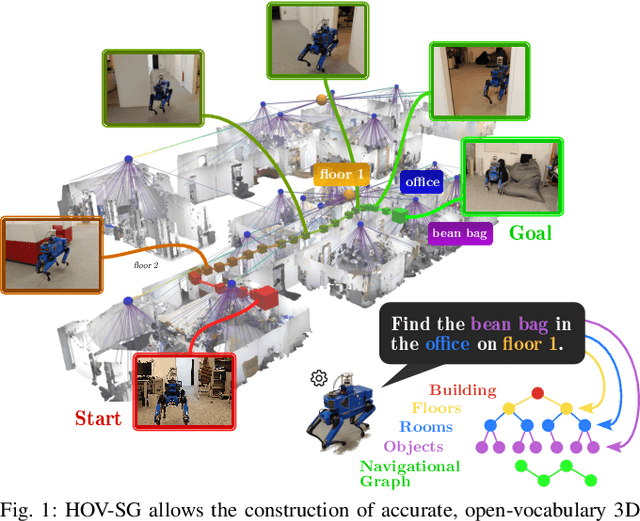
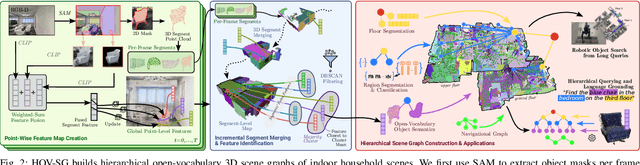
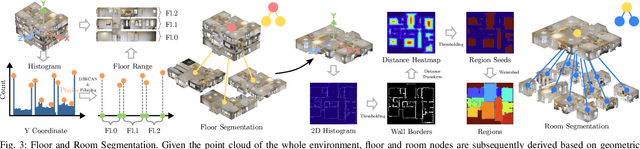
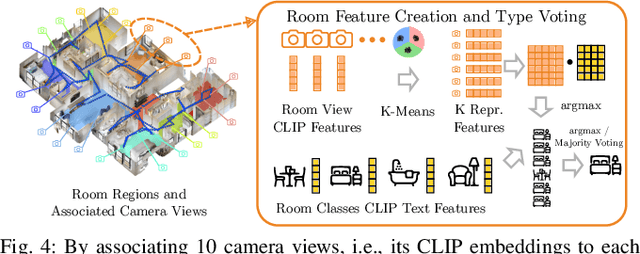
Recent open-vocabulary robot mapping methods enrich dense geometric maps with pre-trained visual-language features. While these maps allow for the prediction of point-wise saliency maps when queried for a certain language concept, large-scale environments and abstract queries beyond the object level still pose a considerable hurdle, ultimately limiting language-grounded robotic navigation. In this work, we present HOV-SG, a hierarchical open-vocabulary 3D scene graph mapping approach for language-grounded robot navigation. Leveraging open-vocabulary vision foundation models, we first obtain state-of-the-art open-vocabulary segment-level maps in 3D and subsequently construct a 3D scene graph hierarchy consisting of floor, room, and object concepts, each enriched with open-vocabulary features. Our approach is able to represent multi-story buildings and allows robotic traversal of those using a cross-floor Voronoi graph. HOV-SG is evaluated on three distinct datasets and surpasses previous baselines in open-vocabulary semantic accuracy on the object, room, and floor level while producing a 75% reduction in representation size compared to dense open-vocabulary maps. In order to prove the efficacy and generalization capabilities of HOV-SG, we showcase successful long-horizon language-conditioned robot navigation within real-world multi-storage environments. We provide code and trial video data at http://hovsg.github.io/.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.
DITTO: Demonstration Imitation by Trajectory Transformation
Mar 22, 2024Teaching robots new skills quickly and conveniently is crucial for the broader adoption of robotic systems. In this work, we address the problem of one-shot imitation from a single human demonstration, given by an RGB-D video recording through a two-stage process. In the first stage which is offline, we extract the trajectory of the demonstration. This entails segmenting manipulated objects and determining their relative motion in relation to secondary objects such as containers. Subsequently, in the live online trajectory generation stage, we first \mbox{re-detect} all objects, then we warp the demonstration trajectory to the current scene, and finally, we trace the trajectory with the robot. To complete these steps, our method makes leverages several ancillary models, including those for segmentation, relative object pose estimation, and grasp prediction. We systematically evaluate different combinations of correspondence and re-detection methods to validate our design decision across a diverse range of tasks. Specifically, we collect demonstrations of ten different tasks including pick-and-place tasks as well as articulated object manipulation. Finally, we perform extensive evaluations on a real robot system to demonstrate the effectiveness and utility of our approach in real-world scenarios. We make the code publicly available at http://ditto.cs.uni-freiburg.de.
Bayesian Optimization for Sample-Efficient Policy Improvement in Robotic Manipulation
Mar 21, 2024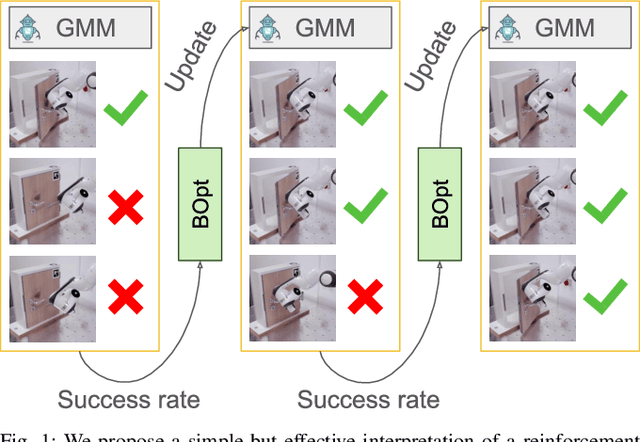
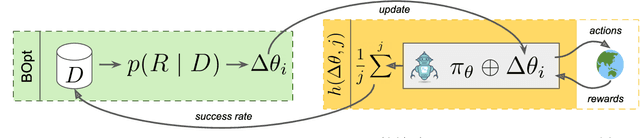
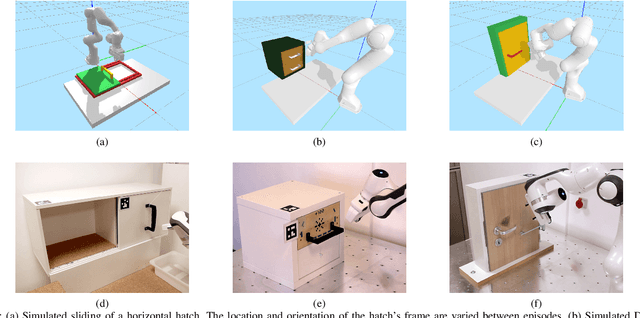

Sample efficient learning of manipulation skills poses a major challenge in robotics. While recent approaches demonstrate impressive advances in the type of task that can be addressed and the sensing modalities that can be incorporated, they still require large amounts of training data. Especially with regard to learning actions on robots in the real world, this poses a major problem due to the high costs associated with both demonstrations and real-world robot interactions. To address this challenge, we introduce BOpt-GMM, a hybrid approach that combines imitation learning with own experience collection. We first learn a skill model as a dynamical system encoded in a Gaussian Mixture Model from a few demonstrations. We then improve this model with Bayesian optimization building on a small number of autonomous skill executions in a sparse reward setting. We demonstrate the sample efficiency of our approach on multiple complex manipulation skills in both simulations and real-world experiments. Furthermore, we make the code and pre-trained models publicly available at http://bopt-gmm. cs.uni-freiburg.de.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024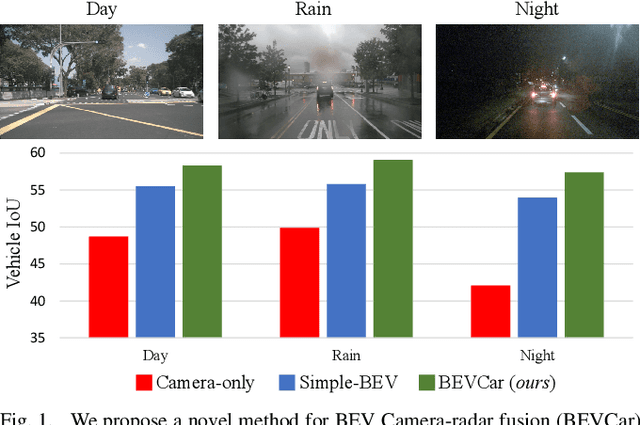
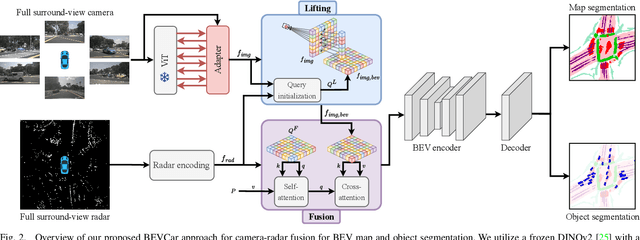
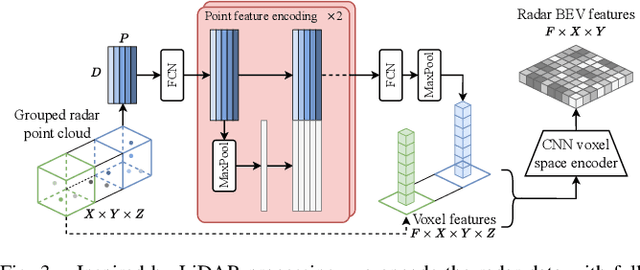
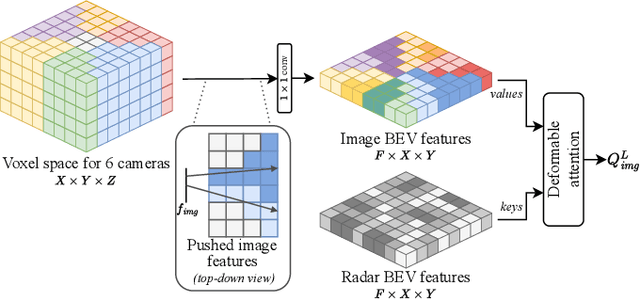
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
Language-Grounded Dynamic Scene Graphs for Interactive Object Search with Mobile Manipulation
Mar 14, 2024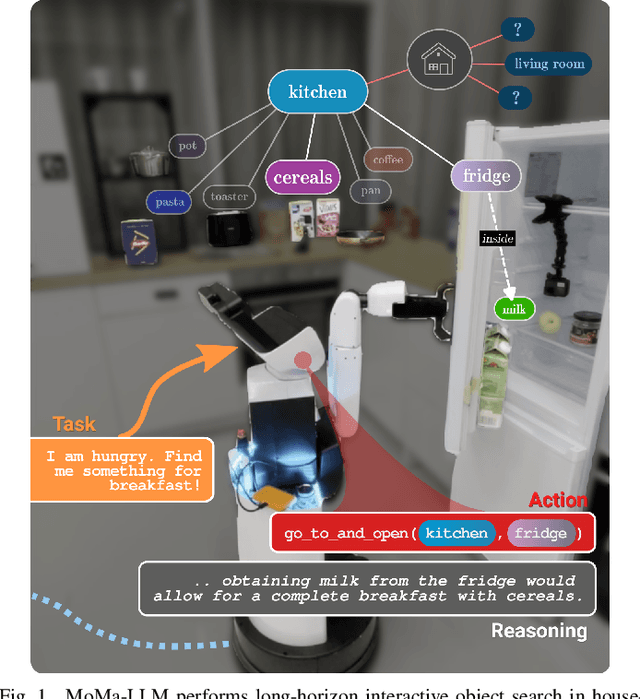
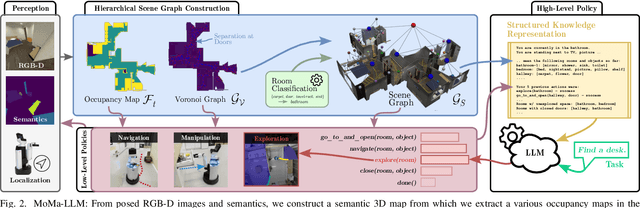


To fully leverage the capabilities of mobile manipulation robots, it is imperative that they are able to autonomously execute long-horizon tasks in large unexplored environments. While large language models (LLMs) have shown emergent reasoning skills on arbitrary tasks, existing work primarily concentrates on explored environments, typically focusing on either navigation or manipulation tasks in isolation. In this work, we propose MoMa-LLM, a novel approach that grounds language models within structured representations derived from open-vocabulary scene graphs, dynamically updated as the environment is explored. We tightly interleave these representations with an object-centric action space. The resulting approach is zero-shot, open-vocabulary, and readily extendable to a spectrum of mobile manipulation and household robotic tasks. We demonstrate the effectiveness of MoMa-LLM in a novel semantic interactive search task in large realistic indoor environments. In extensive experiments in both simulation and the real world, we show substantially improved search efficiency compared to conventional baselines and state-of-the-art approaches, as well as its applicability to more abstract tasks. We make the code publicly available at http://moma-llm.cs.uni-freiburg.de.